The Power of RAG: Supercharging AI with Real-World Knowledge
- September 18
- 7 min



Navigating the generative AI hype cycle isn’t easy. I’ve sat in countless strategy meetings where leaders admit they feel completely overwhelmed by the daily flood of new AI tools. Generative AI consulting provides expert advisory services to help organizations implement scalable solutions and control operational risks. These services manage leadership expectations regarding actual AI capabilities and bridge the gap between initial experiments and full-scale enterprise integration. Consultants deliver specific services to ensure successful adoption, including:
Consultants also help you lock down your data, keep your AI ethical, and prepare your team for the shift. Strategic consulting helps businesses avoid common enterprise pitfalls, such as misaligned use cases and poor data quality, during the transition from a proof-of-value to enterprise-grade AI. For instance, rather than deploying a company-wide chatbot simply to adopt AI, a targeted strategy might focus on automating a specific, high-cost customer service workflow to ensure measurable ROI.
|
Implementation Category |
Key Components & Strategies |
Enterprise Impact & Risk Mitigation |
|
Generative AI Consulting |
|
Bridges the gap between initial experiments and full-scale enterprise integration; helps avoid misaligned use cases and poor data quality. |
|
Enterprise-Grade Infrastructure |
|
Supports complex models securely, accommodates increasing data volumes, and prevents severe lag and operational crashes during production-grade deployment. |
|
Hallucination Reduction |
|
Connects large language models to verified, proprietary knowledge bases to guarantee context-aware responses, reduce error rates, and prevent false information. |
|
Production Deployment & LLMOps |
|
Maintains long-term stability and scalability, prevents technical debt, and sustains performance when user loads and data volumes spike. |
|
Responsible AI Governance |
|
Ensures ethical AI usage, minimizes data exposure risks, and prevents compliance nightmares and data breaches. |
|
Organizational Change Management |
|
Addresses human factors and workflow disruptions to prevent operational resistance and ensure successful AI adoption across the team. |
Before writing a single line of code, organizations must evaluate their existing technical maturity to pinpoint exactly where they fall short, whether that is a bottleneck in legacy systems, messy data silos, or a team that isn’t quite ready for AI.
Weighing these gaps against potential ROI helps you prioritize the right use cases. Fixing these foundational issues now keeps your systems from crashing when you finally scale up.
Enterprise-grade AI relies on a high-capacity infrastructure to support complex models securely. Here is a hard-learned pro-tip from the field: never underestimate your initial compute requirements. First, you need to audit your current computing power to make sure your security setup can actually handle an LLM. Your infrastructure must include the following to handle advanced data processing:
For example, running open-weight models like Llama 3 or Mistral in-house requires designing for scalability to accommodate increasing data volumes and prevent system failure during a production-grade deployment. Without this specialized environment, scaling up usually leads to severe lag and operational crashes.
Strict data governance forms the foundation of an AI readiness assessment and determines the reliability of generative AI outputs. If your AI is fed garbage data, it will output garbage results. You need strict frameworks for data availability, privacy, and regulatory compliance, such as access control systems, encryption standards, and classification protocols, within your security architecture.
High data integrity helps minimize risks, reduces the chance of the model hallucinating, and ensures the AI operates ethically. When you’re handling sensitive proprietary data, this level of governance isn’t just best practice; it’s mandatory to prevent leaks.
Generative AI implementation carries serious risks that require proactive safeguards. Rushing a deployment without a readiness check often leads to skyrocketing cloud computing costs, data leaks, or models that crash under user load. Expert guidance helps keep your systems stable as you move from a sandbox experiment to a live environment.
Teams generally rely on two technical frameworks, retrieval augmented generation (RAG) and prompt engineering, to stop LLMs from hallucinating. We have all seen the viral examples of chatbots confidently making up fake facts, and preventing that in a corporate setting is paramount. Developers primarily use RAG to reduce hallucinations in enterprise apps. It connects large language models to verified, proprietary knowledge bases to guarantee context-aware responses and prevent false information.
Prompt engineering acts as an initial layer of defense against misleading outputs. Combining this technique with model fine-tuning and continuous performance monitoring drastically reduces error rates and maximizes output reliability. Systems maintain responsible AI standards when developers restrict generative models to factual data inputs. This multi-layered defense keeps your AI honest and your enterprise safe.
Data privacy and security act as critical constraints that shape enterprise-grade AI deployment. Adapting your deployment strategy means baking in advanced data encryption and strict access controls within the security architecture. Without these defenses, integrating an LLM is a fast track to a compliance nightmare or a data breach.
