How RAG Architecture Changed: From PDF Chatbots to Context Engineering
- July 03
- 14 min



The AI code-production gap is the difference between AI-generated code and code that is truly safe for production. An AI can write a function that compiles and passes tests, but it might lack the authorization checks, input validation, timeouts, observability, and rollback paths that real-world systems require. To close this gap, we should treat “production-ready” as a risk decision, making intent, constraints, and operational context explicit, instead of assuming that working code is safe to deploy.
AI can write code quickly, but writing code was never the hard part of software engineering. The hard part is running software in production, where real users, real data, and real failures meet your system. This guide explains why AI-generated code often misses production context, what risks the AI production gap poses, and how engineering teams can close it. It covers the production context stack, the difference between code-ready and system-ready work, the role human engineers play in safe deployment, and answers why AI-generated code fails in production.
Key Takeaways
The AI code-production gap is the distance between code that compiles and code that runs safely in production. An AI agent can generate an endpoint that passes unit tests, yet still create real operational risk.
That same endpoint may lack resource-level authorization. It may accept unsafe input without validation. It may call a slow dependency without a timeout. It may retry an operation that creates duplicate payments. It may log private data. It may produce no metric showing whether users fail after release. AI-generated code can be correct in a narrow frame and still be risky in production.
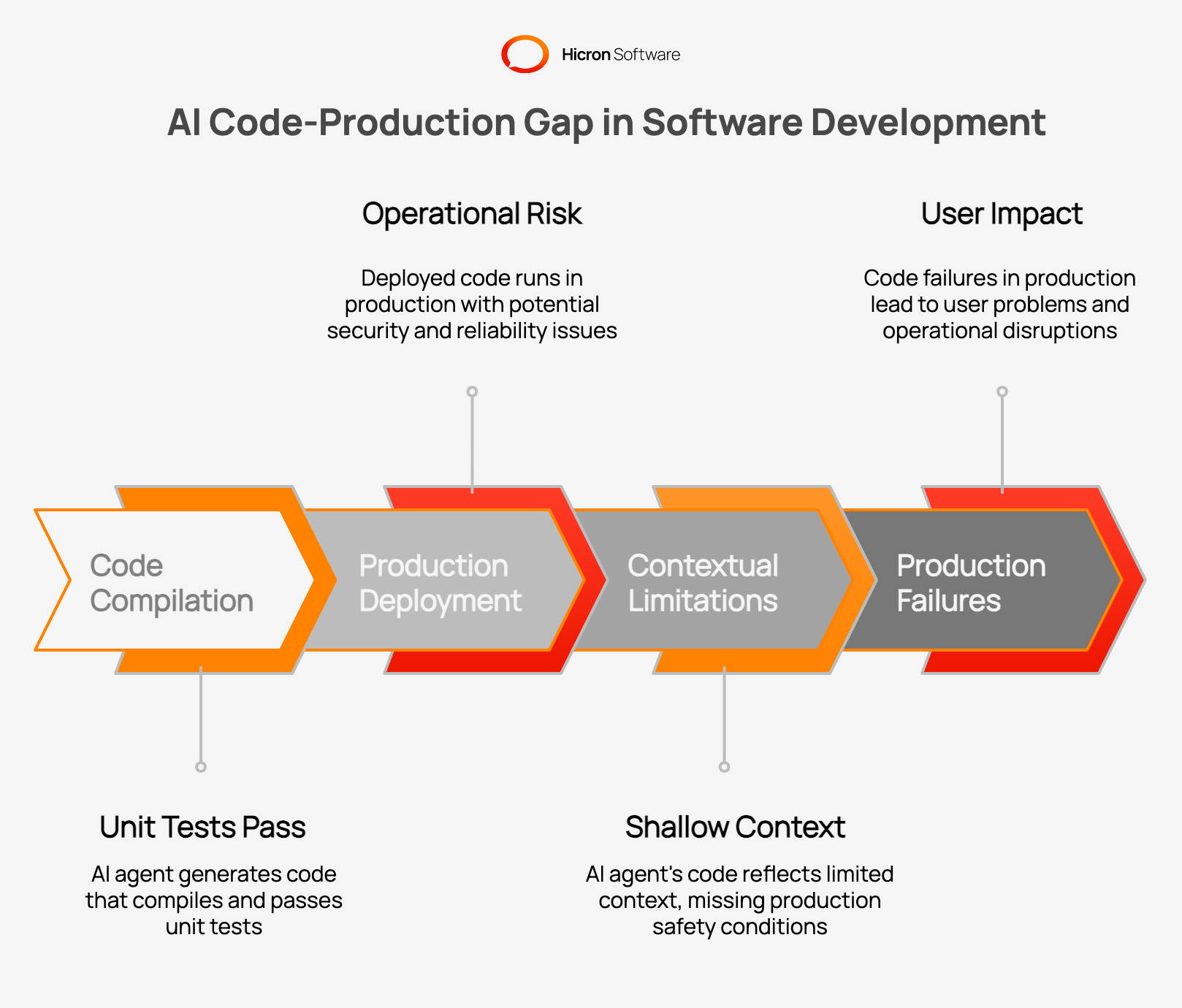
AI models generate code that reflects the context they receive. When that context is shallow, the result looks complete while quietly missing the conditions that make software safe to run.
A new MIT study of more than 100,000 GitHub developers finds that successive generations of AI coding tools can lift coding activity by as much as 180%, yet those gains fall to roughly 50% for completed projects and just 30% for released software. The drop-off reflects a familiar engineering reality: production context, risk controls, and human bottlenecks along the delivery chain still decide how much AI-generated code actually ships and reaches users.
