11 DevOps Automation Tools to Streamline Your Workflow
- May 21
- 10 min



Spec-to-code, also referred to as Spec-Driven Development (SDD), is an AI-focused software engineering approach defined by GitHub. It uses detailed and structured specifications written in natural language or markdown as the central source of truth. These specifications enable AI agents to automatically generate, test, and maintain production code.
Something quietly fundamental has changed in software development, driven by advancements in AI and engineering practices. AI coding assistants have become fast and capable enough that the bottleneck in building software is specifying precisely what to build, emphasizing the need for clear specifications in the toolkit. That shift has made an old discipline newly urgent: the practice of writing a formal specification before a single line of code is produced.
Spec-to-code, and the broader methodology it sits inside, Spec-Driven Development (SDD), is the answer an increasing number of engineering teams are converging on. This guide explains what it is, why it matters to business owners, product owners, and CTOs, and how to adopt it without throwing your existing processes into chaos.
Key takeaways:
Spec-to-code is a workflow in which a formal specification is treated as the authoritative source of truth. It is a structured description of what a system should do, including its inputs, outputs, error cases, and constraints. Code is then derived from that specification, either by AI agents, code generators, or disciplined human implementation.
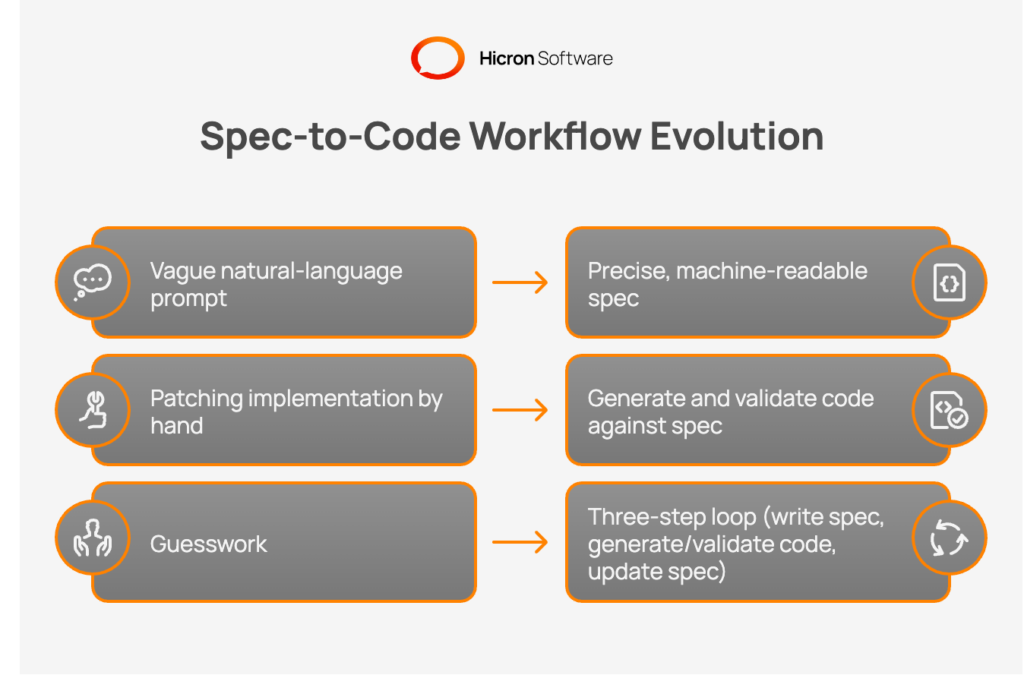
The concept of iterative development is not new. What is new is that AI coding tools have made it dramatically more powerful, enhancing the development workflow. When an agent like GitHub Copilot, Claude Code, or Kiro receives a precise, machine-readable spec rather than a vague natural-language prompt, the quality and reliability of its output increase substantially. The spec gives the agent a bounded context, clear acceptance criteria, and explicit constraints. Exactly what these systems need to behave predictably.