Privacy and security are the bedrock of responsible AI governance. Enforcing these strict data governance protocols before going live is the only way to keep your AI ethical and secure.
Technical debt in AI projects stems from rapid, uncoordinated implementations and poorly planned integrations with legacy enterprise systems. This usually happens when teams bypass architectural planning or skip a thorough infrastructure assessment. These rushed decisions create severe challenges during LLM integration.
Forcing enterprise AI onto outdated platforms without a roadmap will cost you heavily in the long run. This poorly planned legacy system integration restricts scalability and complicates continuous LLMOps.
Generative AI projects frequently fail after the proof-of-concept phase because organizations underestimate the core complexities of enterprise integration: achieving scalability, integrating with legacy systems, and maintaining continuous data quality. I often refer to this as the “prototype illusion,” where early success masks long-term integration hurdles. A proof-of-concept is like driving a car on an empty test track; production is navigating rush-hour traffic. A controlled experiment relies on static data, but a live environment throws unpredictable, real-time data at your infrastructure—and your security architecture has to handle it all without breaking.
When an AI experiment fails to reach production, it usually comes down to a few key culprits:
If initial proof-of-value returns don’t translate to live operations, you face a high risk of disappointment. Scaling generative models without updating your deployment roadmap often leads to operational failures. That’s where strategic advisory comes in; it establishes realistic expectations and ensures continuous performance monitoring. Applying strict safeguards during the scaling process successfully bridges the gap between an isolated test and a live application.
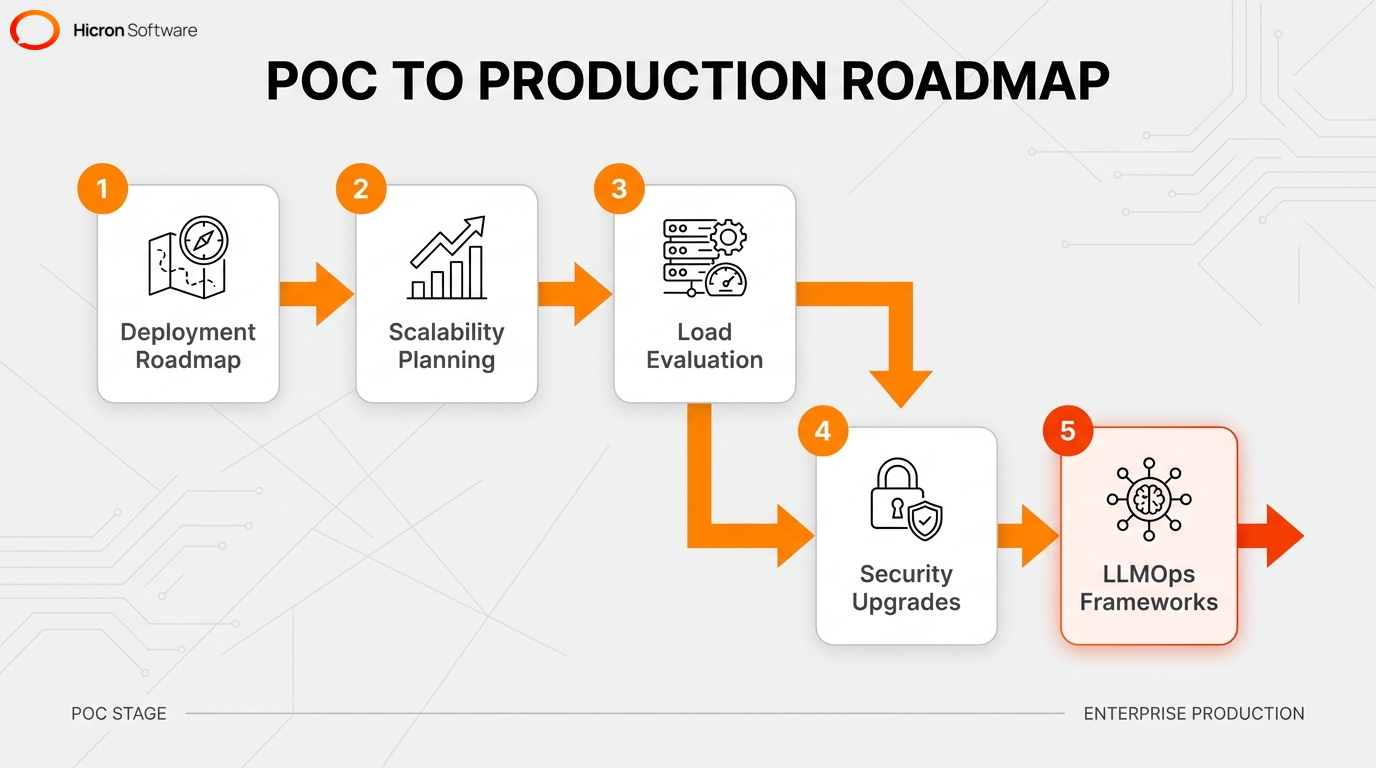
Transitioning from an isolated proof-of-concept to a production-grade deployment requires a strategic deployment roadmap, thorough scalability planning, and resilient LLMOps practices. Production-grade systems must undergo intense load evaluation to support enterprise-wide use. Making this move successfully requires upgrading your security, stress-testing your scalability, and locking in your LLMOps frameworks.