(Demirer, Mert and Musolff, Leon and Yang, Liyuan, Writing Code vs. Shipping Code: Productivity Effects Across Generations of AI Coding Tools (May 2026). NBER Working Paper No. w35275, Available at SSRN: https://ssrn.com/abstract=6859839)
AI code misses production context because much of that context never lives in any repository. Large language models work from prompts, files, examples, instructions, tools, and feedback loops. That is strong, but it is limited.
Many production constraints live in team habits, past incidents, and architecture decisions made years ago. They live in security policies, customer contracts, and the judgment of senior engineers who watched systems break.
When those constraints stay implicit, a model treats them as absent. This is a context failure more than a model failure.
Consider a few examples of knowledge an AI agent inherits by default:
For your team, some of this feels obvious. For an AI agent, implicit always means invisible.
Teams that want production-grade AI delivery need a clear model for how production knowledge flows into AI-assisted work. The Production Context Stack provides that. It has five layers, from the ground up.
|
Layer |
What it covers |
Why it matters |
|
Intent (base) |
Business goal, user flow, acceptance criteria, reason for the change |
Without clear intent, the model optimizes for whatever it can infer |
|
Constraints |
Architecture rules, security policy, data rules, performance and cost limits |
Defines what the implementation cannot do |
|
Verification |
Tests, code reviews, static analysis, contract and migration checks |
Produces a trustworthy signal before release |
|
Operation |
Logs, metrics, traces, alerts, dashboards, runbooks, rollback plans |
A feature without observable behavior cannot be debugged |
|
Accountability (top) |
Risk acceptance, service ownership, incident response |
Someone decides whether remaining risk is acceptable |
This stack turns an AI coding agent from a code generator into a participant in an engineering system. Without it, the agent operates on shallow context, which produces shallow guarantees.
AI often overlooks context that does not appear in the codebase. This hidden context usually spans six categories.
These details decide whether the generated code is safe to operate.
The biggest risks of AI-generated code involve security, error handling, data privacy, and observability. Each one stays hidden until the code meets real traffic.
AI code can skip resource-level authorization, letting one user reach another user’s data. It can accept input without validation, opening the door to injection attacks. It can also call external dependencies without timeouts, so one slow service stalls the whole request path.
Retry logic is a common trap. A naive retry loop can repeat an operation that was never safe to repeat. In a payment flow, that means duplicate charges. Production code needs idempotency keys and clear failure behavior, not optimistic retries.
AI agents often log generously to help with debugging. That habit becomes a liability when logs capture personal data, tokens, or payment details. Data retention rules and privacy laws turn careless logging into a compliance problem.
A feature without metrics is a feature you cannot debug. AI-generated code frequently ships with no signal showing whether users succeed or fail after release. Without that visibility, teams learn about failures from angry customers instead of dashboards.
Read more on this topic: What Is the Production Control Stack and Why Does AI-Generated Code Need It?
“Production-ready” means an increment can be deployed, operated, observed, debugged, scaled, secured, rolled back, and maintained at an accepted level of risk. It does not mean the code runs once in a pipeline.
That definition moves the conversation from implementation to engineering governance. Readiness is always a function of criticality. A small internal experiment does not need the rigor of a payment service. A back-office tool does not need the review path of a medical system. A batch job with a recovery window of hours carries less risk than a customer-facing API with strict latency targets.
Service level indicators, service level objectives, recovery targets, rollback plans, and ownership models make risk visible. They turn a vague “good enough” into a concrete engineering decision. Without that decision, “production-ready” becomes a feeling, and feelings do not operate systems.
Production-ready code and a production-ready system are related, but not the same.
Production-ready code reads well within the existing codebase. It follows local architecture patterns, handles expected errors cleanly, and keeps side effects clear. It avoids hidden shortcuts, hardcoded values, and brittle assumptions.
A production-ready system goes further. It includes deployment pipelines, rollback procedures, observability layers, and alerting rules. It also covers security controls, backup strategies, data migration paths, and capacity planning. Solid code can sit inside a system that is not ready at all. An endpoint can be well written and still lack metrics. A migration can be clean and still lock a large table.

Engineering teams close the gap by making production knowledge explicit before asking for code. Better prompting alone does not fix the problem. Structure does.
AI generates tests quickly, which is genuinely useful. It also creates a quality trap. A model can produce tests that confirm its own assumptions, cover the happy path, and mock away the real integration contract. They look professional while saying little about production risk.
Production-grade tests cover behavior. They catch edge cases, authorization failures, dependency errors, data conflicts, idempotency issues, and regressions in critical flows. The speed of AI adds value, while engineering judgment provides signal. Both aspects are important, and neither one replaces the other.
Human engineers own the release decision and the production knowledge that AI depends on. Agentic coding is changing daily work, shifting the senior role from writing every line toward designing context, constraints, review gates, and risk decisions.
The change does not diminish the importance of engineering fundamentals; instead, it highlights them even more. Weak engineering gets faster with AI assistance, and strong engineering does too. The difference is the presence or absence of structure.
Human oversight matters most in three places:
Frameworks like BMAD and GSD create structure around AI work. They help define requirements, architecture, stories, validation plans, review steps, and execution loops. A framework reduces how much the model has to guess, but no framework accepts production risk for you.
AI-generated software can reach production readiness. It does not get there simply because a model wrote it. It gets there when intent is clear, constraints are explicit, tests carry a real signal, and failure behavior is designed. It gets there when observability exists, rollback is planned, and ownership is assigned before release.
The key question for engineering teams is no longer whether AI can write code. The better question is whether your organization can make enough production knowledge explicit for AI to work safely within it. Teams that win will not be the fastest at generating output. They will be the ones that turn engineering judgment into reusable context, clear gates, and accountable release decisions.
Start by auditing your delivery model. Find the layer of the production context stack that stays implicit rather than documented, then make it explicit. Build that structure first, then add more autonomy.
Sources:
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
