10 Real Estate Software Development Companies in 2026
- February 03
- 9 min


AI PropTech software development is the specialized practice of designing, building, and deploying real estate technology (PropTech) that incorporates artificial intelligence (AI) and machine learning (ML) capabilities.
This field focuses on creating applications to offer predictive insights, process automation, and intelligent decision-making. Examples include developing Automated Valuation Models (AVMs) for predictive property pricing, creating recommendation engines for tenant matching, and implementing anomaly detection systems to prevent financial fraud in transactions.
Ultimately, AI PropTech software development aims to enhance efficiency, improve accuracy, and create new value within the real estate ecosystem by using data-driven intelligence.
This article is the fifth in our 6-part series, Architecting PropTech at Scale. Many PropTech companies say they use AI. Few have built their platforms to support what AI actually requires. AI in real estate is not a single feature. It is a data infrastructure layer with its own latency requirements, compliance obligations, and failure modes. Getting it wrong produces brittle pricing models, silent performance degradation, and regulatory exposure under the EU AI Act. This article covers four areas that every PropTech architect needs to understand: AI as infrastructure, production AI stack design, EU AI Act risk classification, and Human-in-the-Loop design as a core system pattern.
Key Takeaways
PropTech AI creates genuine value across four distinct architectural areas. Each area maps to a concrete business outcome.
Poorly architected AI creates severe systemic vulnerabilities. Treating complex models as simple product features leads to brittle systems that degrade silently over time. It amplifies bias in pricing and tenant matching algorithms. It creates immediate regulatory exposure under the EU AI Act. Inference pipelines that scale without proper governance quickly become massive compliance liabilities.
Architects cannot view AI in PropTech as a product feature. It is a distinct data infrastructure layer with its own stringent latency requirements, compliance obligations, and catastrophic failure modes.
The most common architectural failure in PropTech software development is the bolted-on AI anti-pattern. Teams deploy a recommendation engine or pricing model as an isolated microservice that queries the main operational database directly. This setup lacks a defined data contract, ignores model monitoring, and provides no fallback mechanism. It degrades core system performance and makes debugging nearly impossible.
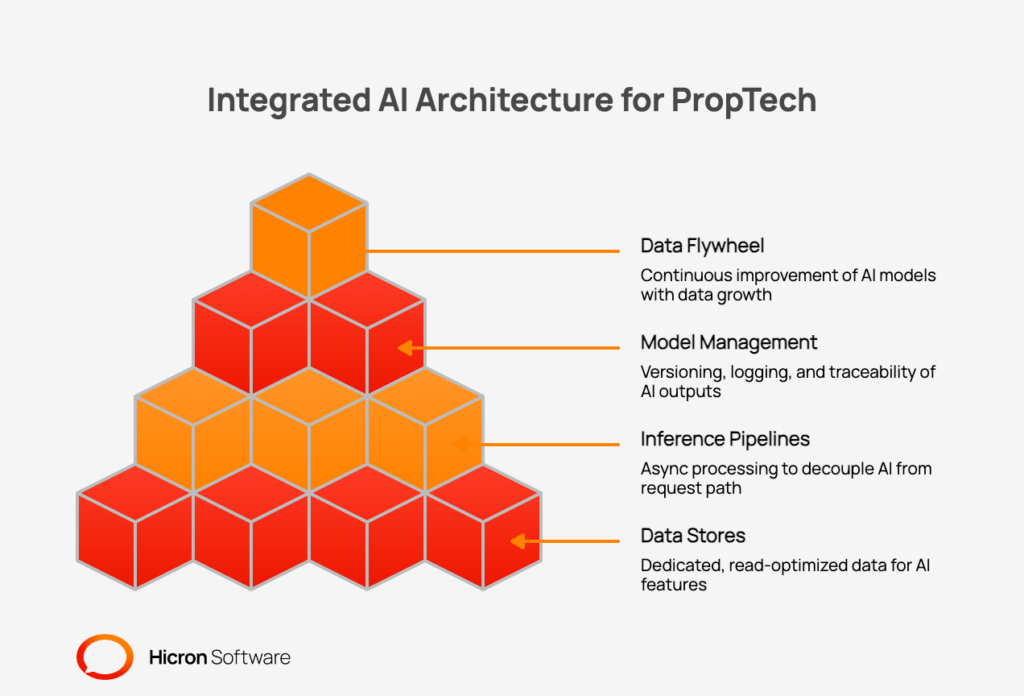
An integrated AI architecture model demands strict separation and purpose-built components. AI features consume data from dedicated, read-optimized data stores. You should never force models to query the operational databases that serve live tenant and agent traffic.