Enforcing these practices is the only way to achieve true scalability. Without them, you face severe operational risks during the transition. Aligning your expectations with actual technical constraints prevents critical system failures.
Integrating large language models with legacy systems requires careful architectural planning to bridge modern AI capabilities with existing enterprise software without incurring technical debt. Connecting these advanced tools securely requires conducting a rigorous infrastructure assessment and updating your security architecture prior to a production-grade deployment. Evaluating data readiness first helps manage the complexities of system integration.
Establishing secure connections to established software platforms, such as ERP and CRM systems, prevents operational failures. A structured deployment roadmap ensures this integration leads to long-term scalability.
LLMOps is the essential framework for maintaining the long-term stability, scalability, and performance of generative AI models in a production environment. Implementing LLMOps guarantees continuous performance monitoring, automated model retraining, and scheduled maintenance. Without it, your models will likely buckle as soon as user loads and data volumes spike.
These practices make it easier to scale enterprise AI solutions by executing automated workflow orchestration. An infrastructure assessment identifies capacity limits before large language models process live data. Integrating strict LLMOps protocols into your roadmap is the best way to sustain performance and prevent system failures.
Choosing the right AI strategy means matching your technical approach to your actual business goals and AI maturity. A thorough AI readiness assessment and strict use case prioritization reveal an organization’s true readiness. Generally, you have two options: build a bespoke solution or integrate an off-the-shelf LLM.
Start by evaluating your existing technical debt and data infrastructure first to choose effectively. From there, using accurate ROI modeling helps set realistic expectations. Off-the-shelf models offer rapid deployment but present specific limitations regarding proprietary data control. Bespoke solutions provide maximum data security but demand extensive computational resources and rigorous scalability planning.
A structured deployment roadmap ensures extensive risk management regardless of the chosen technical path. Aligning your strategy with realistic technical constraints is key to preventing severe operational failures during a production-grade deployment.
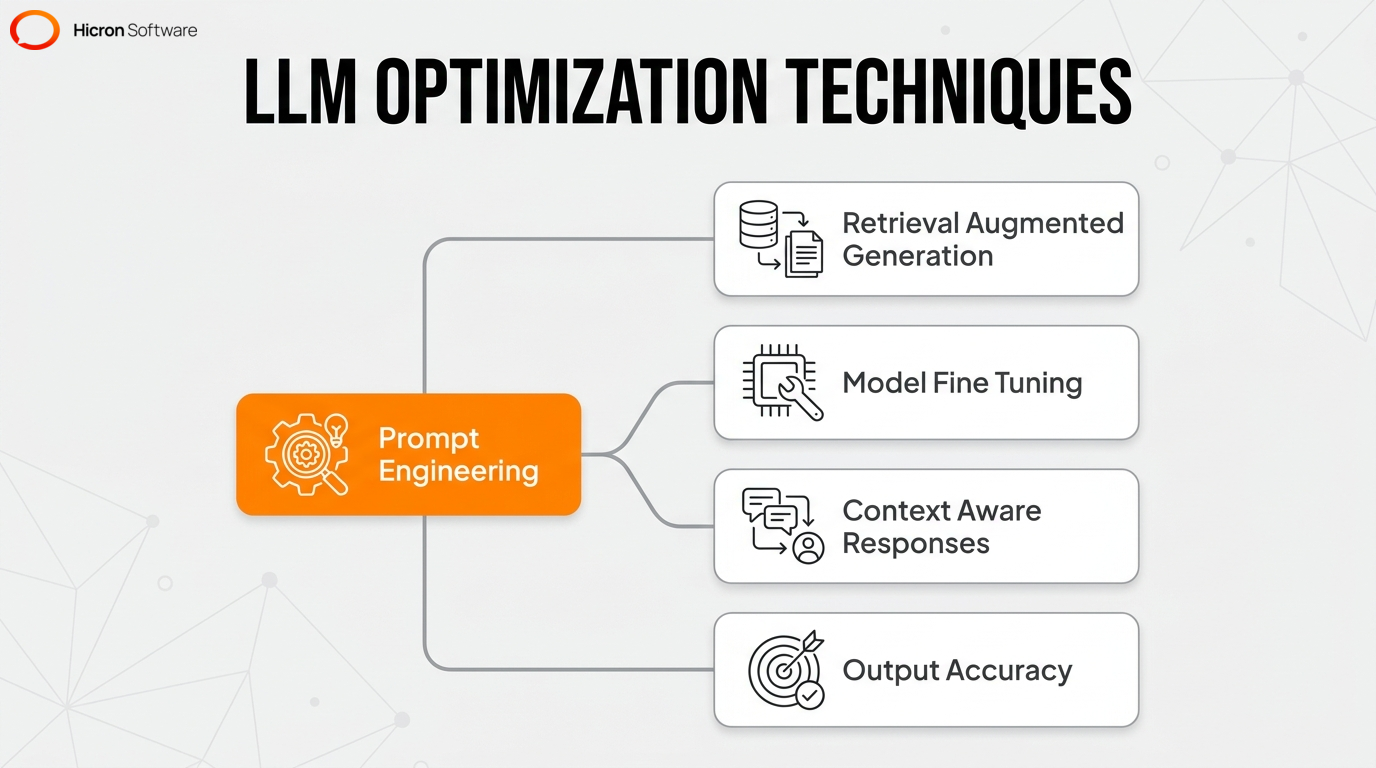
Prompt engineering, retrieval augmented generation, and model fine-tuning represent escalating levels of technical complexity and customization for optimizing large language models. Prompt engineering is the foundational technique for refining model inputs. This approach allows for rapid iteration during a proof-of-concept and immediate hallucination reduction. However, this method offers limited customization if an organization requires deep domain expertise.
