CloudOps as An Extension of DevOps Services
- October 04
- 24 min


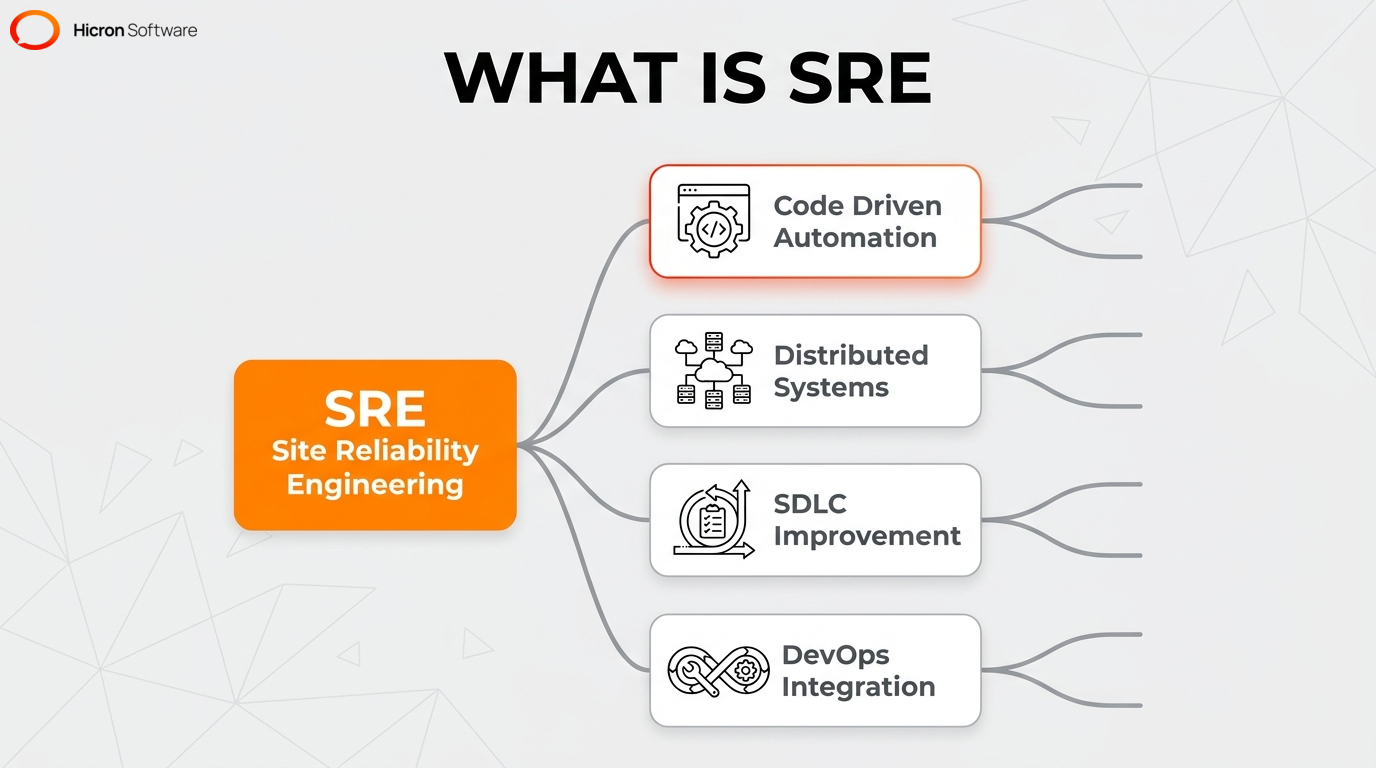
Think of DevOps as the architects designing a high-speed train, and SREs as the engineers laying the tracks and building the automated switching systems to ensure the train never derails. Site reliability engineering (SRE) applies software engineering principles to IT operations. By replacing manual interventions, such as server provisioning, patch management, and log monitoring, with code-driven automation, it ensures high system availability and scalability. SRE unites development and operations by establishing a shared responsibility for uptime.