Inference pipelines decouple from the request path via async processing. A pricing recommendation taking 800ms must not degrade a property search. That search must return results in under 300ms.
Model outputs require versioning, logging, and full traceability. Every recommendation or valuation must be reconstructable from its input features. This enables both audit and effective debugging.
The data flywheel principle governs long term AI quality. Models improve as platform data volume grows. This only functions if the data architecture captures the right signals from the start. Search behaviour, listing engagement, and transaction outcomes must all feed the pipeline.
Selecting the right infrastructure directly dictates your platform’s ability to scale, innovate, and maintain a competitive advantage. A production-grade PropTech AI stack is a collection of specialized tools working in concert to manage the end-to-end machine learning lifecycle. The production-grade PropTech AI stack has five layers.
Among these components, the feature store is arguably the most critical and frequently underinvested piece of the puzzle in PropTech AI architecture. Without a feature store, each new model development cycle forces engineers to recreate the same feature engineering logic. This redundancy leads to inconsistencies between the data used for training and the data used for real-time inference. A problem known as training-serving skew, which silently degrades model performance and erodes user trust at scale. A well-implemented feature store solves this by ensuring that the exact same feature logic is used in both environments, making models more reliable and accurate.
|
Component |
Description |
|
Training Layer |
The environment where models are developed. It uses Python libraries like TensorFlow and PyTorch for deep learning and scikit-learn for classical ML tasks like fraud detection. |
|
Feature Store |
A centralized repository for pre-computed, versioned, and reusable features (e.g., property characteristics, market signals). It acts as a single source of truth to prevent feature computation duplication. |
|
Ingestion Layer |
Enables real-time data consumption from sources like MLS feeds and event streams using tools such as Apache Kafka or AWS Kinesis. This ensures training data remains current without batch pipeline latency. |
|
Training and Serving Infrastructure |
Managed platforms like AWS SageMaker or Google Cloud’s Vertex AI that reduce operational overhead for model training, versioning, and controlled deployments (e.g., A/B testing). |
|
Analytics Layer |
A powerful analytics engine, such as Google Cloud’s BigQuery, designed for large-scale analysis. It is used to evaluate models and query vast datasets of property market information. |
A production-grade AI architecture is not a single system but a carefully orchestrated data flow. The end-to-end PropTech AI data flow moves through seven stages. MLS feeds and IoT sensor data enter a Kafka ingestion pipeline. That pipeline populates the feature store. The feature store drives model training on SageMaker or Vertex AI. Trained models go into a model registry. The registry serves an inference API. The API powers the PropTech platform interface. All outputs feed monitoring and retraining triggers.
The end-to-end PropTech AI data flow typically follows this path:
MLS feeds and IoT sensor data → Kafka ingestion pipeline → feature store → model training (SageMaker/Vertex AI) → model registry → inference API → PropTech platform interface → logged outputs → monitoring and retraining triggers.
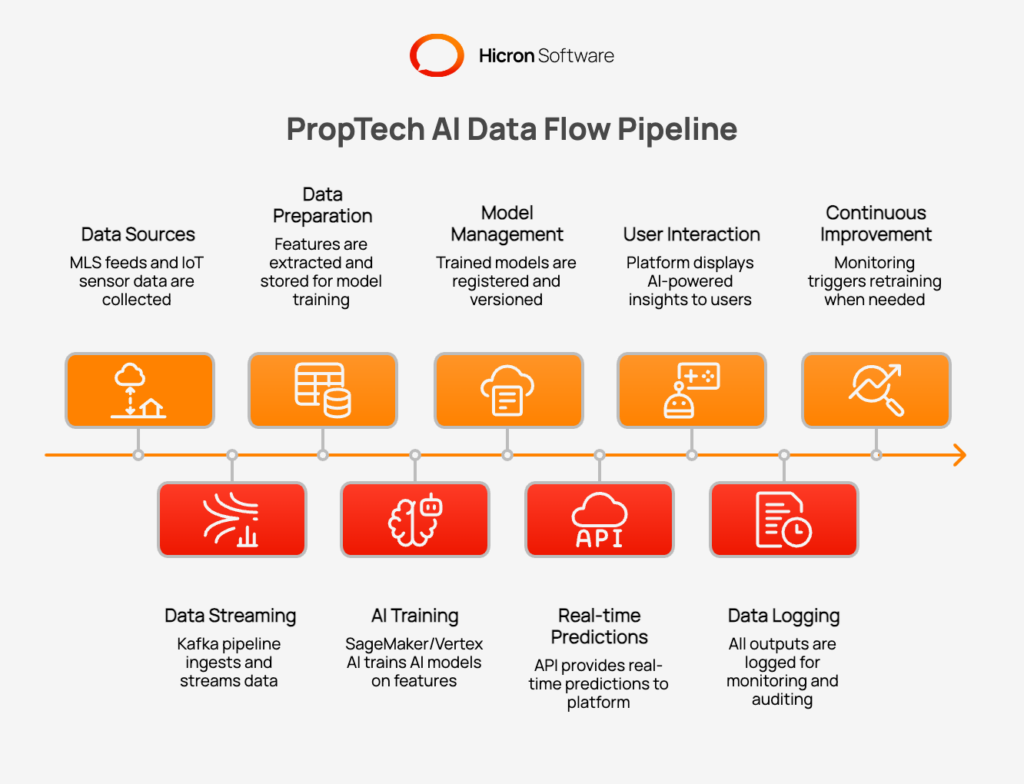
Success depends on making the right architectural decision at each stage.
