How RAG Architecture Changed: From PDF Chatbots to Context Engineering
- July 03
- 14 min



The Production Control Stack is a framework for making AI-generated code safe to ship by combining three layers: checklists before generation, tests before deployment, and observability after release. It exists because AI can generate code quickly, but it often overlooks important production aspects like rollback plans, monitoring, edge cases, and operational ownership. In short, it helps engineering teams control delivery risk, not just code output.
The constraint in software delivery has shifted. Writing code no longer takes the most time. Controlling what enters production does. AI agents now generate feature implementations at speed no human team can match line by line. This creates a new category of delivery risk, one that has nothing to do with whether code compiles and everything to do with whether a system stays operable after it ships. The Production Control Stack addresses this gap directly, using three interlocking layers: checklists, tests, and observability.
Key Takeaways
For decades, the quality of software was closely linked to the developer who wrote the code. A senior engineer understood which edge cases to address, which security checks to implement, and what details were important for logging. The natural limitations of human typing speed capped the output volume, ensuring that quality was tied to the author of the code.
That model no longer holds. AI agents generate implementations and tests at a pace that outstrips manual review entirely. A change that previously took a full day now arrives in an hour. Pipelines fill far faster than teams can absorb the associated risk. The engineering role has shifted accordingly. Teams now focus on quality system design rather than line-by-line authorship.
The focus has shifted from whether generated code compiles to whether the system remains functional after the code is deployed in production.
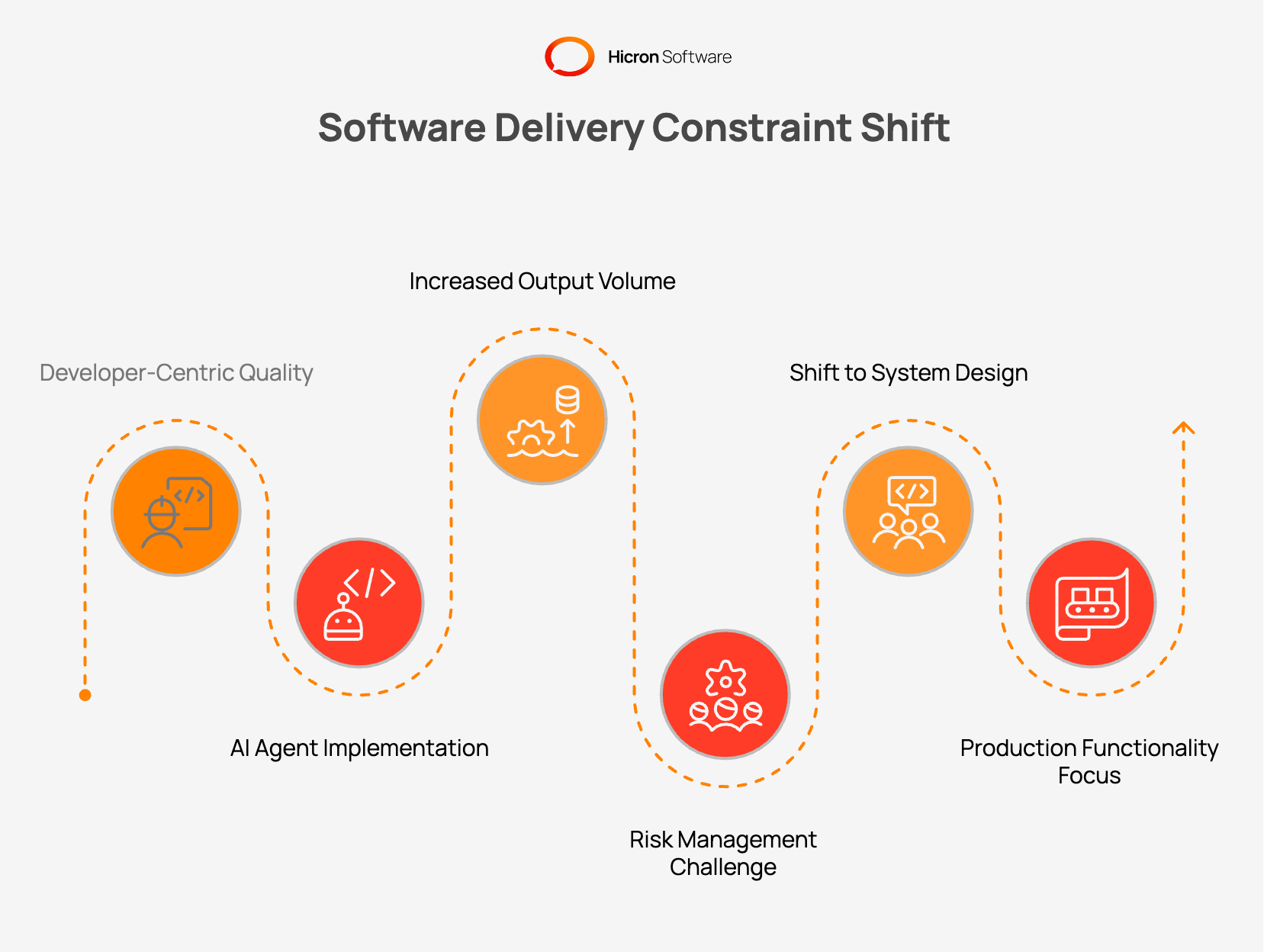
AI agents lack operational awareness. They fulfill tasks exactly as defined in the prompt. An agent assigned a straightforward task delivers a simple solution. It consistently manages the expected scenarios but overlooks complex edge cases that were not mentioned in the initial instructions. It disregards correlation IDs, rollback plans, and rate limiters unless specifically asked to include them.