The discipline focuses on automating manual tasks and managing distributed systems efficiently. You’ll typically see SRE applied to complex environments like:
By applying software engineering techniques to IT infrastructure, SRE automates management and improves the software development lifecycle (SDLC). Integrating reliability metrics directly into the deployment pipeline effectively puts DevOps principles into practice.
|
SRE Category |
Key Components |
Description & Purpose |
|
Core Fundamentals |
|
DevOps is a cultural philosophy, while SRE puts it into practice using concrete metrics and code-driven automation. SREs balance engineering and operational support by capping manual toil at 50 percent to focus on long-term improvements. |
|
Metrics Framework |
|
|
|
Reliability Practices |
|
|
|
Supporting Technologies |
|
|
DevOps is a cultural philosophy that combines development and operations to accelerate the SDLC, and site reliability engineering puts these cultural ideas into practice to build highly reliable systems. In my experience working with infrastructure teams, this overlap is often the most common area of confusion. SRE connects these groups, providing the concrete metrics and automation needed to achieve DevOps goals.
SREs use a mix of automation tools and metric frameworks to balance rapid innovation with system availability. While CI/CD pipelines allow for safe, continuous deployments, SREs govern these processes using core mechanisms like:
A Site Reliability Engineer is an IT professional who uses automation and software engineering to monitor system reliability, fix production issues, and reduce manual operational work. Engineers develop and maintain internal self-service tools and CI/CD pipelines. With toil management as a primary focus, SREs balance their time between engineering improvements and operational support, capping manual toil at 50 percent. Anyone who has spent a weekend manually patching servers knows exactly why this limit is so crucial. Daily responsibilities involve incident response, on-call management, and root cause analysis to resolve system failures.
They also tune performance to improve application speeds and resource use. Technical requirements for site reliability engineering include container orchestration and expertise in scripting languages, such as:
Engineers use configuration management and container orchestration platforms, such as Kubernetes and Docker Swarm, to automate infrastructure management.
To keep systems running smoothly, SREs rely on a specific set of metrics to ensure service quality and balance innovation with reliability. The core SRE metrics framework consists of 4 primary components: service-level agreements (SLAs), service-level objectives (SLOs), service-level indicators (SLIs), and error budgets. These metrics provide an objective measurement of system health and the end-user experience.
SREs use this data to identify specific areas for optimization, such as database queries and network routing, and keep the system running more reliably over time.
Service-level agreements (SLAs) are formal, legally binding contracts between a service provider and a customer. By defining exact service expectations, these documents legally bind providers to specific performance standards and enforce penalties, including service credits and financial refunds, for non-compliance. SLAs focus primarily on business compliance and customer expectations throughout the SDLC.
These contracts reference internal service-level objectives (SLOs) as the technical baseline for acceptable performance, such as system availability, latency, and data throughput. Site reliability engineering (SRE) teams adjust configurations to make sure the systems actually hit those promised targets.
While SLAs face the customer, service-level objectives (SLOs) act as the internal technical targets that make those agreements possible. They set agreed-upon thresholds for service-level indicators (SLIs) to ensure a great user experience. These objectives form the technical foundation that supports the broader business promises made in service-level agreements. Teams monitor specific metrics, such as system availability and latency, to evaluate these targets.
If a standard SLO dictates that a system maintains 99.9 percent uptime over a 30-day period, site reliability engineering (SRE) uses these targets to calculate error budgets. If metric values fall below these internal benchmarks, engineers investigate bottlenecks to maintain system stability.
Service-level indicators (SLIs) are real-time measurements that track the performance metrics SLOs define. These indicators provide the raw data necessary to evaluate system health and determine current SLO compliance. Site reliability engineering relies on this quantitative data for continuous monitoring and observability.