Property market conditions change faster than most ML training cycles. A pricing model trained on pre-rate-rise data actively misleads agents and buyers. Managing model drift requires a dedicated monitoring architecture designed to detect shifts before they impact business outcomes. A robust drift detection system for PropTech AI has three core components:
To orchestrate this entire lifecycle, tools like MLflow become the operational foundation. MLflow provides the necessary infrastructure for experiment tracking, model versioning, and maintaining a clear deployment lineage. This makes the complex process of managing model drift tractable at scale, ensuring that your AI systems adapt to the market instead of becoming obsolete.
Tenant-facing recommendation interfaces require response times under 300ms. Inference pipelines that cannot meet this threshold must be redesigned. Optimisation alone will not resolve a structural latency problem.
Computationally intensive models require a different approach. Property valuation models may need two to three seconds of computation. A request-response-poll pattern maintains interface responsiveness without sacrificing model sophistication. The user experience remains fluid and the complexity is absorbed by the architecture. It maintains interface responsiveness without reducing model sophistication.
Every AI backed endpoint requires a defined fallback behaviour for model unavailability. A listing interface that returns popularity ranked results when the recommendation engine is down is a design requirement.
The EU AI Act adds an explainability interface requirement for high-risk systems. High-risk PropTech AI systems must provide human-readable explanations for their outputs. Designing this into the API response schema from the start, as a first-class field, not a retrofitted string, is easier than adding it as a compliance obligation after the interface has been built around opaque scores.
The EU AI Act became effective in August 2024. Phased enforcement continues through 2026. Full high-risk system obligations apply from August 2026. The runway is shorter than most PropTech teams currently assume.
The risk-based framework maps directly onto PropTech architecture decisions.
The August 2026 deadline functions as an architectural forcing function. PropTech platforms that have not completed AI Act gap analyses face a narrowing window. Compliant human oversight interfaces, bias auditing pipelines, and technical documentation frameworks all require substantial build time.
The PropTech high-risk AI use case matrix maps commercial features to regulatory obligations.
|
AI Use Case |
Risk Classification |
Required Architectural Measures |
|
Automated property valuation |
High risk |
Bias audits, human review loops, explainability API |
|
Tenant profiling for matching |
High risk / Prohibited boundary |
Consent architecture, no sole automation |
|
Credit assessment for buyers |
High risk |
Human oversight interface, data quality docs |
|
Real estate ad targeting |
GPAI / High risk |
Transparency notices, profiling consent |
|
IoT occupancy analytics |
High risk (personal inferences) |
DPIA, minimisation, erasure capability |
|
Listing chatbot |
Limited risk |
User notification of AI interaction |
|
Market trend analytics |
Minimal risk |
Standard monitoring |
High-risk classification mandates specific system components. Human oversight interfaces must be designed and built. Bias audit pipelines are required. Technical documentation is required. Conformity assessment processes are required. A policy document describing these components does not satisfy the legal obligation.
Tenant profiling presents particular risk at the architectural level. PropTech platforms using behavioural signals to infer characteristics that influence tenancy decisions operate close to the prohibited category. The product documentation framing does not alter the legal classification.