A gap has always existed between local code and production-ready systems. Agents enhance the speed and scope of bridging that gap. This issue is not a failure of capability, but rather a failure of context. Agents operate solely within the context they are given. The quality of that context shapes the final output.
The Production Control Stack is a three-layer quality system built specifically for the era of AI-generated code. Each layer operates at a distinct moment in the delivery cycle and catches a different category of failure.
|
Layer |
When It Operates |
What It Catches |
|
Checklists |
Design time, before generation |
Completeness gaps and missing criteria |
|
Tests |
Build time, before deployment |
Behavioral regressions and functional errors |
|
Observability |
Runtime, after deployment |
Operational failures in live production |
Production readiness requires all three layers working together. Removing any one layer creates an uncontrolled window of risk.
Checklists prevent critical completeness gaps from reaching the codebase. A team using a fast agent sees a steady stream of pull requests. Each one looks reasonable at first glance. Each one might be missing something the initial prompt never mentioned.
A production readiness checklist forces the right questions before code review begins. Has proper input validation been implemented? Are error paths handled across the application? Is there a rollback plan for database migrations? Are operational logs free of sensitive user data? Does anyone own this feature after it ships?
These questions are invisible to a coding agent. They are obvious to an experienced engineering team.
The checklist also acts as a strong prompt input. Feeding readiness criteria to the agent before generation produces far better output. A minimal definition of done covers nine areas:
This entire list fits inside a single pull request template.
The checklist does not need to be exhaustive to be effective. It needs to cover the failure modes that agents consistently miss. These include authorization checks (not just authentication), structured logging free of sensitive data, rollback procedures for schema migrations, and explicit feature ownership before the code ships.