For example, if an SLO targets 99.9 percent system availability, a specific SLI represents the actual measured uptime percentage at any given moment. Other indicators track things like latency, error rates, and data throughput. Engineers intervene to restore stability if these direct measurements drop below target thresholds.
Error budgets mathematically quantify the acceptable level of unreliability. By doing so, they help teams negotiate the trade-off between rapid innovation and system reliability. This calculation derives directly from service-level objectives (SLOs) to establish a precise threshold for non-compliance during the SDLC. An SLO targeting 99.9 percent system availability produces an error budget of exactly 0.1 percent allowable downtime.
If this budget depletes, site reliability engineering (SRE) departments shift their focus entirely to stability rather than new feature development. This is where the rubber meets the road; I’ve seen this single practice completely transform how development and operations teams collaborate. Teams apply strict change management protocols, such as deployment freezes and code rollbacks, and shift computing resources to restore system health.
Site reliability engineering ensures continuous system availability by proactively managing infrastructure, designing self-healing architectures, preventing resource saturation through capacity planning, and preparing for disaster recovery.
SREs focus on keeping distributed systems reliable. Whether it’s a content delivery network or a serverless platform, they ensure it stays up during severe outages like hardware breakdowns or zonal network losses.
Automation eliminates toil by using software tools, such as scripts and intelligent automation platforms, to execute routine infrastructure tasks without human intervention. SRE uses these tools to handle repetitive provisioning and configuration tasks, including server deployments and access allocations. Effective toil management improves productivity and reduces human error, so the goal is to keep it below 50 percent of an engineer’s time.
Teams reserve the remaining hours for long-term engineering improvements. By deploying infrastructure as code and using configuration management, engineers can safely manage capacity as operational demands scale.
Observability and monitoring provide real-time visibility into system health to maintain continuous system availability. To track performance metrics and troubleshoot complex software issues, SREs rely heavily on these practices. Monitoring observes predefined metrics to gauge overall system health and the end-user experience. Observability goes deeper, allowing teams to understand a system’s internal state by analyzing logs, metrics, and traces.
Both methodologies are essential for effective incident response and root cause analysis. SRE teams use monitoring tools to track latency as a critical signal of user experience degradation. If this latency exceeds acceptable thresholds, engineers optimize code to restore optimal speeds. Advanced observability enables engineers to manage highly complex distributed systems.
Capacity planning ensures that a system possesses sufficient computing power to handle current and future demand. SREs use this practice to forecast traffic spikes or business growth, analyzing specific operational variables to scale functions appropriately. Effective infrastructure management guarantees that a platform can absorb a heavy load without degrading the user experience.
Engineers manage server resources to maintain system availability across distributed systems, such as cloud clusters and microservice architectures. Continuous monitoring gives engineers the exact data they need to proactively allocate computing resources like processing power and physical memory. This precise allocation protects system performance and ensures long-term scalability during periods of high demand.
Failover mechanisms and disaster recovery plans protect distributed systems by automatically routing traffic to redundant infrastructure during a hardware or zonal outage. This automation is vital to maintaining continuous system availability if a specific server node fails. Disaster recovery safeguards these networks from catastrophic failures by managing automated backups and using redundancy.
Redundancy duplicates critical components, creating standby servers, secondary databases, and alternative network paths. Site reliability engineering (SRE) ensures these recovery functions operate correctly under duress to protect scalability. If a primary site crashes, engineers use infrastructure automation to restore services immediately.