RAG is an architectural framework for delivering context-aware responses using proprietary data. Specific use cases for RAG implementation include querying an internal knowledge base and ensuring accurate LLM integration without altering the underlying model. This framework limits data exposure risks when businesses process sensitive information.
Model fine-tuning is the complex process of adapting a pre-trained model to a specific business domain. This advanced method is typically used to standardize a corporate tone or teach a model specialized industry jargon. This approach demands significant computational resources and strict performance monitoring.
Developers use prompt engineering and model fine-tuning as complementary techniques to optimize performance. Their combined benefits include lower computational costs and higher output accuracy. Combining these methods strategically yields maximum accuracy while reducing operational risks.
Developers use Agentic AI and automated workflow orchestration for complex, multi-step tasks requiring autonomous reasoning and tool calling. In scenarios like multi-system data retrieval or dynamic supply chain adjustments, autonomous agents provide far more value than standard large language models. They handle complex workflow orchestration with minimal oversight. But they aren’t entirely unchecked. Agentic systems incorporate human-in-the-loop workflows to manage high-risk automated tasks.
Integrating human oversight into these processes is crucial for preventing system failures during a production-grade deployment. Successful LLM integration for agentic systems relies on continuous performance monitoring to guarantee accurate tool execution. This approach ultimately drives long-term scalability and precise ROI modeling. Businesses prevent critical failures by restricting autonomous actions within secure environments.
Establishing responsible AI governance requires structured ethical frameworks and strict adherence to regulatory compliance to ensure secure, unbiased, and transparent AI usage. A thorough governance framework relies on creating transparency policies, enforcing ethical standards, and scrutinizing outputs for bias. Evaluating these outputs protects your brand reputation and ensures automated decisions align with corporate policies.
Strict regulatory compliance requires alignment with specific legal frameworks, such as GDPR and HIPAA. Integrating these legal constraints into your security architecture is essential for ethical AI and risk management.
Consultants typically focus on ensuring data privacy, verifying system security, and guaranteeing model explainability. Systems achieve hallucination reduction and maintain high data governance standards when developers monitor these ethical parameters continuously. This rigorous structure is the mandatory foundation for deploying secure enterprise-grade AI.