The result is a three-step loop that replaces guesswork: write the spec, generate and validate the code against it, and update the spec when requirements change rather than patching implementation by hand. It is this cycle that defines spec-driven development.
Most software teams already produce some form of specification: a PRD, a Jira epic, a Confluence page. The problem is that these documents are written once, read briefly, and then abandoned. By the time development finishes, the code and the documentation describe two different systems. This is what practitioners call the spec-evergreen problem, and it is nearly universal in open source projects.
SDD directly addresses four failure modes that drain engineering capacity:
Why is AI-generated code making Spec-Driven Development worse? In each case, the root cause is the same: intent was never captured in a form the system could enforce. SDD fixes this by making the spec a living, versioned artifact that is enforced at every stage of development.
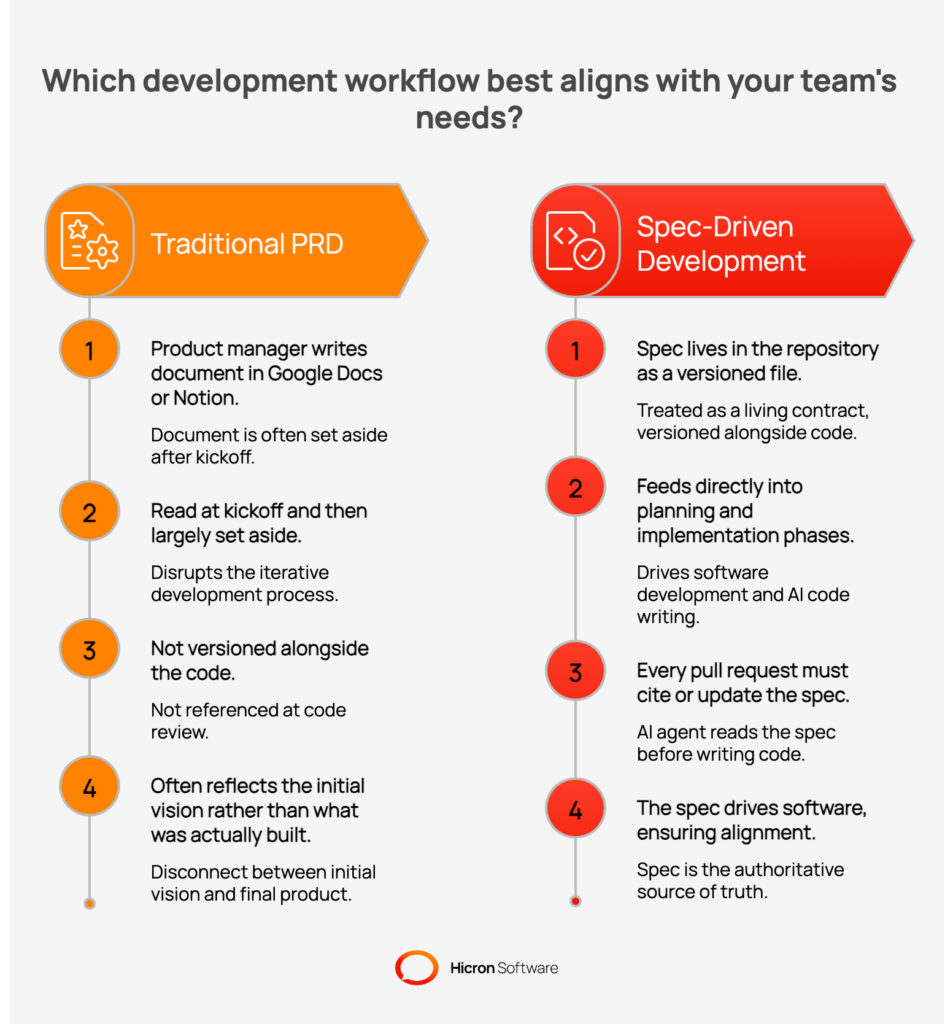
Both approaches involve writing a document before building. The differences, however, are substantial enough to change the entire operational reality of a development team.