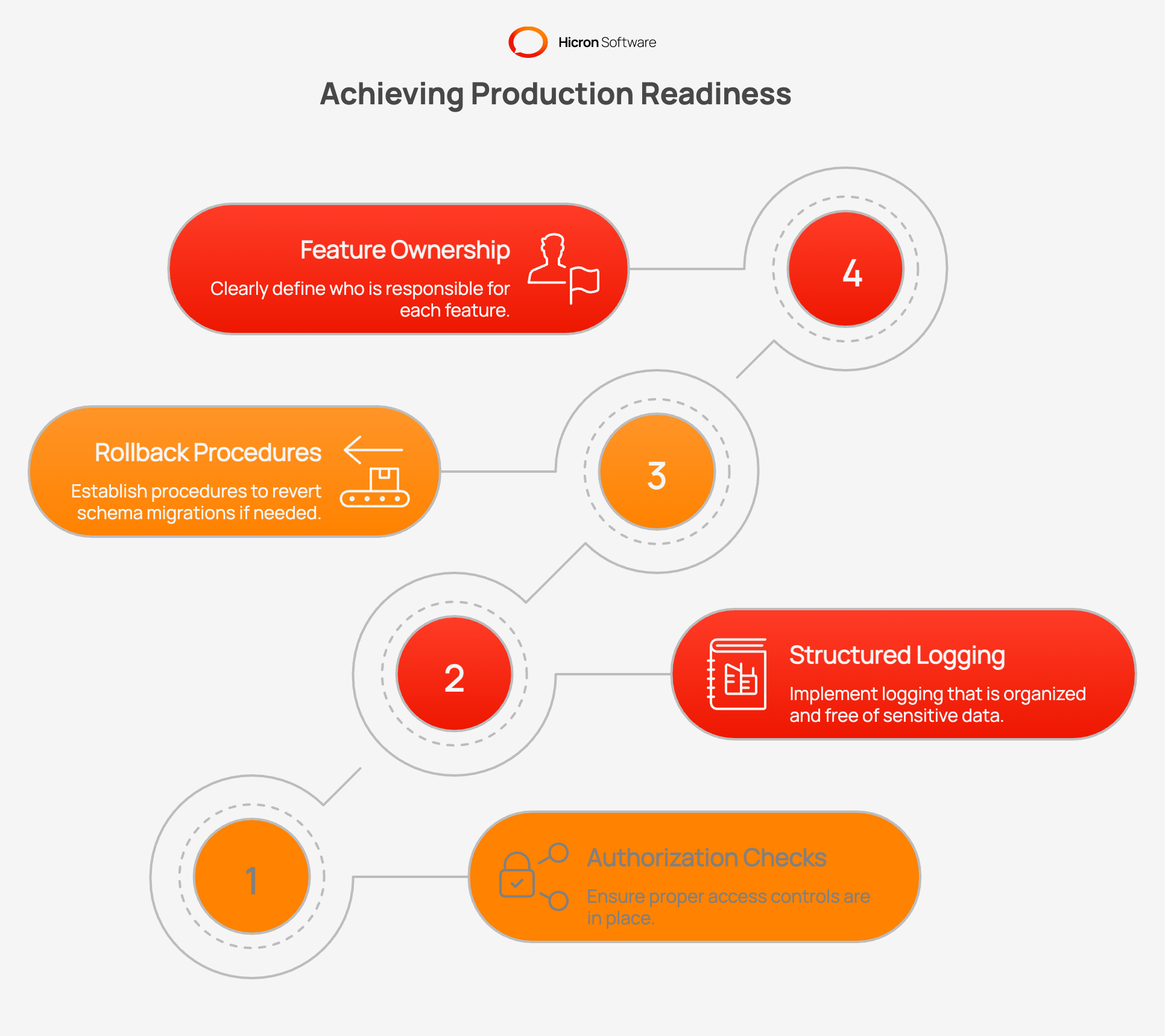
Teams that add this checklist to their pull request template before adopting fast agents report fewer production incidents tied to omitted operational requirements.
Code coverage provides no proof of functional correctness. It proves that specific lines executed during testing. A test suite with high coverage can still miss regressions entirely. Assertions may be so weak that broken implementations still pass.
AI agents introduce a specific version of this problem. An agent writing both the implementation and the tests confirms its own assumptions. Tests pass because they verify what the agent expected, not what production will actually encounter. Generated test suites look professional but often provide weak protection.
Mutation testing asks whether tests can detect distinct behavioral changes in the code. A surviving mutant means a test missed a real defect. Mature teams run mutation analysis on critical business logic as an asynchronous step in their pipeline.