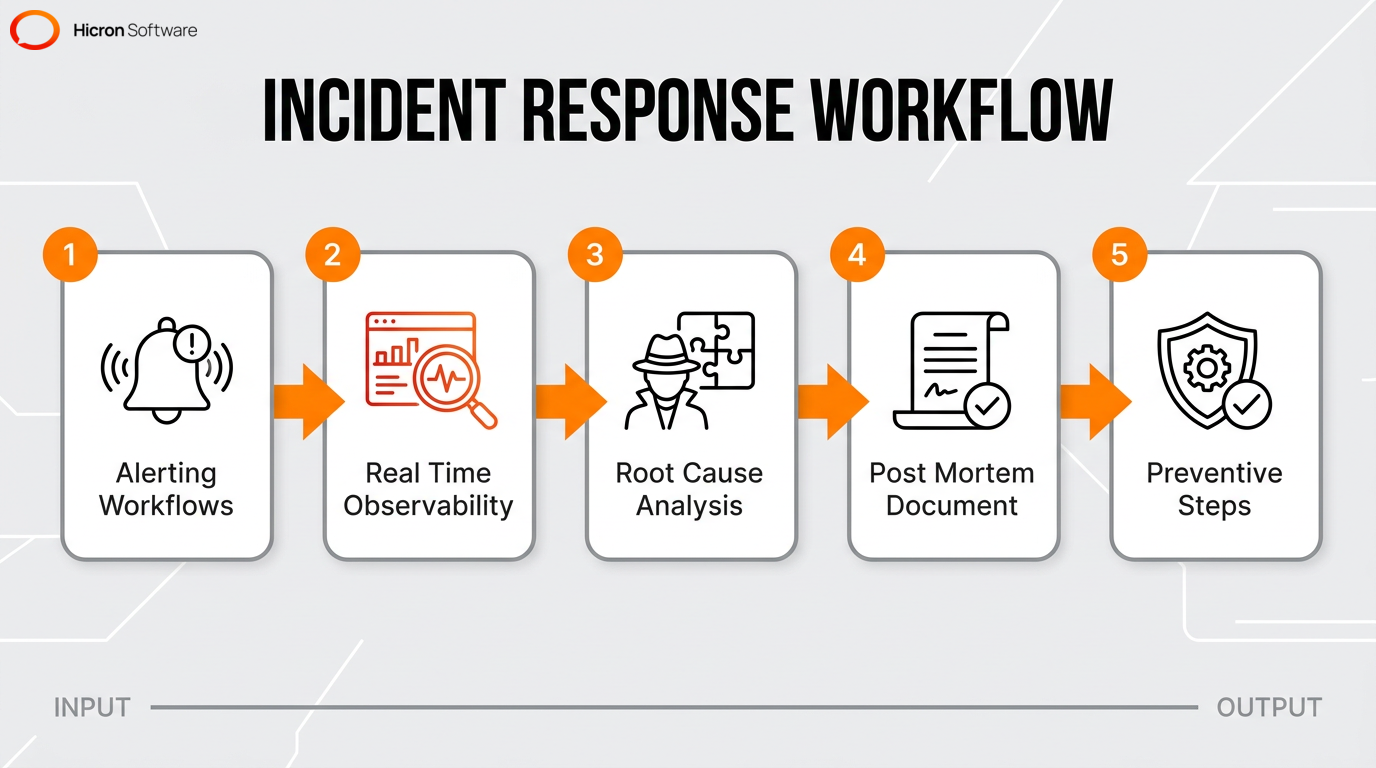
Site reliability engineering handles incident response through a structured framework that rapidly identifies, mitigates, and resolves service disruptions. SREs build efficient alerting workflows to minimize response times during active outages. The incident management process focuses on minimizing the business impact of unexpected downtime.
Engineers use real-time observability tools, such as monitoring dashboards and distributed tracing platforms, to quickly diagnose the scope and impact of an active incident. SREs rely on automation to speed up recovery procedures and reduce manual intervention.
On-call management operates as a structured 24/7 rotation of designated personnel who resolve critical incidents outside regular business hours. Site reliability engineering (SRE) minimizes alert fatigue by filtering notifications automatically. Trust me, being woken up at 3 AM for a non-critical issue is a quick way to burn out any engineer. An on-call engineer receives strictly actionable alerts from monitoring systems during production outages, such as memory leaks or broken deployments. Practitioners evaluate these off-hour alerts during a subsequent root cause analysis to reduce future manual work.
