11 DevOps Maturity Assessment Questions to Ask During the Audit
- April 02
- 6 min



Responsible AI Engineering is the disciplined practice of using AI to speed up software development while making sure systems meet production standards for safety, reliability, security, observability, and maintainability. It recognizes that production readiness is a property of the whole system, not just the code an AI generates. Human engineers stay accountable for architecture, risk management, quality gates, and operational resilience.
Artificial intelligence accelerates software development, but it does not automatically generate production-ready systems.
The integration of AI into software development has changed how we write code, shifting the focus from syntax generation to complex risk management. This creates a challenge for software developers: how do you balance the speed of AI-generated code with the strict demands of enterprise reliability? This article explores the concept of responsible engineering, redefining what “production-ready” means, and provides actionable frameworks to ensure your AI-assisted systems can safely handle real-world operational stress.
Key Takeaways
When discussing AI in software development, the most common question asked is whether a specific tool can generate “production-ready” code. The answer requires a look at how we define software quality. Production readiness is not a feature of the code itself; it is a measurable state of the entire system.
A new MIT study of more than 100,000 GitHub developers finds that successive generations of AI coding tools can boost coding activity by as much as 180%, yet that surge collapses to roughly 50% for completed projects and just 30% for released software. The pattern makes the governance case plain: production readiness is a property of the whole system, so turning accelerated output into shipped, reliable software still depends on system-level safeguards, observability, and accountable human oversight.
Demirer, Mert and Musolff, Leon and Yang, Liyuan, Writing Code vs. Shipping Code: Productivity Effects Across Generations of AI Coding Tools (May 2026). NBER Working Paper No. w35275, Available at SSRN: https://ssrn.com/abstract=6859839
Traditionally, developers might consider an increment complete if the code compiles, passes local unit tests, and fulfills the immediate business requirement. Today, this binary perspective is dangerously inadequate. Code that simply “works locally” or achieves high line coverage in a testing suite is not inherently ready for the pressures of a live environment.
There is a gap between “code production-ready” and “system production-ready.” Code readiness means the logic is readable, testable, secure, and free of hidden shortcuts. System readiness, however, demands that the code exists within an architecture capable of safe deployment, rollback, observability, and incident response.

An AI agent might easily scaffold a functional API endpoint, but it rarely understands the historical architectural decisions or organizational ownership models required to maintain that endpoint over time.
True production readiness means an increment can be safely deployed, run under real traffic, observed, debugged, scaled, secured, and maintained at an acceptable level of risk. This shifts the engineering conversation from “how to implement a feature” to “how to manage risk.”
To understand this distinction, we must evaluate software across several operational dimensions:
|
Capability |
Code Production-Ready |
System Production-Ready |
|
Testing |
Passes unit tests and edge cases locally. |
Integrates with mutation testing and continuous integration pipelines. |
|
Failure Handling |
Uses standard try-catch blocks. |
Implements distributed tracing, circuit breakers, and bounded queues. |
|
Deployment |
Can be compiled and executed. |
Supports dark launches, automated canary analysis, and instant rollbacks. |
|
Compliance |
Avoids hardcoded secrets. |
Adheres to strict regulations like GDPR, CCPA, SOX, and PCI DSS. |
Managing risk remains the core tenet of production readiness. The acceptable risk threshold depends entirely on system criticality.
Quality gates and error budgets quantify acceptable risk, transforming system stability into a measurable mathematical metric rather than a subjective feeling. Frameworks like BMAD provide vital upstream governance for requirements, architecture, and readiness checks before a single line of AI code is accepted.
According to Google SRE (2026), an Error Budget represents the allowable threshold for failures, derived from the Service Level Objective (SLO). If a new AI-generated feature consumes the error budget, feature deployment halts entirely. This mathematical approach removes politics from deployment decisions, prioritizing reliability over the rapid release of new features.
Large language models excel at scaffolding, generating happy-path tests, refactoring, and handling boilerplate code. However, they struggle with non-functional requirements and production constraints that are not explicitly provided in their context window.
AI does not automatically deliver production-ready code. Instead, it acts as a strong accelerator, speeding up the process of reaching code that can become production-ready through proper human oversight and quality gates.