In a traditional PRD workflow, a product manager writes a document. Usually, in Google Docs or Notion. This describes goals, features, and acceptance criteria. It is read at kickoff and then largely set aside in favour of tickets and Slack threads, which disrupts the iterative development process. The PRD is not versioned alongside the code, not referenced at code review, and often reflects the initial vision rather than what was actually built.
In SDD, the spec lives in the repository as a versioned file. It is treated as a living contract: every pull request that changes system behaviour must either cite the spec or update it. It feeds directly into the planning and implementation phases, and it is the document an AI agent reads before writing a single line of code. The spec drives software.
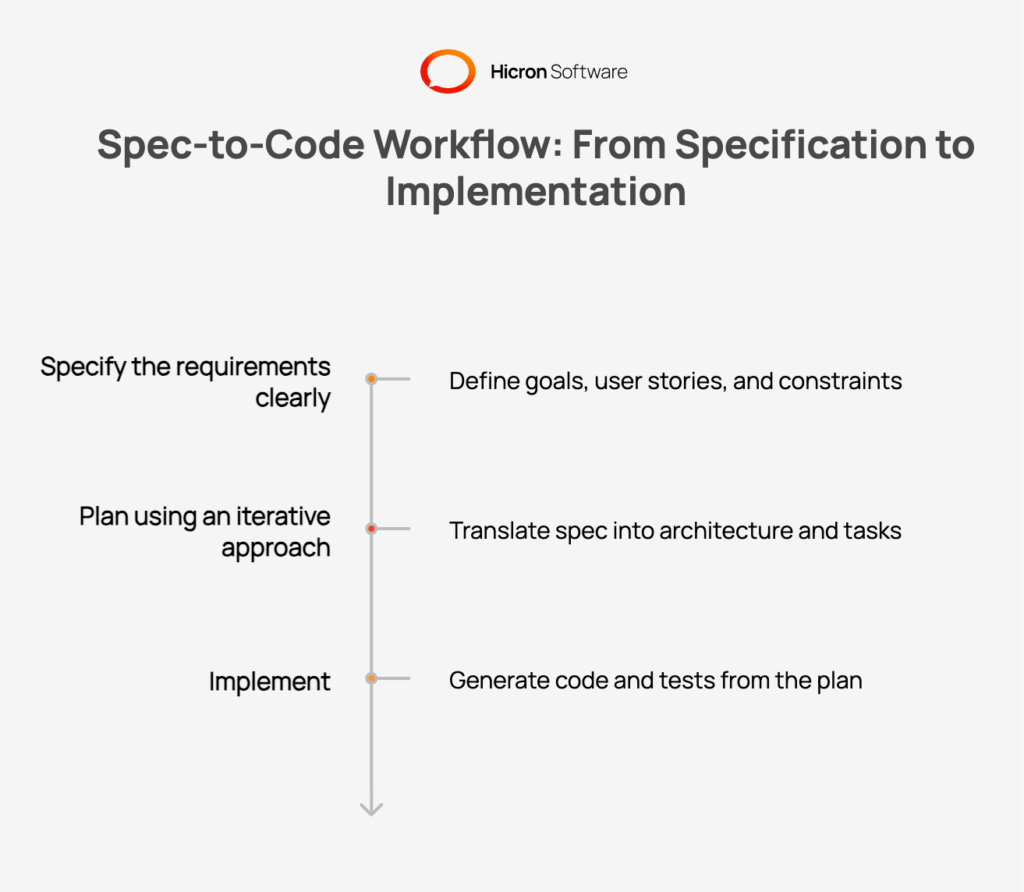
At its core, spec-driven development follows a three-phase loop that will feel familiar to anyone who has practised disciplined engineering, even if the tooling is new.
Specify the requirements clearly to enhance the software engineering toolkit. Write what the system must do. This means defining the goal, user stories, success criteria, constraints, and explicit non-goals. The spec should be precise enough that someone unfamiliar with the project can understand what done looks like. This way, an AI agent can implement it without ambiguity.