Root cause analysis and post-incident reviews systematically identify why a failure occurred and document solutions to prevent recurrence. This investigative process digs past surface symptoms to find fundamental technical or process failures. A hidden memory leak or a misconfigured routing table can often be the true culprit. Site reliability engineering (SRE) uses these investigations to transform system failures into opportunities to build stronger, more resilient systems.
Post-incident reviews provide a written record of lessons learned to improve long-term system availability. After resolving an outage, SREs write a detailed post-mortem document to outline the exact root cause and specific preventive steps. These steps might include updating monitoring thresholds or adding automated tests. This documentation directly helps teams build better DevOps workflows in the future. Engineers use data from observability and monitoring platforms to validate these findings following a severe disruption.
Chaos engineering tests system resiliency by intentionally injecting failures into a production environment to uncover hidden vulnerabilities, including network bottlenecks and misconfigured timeouts, before they cause unplanned outages. While it might sound terrifying to intentionally break production, it’s actually one of the most effective ways to sleep soundly at night. SREs don’t just break things randomly; they form a hypothesis about how the system should react, carefully control the “blast radius” of the test, and compare the actual result to their hypothesis. This proactive discipline complements incident response by building confidence in a platform’s capability to withstand turbulent conditions. The two primary goals for these chaos experiments are validating automated failover and verifying self-healing mechanisms.
Engineers might intentionally terminate a server instance to ensure that distributed systems automatically route traffic without dropping user requests. If these controlled disruptions reveal technical flaws, SREs use automation to maintain continuous system availability. Engineers adjust configurations to optimize scalability if a system struggles to handle these injected faults.
Site reliability engineering relies on a modern tech stack featuring infrastructure as code, CI/CD pipelines, and container orchestration. Three primary technological categories enable SRE practices: automation tools, cloud-native technology, and configuration management systems. SREs use these tools and microservices to build resilient distributed systems, including serverless architectures and multi-region application clusters, and develop internal self-service tools to simplify software deployments.
Infrastructure as code improves configuration management by using machine-readable definition files to provision environments instead of manual processes. This code-driven automation ensures that setups remain consistent, repeatable, and version-controlled, while eliminating human error and accelerating deployment times. SRE and DevOps teams treat infrastructure like software to automate the provisioning of critical resources, like servers and networks, using code repositories. Engineers scale systems more easily across cloud-native technology by integrating these files directly into CI/CD pipelines.
By integrating directly into CI/CD pipelines, modern change management automates safety checks to ensure new code deploys rapidly through specific development stages, ranging from code integration to application building, without causing unexpected outages. Site reliability engineering (SRE) enforces reliability standards automatically before code reaches production.
Engineers use pipeline components, such as automated testing and deployment scripts, to act as real-time change management controls. This strategy balances rapid deployment with system safety by embedding safety measures directly into the SDLC. Engineers deploy infrastructure as code safely by using this automation to validate configurations.
For container orchestration, Kubernetes serves as the industry standard for automating deployments and scaling cloud-native environments. Site reliability engineering (SRE) uses this platform to manage complex containerized environments and ensure high availability across microservices and distributed systems, including clustered databases and containerized web APIs.
Kubernetes automates the scaling of application containers up or down based on real-time traffic demands. This level of control maintains continuous scalability during unexpected operational loads.
Organizations adopt site reliability engineering to systematically improve system reliability, accelerate software delivery, and align the operational goals of development and IT teams. Implementing SRE typically leads to three main benefits: reduced downtime, an improved end-user experience, and faster release cycles. SRE provides a data-driven approach to balance rapid innovation with necessary system stability through specific practices, such as error budgets and advanced observability.