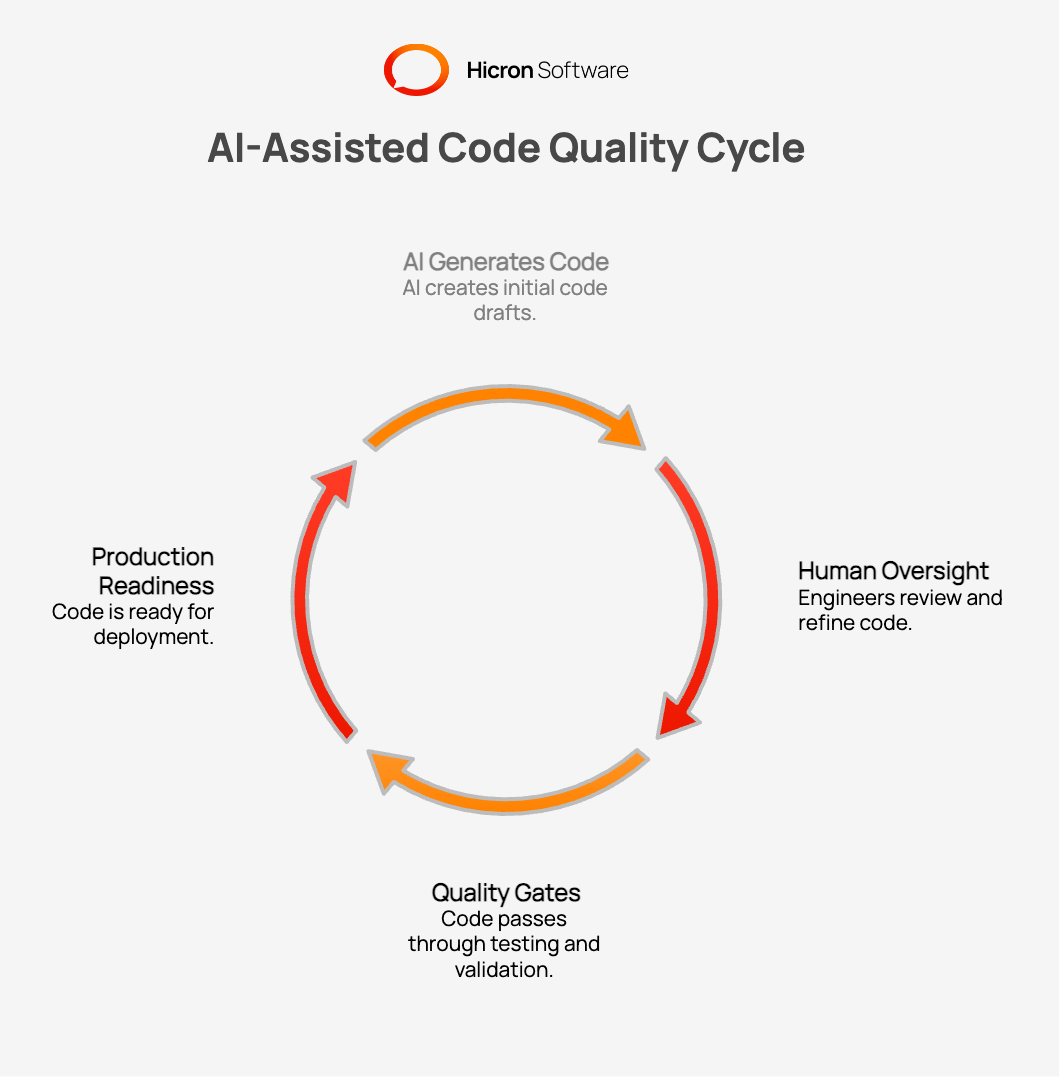
One of the biggest mistakes in AI-assisted engineering is relying solely on code coverage as proof of correctness. Test coverage metrics often create a false sense of security. An AI model might generate tests that look professional but merely confirm its own flawed assumptions. Responsible engineering requires rigorous testing signals. Techniques like mutation testing, where defects are intentionally injected to see if tests catch them, can validate that our assertions detect regressions and edge cases.
The critical question is no longer “Does AI write good code?” but rather, “How does the definition of good engineering change when AI agents write the code?”
Agentic engineering forces senior developers to shift from writing individual lines of code to acting as context designers. Because AI models generate output based solely on the context window, senior engineers should carefully design the quality gates, test parameters, and decision processes that guide the AI.
Long AI sessions often suffer from “context rot,” where the model loses track of early architectural constraints. It is the role of the senior developer to manage this by resetting context, enforcing strict review cycles, and verifying that the generated tests catch actual edge cases rather than merely confirming the AI’s own flawed assumptions.
The most severe pitfall of AI-assisted engineering is mistaking local functionality for production readiness. An AI agent might generate a microservice that successfully fetches data on a developer’s laptop but catastrophically fails under concurrent network requests.
Another major pitfall is relying on simple code coverage. High code coverage metrics can mask weak assertions. To combat this, teams should implement rigorous testing signals like mutation testing, which actively injects defects into the code to verify that the test suite actually catches failures. Developers should practice defensive programming, ensuring rigorous data validation and explicit failure semantics for every AI-generated function.
Operationalizing responsible AI engineering requires embedding strict infrastructure policies, deployment reviews, and observability standards directly into the development workflow. Enforcing these practices ensures AI agents operate within safe, predictable boundaries.