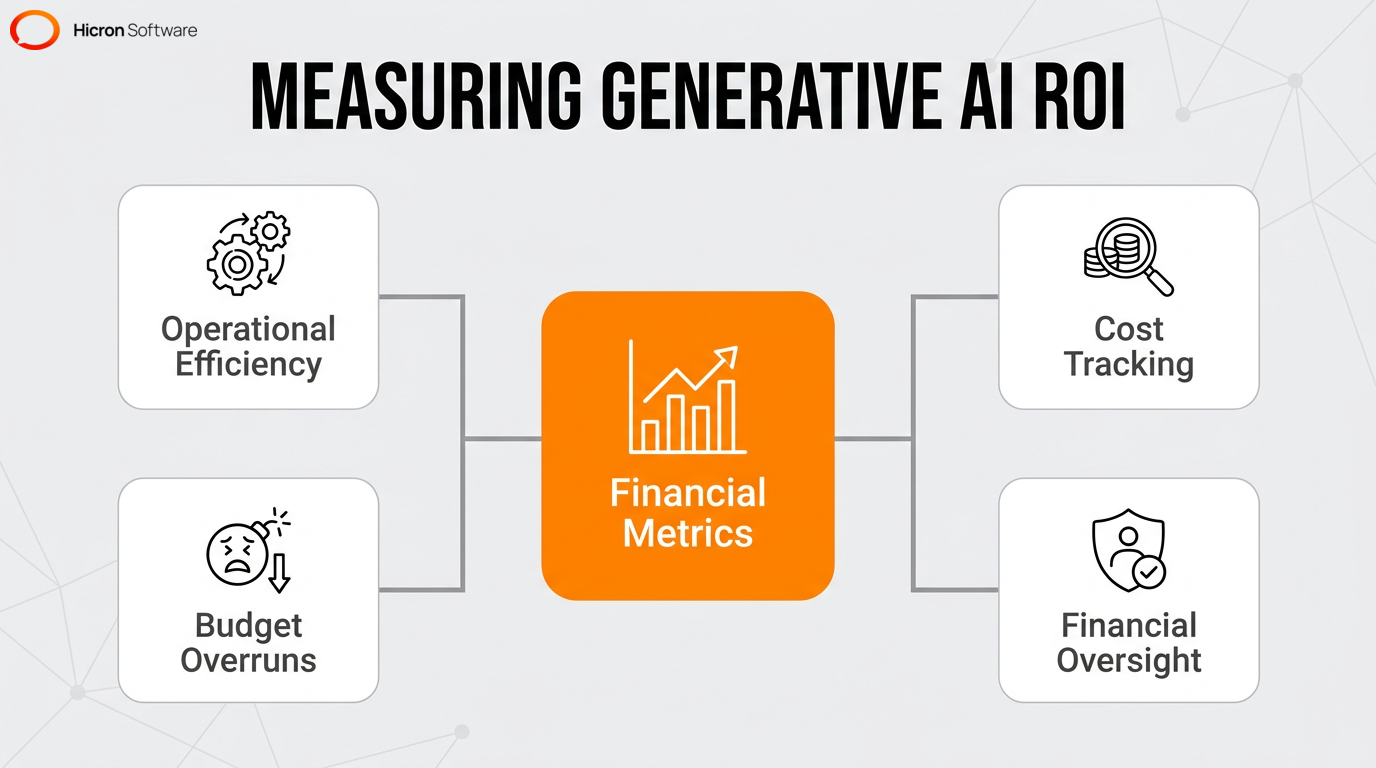
Measuring ROI for generative AI involves setting clear benchmarks prior to a production-grade deployment and tracking tangible business outcomes. Define specific financial metrics during the initial proof-of-value phase to justify implementation costs and accurately model ROI. Standard ROI modeling tracks tangible business outcomes, such as improvements in operational efficiency and direct reductions in manual processing costs. Set realistic benchmarks early on to prevent severe budget drains during the scaling phase.
Enterprise AI carries specific financial risks, namely high computational processing fees, the rapid accumulation of technical debt, and continuous performance monitoring expenses. Without rigorous cost tracking, you will likely face severe budget overruns. Strict financial oversight guarantees effective financial control and ensures that technological investments align with realistic corporate objectives.
Even the most advanced AI implementation will fail if the organization isn’t ready for it. Take it from me: you can build the most elegant technical architecture imaginable, but if your employees are hesitant to use it, your investment is entirely wasted. Change management addresses the cultural shifts, training needs, and stakeholder expectations required for successful integration. Technical AI implementations fail without a corresponding organizational change management strategy because they ignore human factors and workflow disruptions. Targeted training and cultural alignment are essential to prepare your teams for AI adoption.
Change management regulates leadership and employee expectations regarding AI capabilities during a proof-of-value phase. Executing an AI readiness assessment early prevents unrealistic expectations and operational resistance. Aligning human readiness with technological capabilities ensures accurate ROI modeling and reduces risks. If you ignore the human element, even the most advanced AI system will fail when you try to scale it.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
