Essentials of IT Infrastructure Management Services and When to Use Them
- June 18
- 15 min


IT infrastructure management is the administration and governance of an organization’s entire technology ecosystem to ensure the business operates efficiently, protects its critical data, and adapts to future growth. It encompasses:
In practice, this means controlling the full lifecycle of IT assets, such as physical servers, networking equipment, and enterprise applications. Administrators manage these assets from initial acquisition to final retirement.
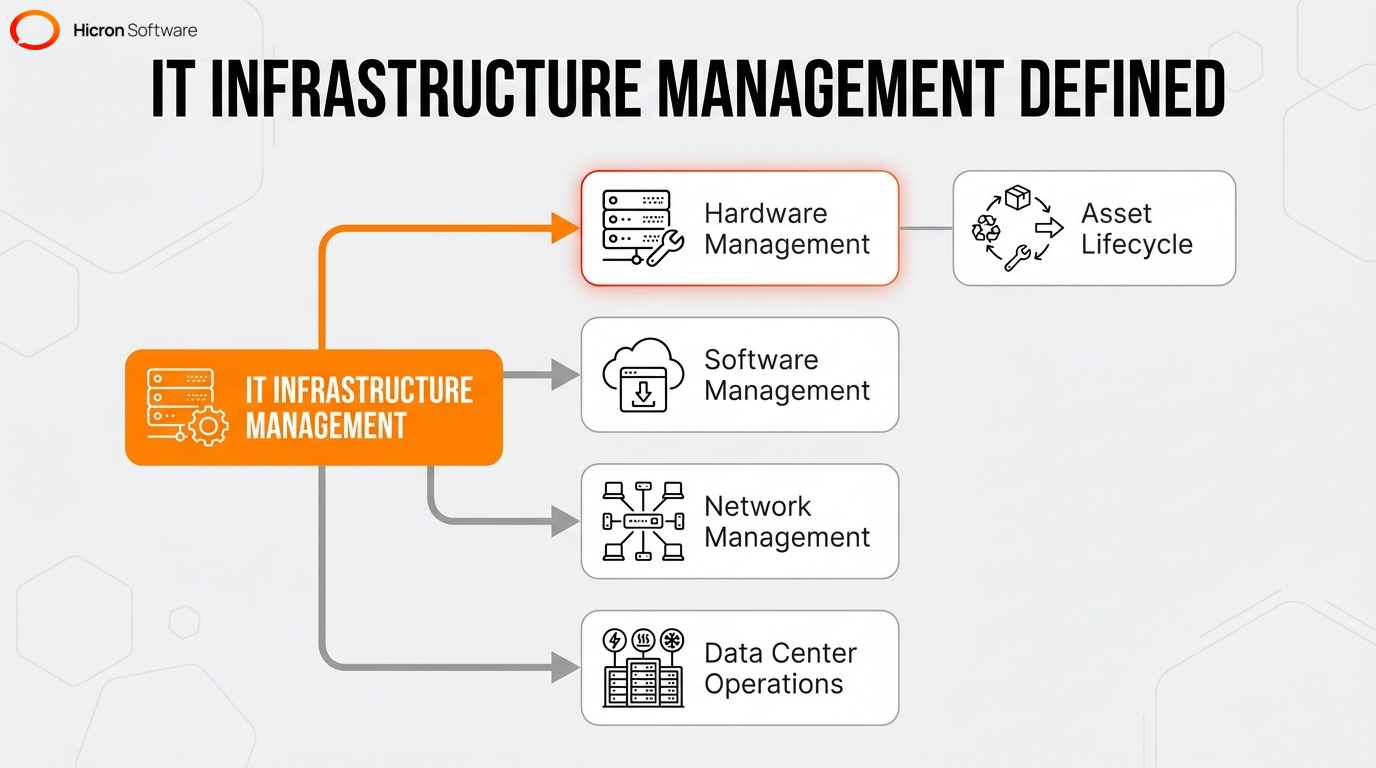
The primary objective is maximizing system uptime and minimizing operational disruptions. By reducing emergencies like unexpected system failures, security breaches, and network outages, proactive management and capacity planning lower expenses. This strategy makes the most of your existing hardware and integrates IT service management standards to maintain operational stability.