Plan using an iterative approach to improve productivity. Translate the spec into architecture, modules, and tasks using a toolkit designed for software engineers. This is where technical decisions are made:
Tools like GitHub’s Spec Kit can generate a plan.md and supporting architecture artefacts automatically from the spec, which teams then review and refine.
Implement. Generate code and tests from the plan, then validate that the implementation matches the spec. When requirements change, the update flows backwards through the loop: edit the spec, regenerate the plan, re-implement the affected tasks. The spec is always the source of truth.
One of the most important things to understand about SDD is that it is not a purely technical practice. The spec is where business intent is encoded in a form the development system can enforce. This means non-technical leaders have a direct and consequential role. What role do non-technical leaders play?
Product owners define the intent, constraints, and non-goals for each feature. Their sign-off on the spec before any plan or implementation begins is the gate that prevents misaligned code from being written in the first place.
Business owners and CTOs set what Spec Kit calls the constitution. This is a cross-feature document that encodes quality standards, compliance requirements, security non-negotiables, and architectural guardrails. Every spec must be consistent with the constitution, which means business-level decisions made once are automatically enforced across every feature.
In practice, this means leaders should expect to be involved at the Specify phase. The goal is not to write code, but to validate that the spec reflects business reality before the engineering machine runs.
AI agents are only as reliable as the instructions they receive. A prompt like “build a search feature” produces code that is plausible but unpredictable. Missing edge cases, inconsistent with the existing data model, and disconnected from what the business actually needs. A structured spec changes this equation entirely.
When an agent receives a spec with explicit success criteria, defined constraints, and enumerated edge cases, it has a bounded problem to solve, allowing for rapid prototyping. The output can be validated against measurable conditions. Deviations are detectable. The feedback loop becomes: edit the spec, regenerate the code, and validate against the acceptance criteria. A cycle can be automated and repeated reliably, embodying test-driven development principles.
This is why organisations investing seriously in AI-assisted development are finding that the quality of their specs matters more than the choice of AI model. Better specs produce better code, regardless of the underlying tool.
AI-driven development thrives on clarity. Vague specifications lead to unpredictable results, making precise, modular requirements the cornerstone of successful spec-to-code implementation.
The most common objection to spec-driven development is that it sounds like waterfall: write everything up front, then build. This misunderstands how SDD works in practice and the importance of effective engineering practices.
The antidote is a modular backlog organised around thin vertical slices. Each backlog item corresponds to one small, testable, end-to-end behaviour within a single module, not a layer of architecture. Instead of “build the backend API” followed by “build the frontend,” a vertical slice reads: “As a user, I can filter listings by price range,” and it delivers UI, API, data, and tests in one coherent unit.
The iterative approach of modular backlogs transforms AI from an unpredictable architect into a reliable specialist, enabling teams to build robust software one step at a time.
Crucially, full SDD (with the complete specify, plan, implement loop) should be reserved for non-trivial features, new APIs, and cross-module changes. For small fixes and minor UI tweaks, a lightweight approach suffices: a one-paragraph spec in the pull request description is enough to maintain traceability without bureaucratic overhead.
When modules evolve on independent cadences, changes are localised. A billing module spec can be updated without touching the search module’s spec. This is what makes SDD agile: it limits the blast radius of any single change.
Adopting SDD without understanding its failure modes results in a process that is more bureaucratic but no more effective. The most common pitfalls are:
Keeping specs current with a changing product is the hardest operational challenge in SDD, the one most organisations underestimate. A spec that is six months out of date is worse than no spec, because it actively misleads both humans and AI agents.