The EU AI Act sets a concrete standard for effective oversight. Human reviewers must be able to understand, question, and override AI outputs. An interface that displays a score without the features driving it fails this standard.
Three oversight interface components must be present in every high-risk PropTech AI system.
The oversight interface, built correctly, is also a competitive signal. Platforms that make AI explainability visible to agents and institutional clients build a level of trust that their competitors cannot replicate. A compliance requirement, properly implemented, becomes a market differentiator.
Human in the Loop (HITL) is a set of architectural components embedded in the platform’s microservice architecture. Those components include confidence thresholds, routing queues, override interfaces, and audit logs. That definition shapes how HITL gets built, tested, and maintained.
Three HITL models map to distinct PropTech use cases.
Embedding HITL in the microservice architecture routes low confidence inference outputs to a review queue service via Kafka events. A dedicated review interface serves human operators. An audit log captures every intervention for EU AI Act transparency documentation.
Four frameworks are worth evaluating against PropTech-specific HITL requirements:
|
Framework |
Core Strengths |
PropTech Fit |
Best Use Case |
|
Pendoah |
Lifecycle governance, ROI metrics, trust measurement via override rates |
Compliance audit cycles, hybrid sovereignty |
Tenant matching oversight, valuation review loops |
|
Permit.io |
Modular interrupt() patterns, approval roles, audit first logging |
Real time transaction gates, agentic AI |
Payment authorisation, contract decision gates |
|
Galileo |
Confidence based escalation, hybrid sync/async architecture |
Under 300ms latency maintenance during review |
Search and recommendation scaling |
|
Bannerman |
Risk optimised authority, circuit breakers for irreversible decisions |
Transparent client reporting, eviction decisions |
High stakes tenancy and contract actions |
The PropTech HITL framework recommendation follows from use case requirements. Galileo covers confidence threshold routing in high volume recommendation and search contexts. Permit.io handles transaction critical decision gates. Pendoah governs audit cycles that feed EU AI Act compliance documentation.
HITL intervention logs should feed into GDPR compliance tooling. Sprinto and Drata evidence collection pipelines should consume these logs as compliance evidence. This produces a unified audit trail. That trail serves both AI Act and GDPR obligations from a single data source.
The tenant matching HITL architecture sets a confidence threshold at 80%. Matches above that threshold surface to agents with an explainability panel attached. Matches below the threshold route to a human review queue before agent visibility. All decisions log with model version, input features, and reviewer identity.
The pricing analytics Human on the Loop architecture operates differently. AVM outputs publish to agents with confidence intervals and contributing feature breakdowns. Human override events are captured and fed back to model monitoring. Statistical drift alerts route to the ML engineering team before degradation reaches tenant facing interfaces. This is continuous oversight, not per decision review.
Some decisions carry legal consequences. Eviction recommendations and automatic tenancy rejections fall into this category. Bannerman-style circuit breakers require explicit human authorisation regardless of model confidence. Full audit trails are maintained for regulatory inspection.
Human review workflows embedded in PropTech AI pipelines must not degrade interface response times below 300ms. Async routing patterns keep review queues independent of the primary request path. Both performance and oversight requirements can be met simultaneously with the right architecture.
Before deployment, every PropTech AI system should pass the following architecture review.
The AI architecture built against this checklist is only as trustworthy as the bias detection infrastructure that continuously validates it. That infrastructure must be treated as a core system component. Periodic audit exercises are not sufficient substitutes. The next stage of PropTech AI maturity begins with that commitment.
The PropTech platforms that will define real estate over the next decade are not those with the most AI features. They are those whose AI architecture is precise enough to improve, transparent enough to trust, and compliant enough to survive the regulatory environment that is already here.
Building that architecture is harder than building a recommendation widget. It requires treating AI as infrastructure from the first design decision, not as a feature layer added to a platform that was designed without it. It requires understanding the EU AI Act not as an external constraint but as a specification for the oversight components that high-stakes AI systems should have had from the start.
It is also the only version that scales: technically, operationally, and commercially. Platforms that get this right are not just compliant. They are architecturally positioned to improve as their data grows, to earn institutional trust that black-box competitors cannot replicate, and to absorb the next wave of regulatory requirements without rebuilding from scratch.
That is what it means to build AI into a PropTech platform rather than bolting it on.
This is the fifth in the Architecting PropTech at Scale series. Explore the full series index for the specific architecture layer your platform needs next.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