The scenarios that matter most are the ones difficult to anticipate quickly: missing permissions, external dependencies that time out, duplicate submissions, malformed inputs, large data volumes, and unexpected API contract changes.

Prompt quality directly affects test quality. Asking an agent to add tests produces basic coverage. Asking for tests that verify invalid input handling and dependency timeouts produces signal. Defining specific operational risks in the prompt raises test quality substantially.
Unit tests verify isolated logic and form the first line of defense. Integration tests confirm that components connect correctly, catching failures at the boundaries between services. End-to-end tests validate full user journeys, ensuring the system behaves correctly from the user’s perspective.
All three layers matter. Agents tend to write unit tests because the prompt usually asks for them. Integration and end-to-end coverage requires explicit instruction. Teams that define these requirements as part of their definition of done get significantly stronger test suites from their agents.
A system without observability is not ready for production. Tests run before deployment. Observability runs after. These are not interchangeable functions.
Observability answers questions tests cannot. Does the feature work for real users? Is the error rate within the historical baseline? Is latency degrading over time? Is an external dependency causing silent failures?
Google defines four golden signals as the minimum required instrumentation: latency, traffic, errors, and saturation. A feature without this coverage cannot be operated safely at scale.
Agents writing business logic routinely omit the operational layer. The endpoint gets built. The logic works. The correlation ID for distributed tracing is missing. Structured log fields do not exist. The metric for the critical path operation is absent. Alert thresholds for failure conditions were never created.
This is a context failure, not a capability one. Observability needs to appear in the definition of done. Follow-up tasks in fast agentic workflows rarely happen. The checklist layer is the mechanism that prevents this omission before generation begins.
Services that propagate trace context allow teams to follow a single request across the entire system. Services that fail to propagate this context create observability dead zones where incidents go unresolved for hours.
Logging captures discrete events and provides the detail needed for incident investigation. Metrics aggregate system state over time and support trend analysis. Alerting converts metric thresholds into proactive notifications before users report failures.
Each layer serves a distinct diagnostic purpose. Together they give engineering teams the visibility needed to detect, understand, and resolve production failures quickly.
These three layers do not function as independent checks. They interlock across time to provide full coverage.
Consider a payment processing feature. The checklist flags the need for an idempotency key. The agent implements this correctly before deployment. Tests verify that duplicate requests return the correct response. Observability confirms that payment error rates remain stable after the feature goes live.
Each layer catches what the previous layer missed. Checklists operate at design time. Tests operate at build time. Observability operates at runtime. Removing any layer creates a gap that the remaining two cannot close.
Teams adopting the Production Control Stack follow a structured workflow:
The most consequential shift in this workflow is moving quality input before generation. Most teams treat code review as the final gate. The Production Control Stack moves quality input to the beginning.
Structured AI development frameworks improve the process. They enforce planning and context management. They raise the probability of functional output. They cannot guarantee production readiness on their own.
A framework can produce excellent architecture without integration tests. It can deliver verified implementations without observability coverage. The framework organizes the work. The Production Control Stack verifies whether the work is safe.
The role of senior engineers is evolving. Code authorship has become inexpensive. Sound judgment is now a scarce resource.
Senior engineers spend less time writing lines of code. They spend more time designing the context that produces good lines. They define constraints that prevent bad output. They build quality gates that keep the delivery pipeline safe.
The teams that operate with confidence build these layers early. The teams that skip them generate faster but debug longer.
Start with the definition of done (DoD). Write a minimal checklist covering the nine areas above and add it directly to the pull request template. Require tests that cover specific error paths and edge cases. Include an observability section in every pull request description. Assign an explicit owner before any feature ships.
Consistent criteria produce more value than heavy process frameworks. The Production Control Stack does not slow delivery down. It removes the uncontrolled risk that makes fast delivery dangerous.
AI functions best within a strong quality system designed by the engineering team. The agent doesn’t own what they build; a team member does. Building that ownership into the process is what responsible agentic engineering looks like.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