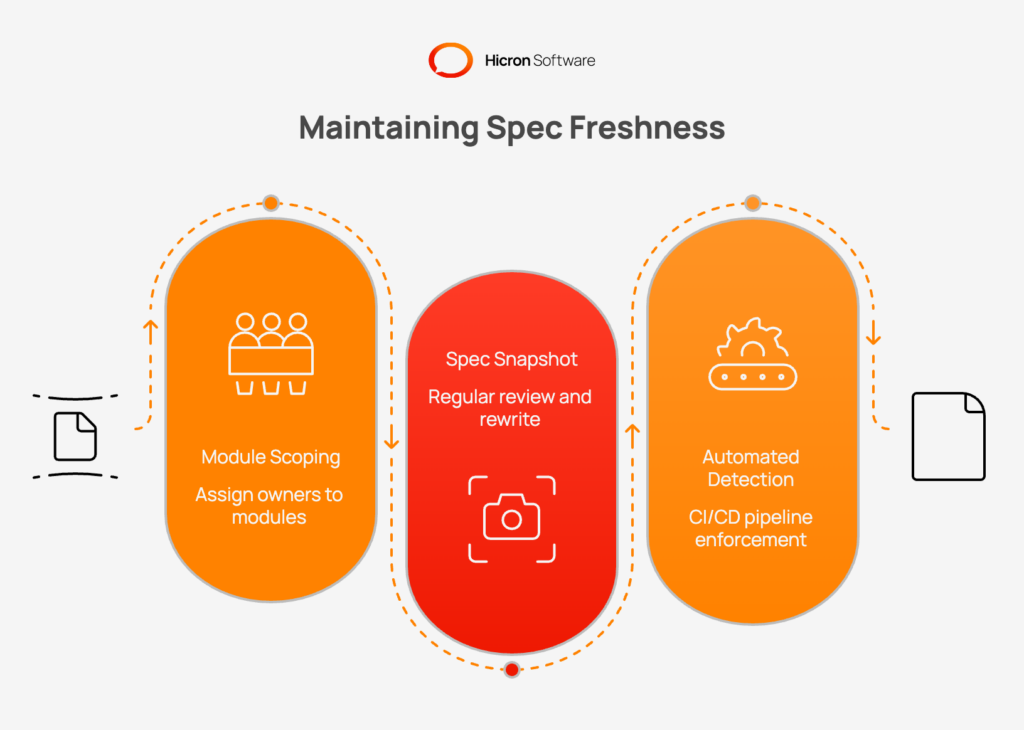
The most effective approach treats specs as live artifacts scoped to individual modules, each with a designated owner responsible for keeping it aligned with actual behaviour. Rather than recording the history of changes, the spec should always describe the current target state of what the module does now, not what it once did. Git history handles the narrative of how it got there.
At regular intervals (quarterly or per major release), teams should run a spec snapshot. A deliberate pass through each module’s current behaviour to rewrite the spec as a clean, consolidated document. This is similar to database compaction: it removes accumulated drift and restores the spec to a single authoritative source.
Automated spec-drift detection in CI/CD pipelines can enforce freshness mechanically: linting checks that fail if a module has no spec, or diff-based tools that compare API contracts against runtime-discovered endpoints and surface discrepancies as code-review items. At that point, spec freshness is a gate rather than an afterthought.
The single most effective entry point is picking one small, self-contained feature and running the complete loop once. Not a pilot programme, not a multi-team transformation: one feature, one team, one iteration.
A practical starting checklist:
Scale deliberately. Extend the methodology to more features, then to more teams, then to cross-module work, but only once the core loop is working reliably at the small scale. SDD compounds in value as it spreads, but it also compounds in complexity if it is adopted faster than the organisation can absorb it.
Ready to Make the Transition?
Spec-driven development is not difficult to understand. However, it is genuinely difficult to implement well inside an organisation that was not designed for it. The tooling choices, the spec templates, the team rituals, the CI/CD integration, the cultural shift from “write a ticket and start coding” to “agree the spec, then build”. Each of these requires guidance from people who have navigated the transition before.
We work with product teams, engineering organisations, and technology leaders to assess SDD readiness, design the right adoption strategy, and guide the implementation from first spec through to scaled deployment. Whether you are exploring whether SDD makes sense for your organisation or already committed to the transition and need experienced hands on deck, we are ready to help.
Get in touch to start a conversation about where your team stands today and what a well-executed move to spec-driven development could look like for you.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