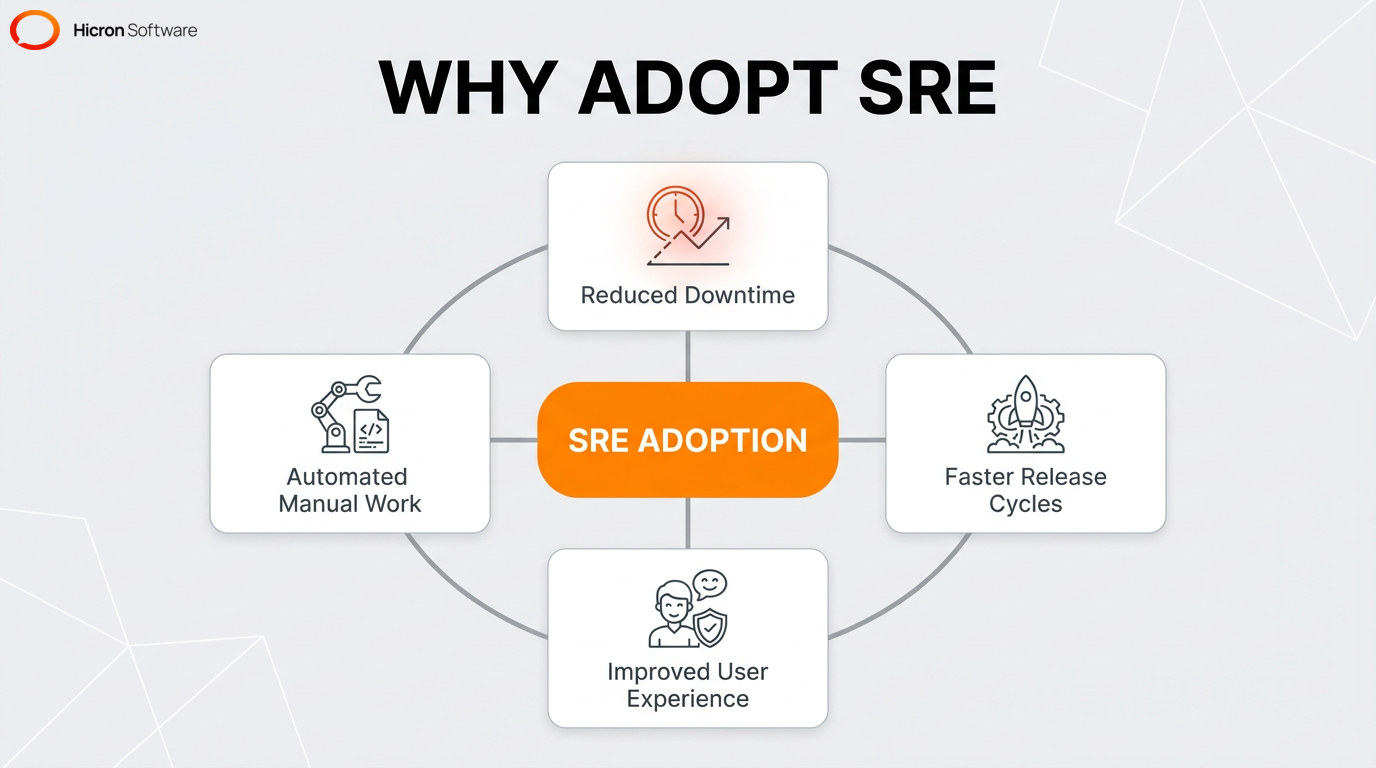
This discipline makes the SDLC more efficient by automating manual work and speeding up incident response. IT professionals manage toil to replace repetitive operational duties, ranging from alert triage to manual resource scaling, with code-driven automation.
Teams maintain high system availability and scalability by integrating these engineering standards directly into their infrastructure. Engineers refine system architecture to ensure platforms remain stable during rapid development phases. This strategic adoption helps companies hit their DevOps goals by making sure technical performance actually supports the business.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