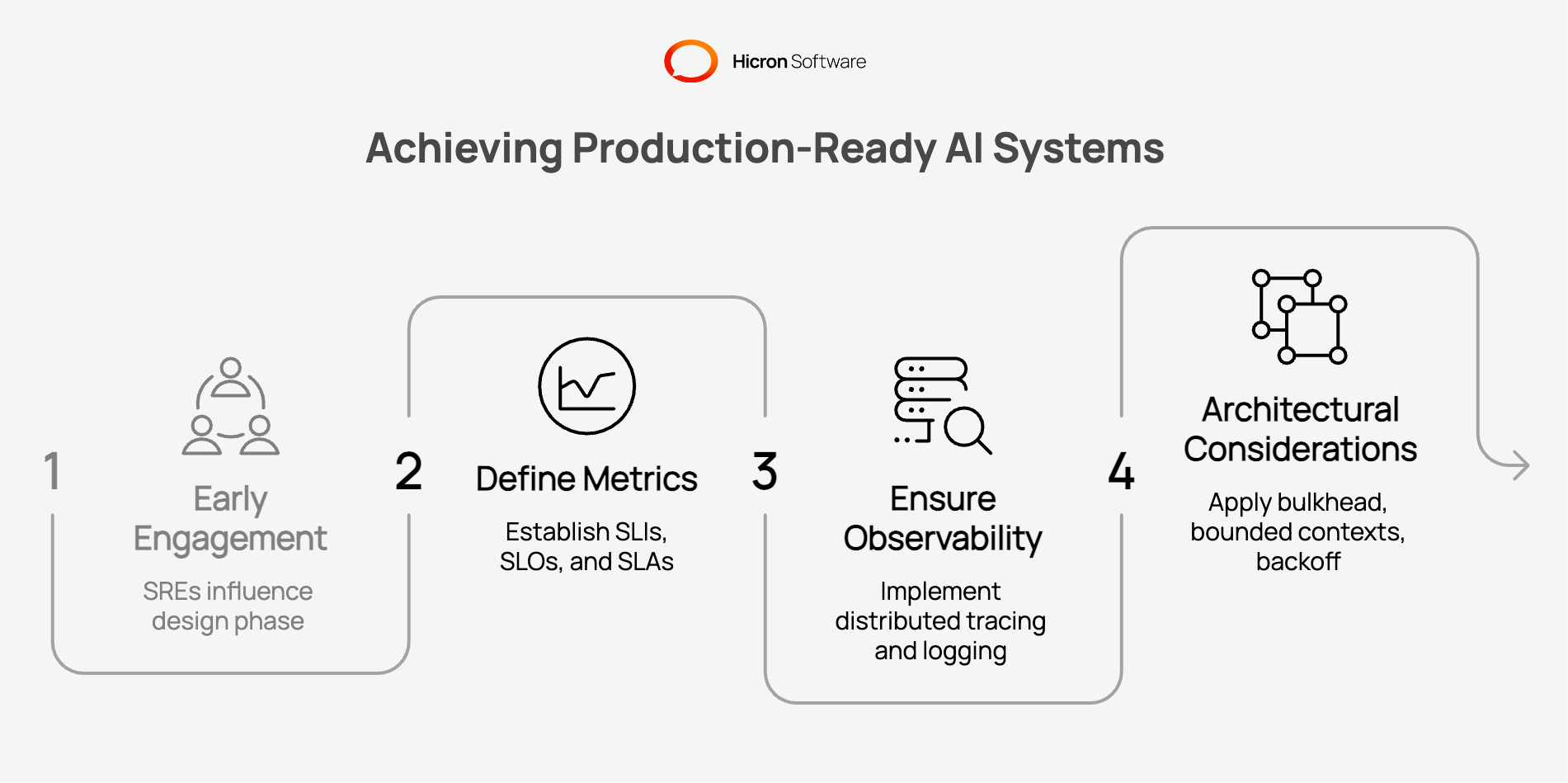
The Production Readiness Review (PRR) process rigorously evaluates error propagation, network quality, and configuration standards before code reaches a live environment. According to Google SRE (2026), this process ensures that new services will not destabilize the existing ecosystem.
Modern PRR relies on early engagement models. Site Reliability Engineers (SREs) influence the architecture during the design phase rather than acting as a final gatekeeper. By establishing PRR criteria early, teams can guide AI agents to generate code that naturally aligns with the organization’s deployment and security standards.
Service Level Indicators (SLIs), Service Level Objectives (SLOs), and Service Level Agreements (SLAs) are metrics used to categorize risk in AI architecture.
Even with flawless AI-generated code, systems must be entirely observable. Without distributed tracing and structured logging, diagnosing an issue within a complex AI-integrated microservice architecture becomes impossible.
AI integrations require strict modularity, analyzability, and modifiability to isolate partial failures and maintain operational control. Structural quality demands that components can be changed with minimal impact on the broader system.
When integrating AI outputs, teams must design systems to handle partial failures while maintaining operational control. This involves implementing specific architectural safeguards:
AI cannot assume this architectural responsibility. Human engineers must establish these boundaries to contain the blast radius of any potential defect.
The rapid advancement of AI tools forces us to reimagine engineering. AI agents write thousands of lines of code in seconds. The true value of an engineer lies in managing risk. Engineers define strict quality standards and enforce operational resilience.
Building production-ready systems remains a complex sociotechnical challenge. We integrate AI to accelerate development and provide intelligent risk assessments. We never compromise on financial integrity, compliance excellence, or enterprise security.
Embracing the potential of AI requires a highly disciplined approach. Avoid confusing a successful local test with a maintainable production system. Focus on robust architecture, strict observability, and comprehensive quality gates. We can utilize the speed of AI while upholding engineering excellence.
Sources:
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