|
Category |
Core Components & Concepts |
Description & Business Value |
|
Core Infrastructure |
|
Controls the full lifecycle of IT assets from acquisition to retirement to maximize system uptime. Involves server consolidation, capacity planning, load balancing, and virtualization to abstract physical hardware and optimize resource utilization. |
|
Cloud Computing Models |
|
Hybrid integrates on-premises systems with cloud resources, while multi-cloud prevents vendor lock-in. IaaS provides virtualized computing resources, PaaS offers hardware/software tools for application development, and SaaS delivers subscription-based software applications over the internet. |
|
IT Service Frameworks |
|
Standardizes IT operations to align with business objectives. Incident management resolves IT disruptions quickly, problem management investigates root causes, and change management controls the lifecycle of system modifications to minimize deployment risks. |
|
Security & Continuity |
|
Protects networks by enforcing the principle of least privilege and continuously discovering/fixing exposures. Ensures business continuity by restoring critical IT systems swiftly using metrics like recovery point objectives (RPO) and recovery time objectives (RTO). |
|
Optimization & Automation |
|
Shifts operations from reactive to proactive by detecting anomalies early. Configuration management enforces standardization to prevent configuration drift. IaC standardizes system setups using machine-readable definition files, accelerating deployment. |
|
Emerging Trends |
|
AIOps uses artificial intelligence to predict system failures. Edge computing reduces latency by relocating processing power closer to the data source. HCI is a software-defined system that unifies physical components into a single, easily managed appliance. |
Think of IT infrastructure like a city. Hardware is the physical buildings, software is the businesses operating inside them, networks are the roads connecting everything, and data storage is the warehouses. Just like a city, IT teams must manage these elements collectively to keep traffic flowing and ensure uninterrupted service delivery.
Managing hardware and software assets requires strict lifecycle control, tracking, and maintenance to keep systems running fast and reduce costs. For physical hardware like servers and workstations, lifecycle control involves continuous tracking and planned refresh cycles. Effective hardware management also incorporates server consolidation to get more out of fewer servers and prevent crashes. In my experience, skipping these refresh cycles is the fastest way to invite a 3:00 AM emergency.
For software, lifecycle control requires rigorous management of licensing, updates, and compatibility tracking. This process uses configuration management, routine patch management, and vulnerability assessments to maintain security. Why does this matter? IT Asset Management (ITAM) tracks everything from physical servers to software subscriptions. Maintaining updated documentation of these resources ensures team coordination and rapid troubleshooting. Systematic asset management guarantees smooth day-to-day functioning.
Network management is the administration and protection of network resources to ensure reliable connectivity, data flow, and security. It covers the setup and maintenance of network hardware, such as routers, switches, and firewalls. Administrators ensure reliable communication through performance monitoring, log management, and network optimization.
Load balancing and efficient routing protocols optimize traffic, prevent bottlenecks, and make better use of available bandwidth. Integrating network security and cybersecurity protects against threats. This integration relies on routine vulnerability assessments to maintain system uptime and ensure reliable network performance.
Storage management ensures efficient data accessibility and scalability through proactive capacity planning. Capacity planning prevents data storage bottlenecks by forecasting future resource requirements to avoid overspending. Storage managers oversee physical and virtual data storage technologies across data center operations, including local server arrays and cloud computing environments.
Virtualization techniques allow for dynamic resource reallocation when enterprises use storage provisioning. Thin provisioning allocates storage on demand, which helps reduce waste and improve utilization, while thick provisioning reserves the full amount upfront for more predictable allocation and performance. Choosing between the two depends on workload demands, growth expectations, and the level of monitoring the IT team can maintain.
Continuous performance monitoring optimizes resource utilization and reduces wasted storage capacity. To protect these assets, teams rely on backup systems and disaster recovery plans.
Virtualization optimizes data center operations by abstracting physical hardware to enable server consolidation and highly efficient resource utilization. By allowing a single physical server to host multiple virtual machines, virtualization slashes hardware dependency and squeezes every drop of compute power out of your existing assets. Abstracting the hardware makes it much easier to provision resources rapidly or migrate to the cloud.
When done right, virtualization makes scaling easier, simplifies daily tasks, and keeps systems online longer.
Effective IT infrastructure management bridges the gap between your technology and your business goals. When done right, it provides several key benefits:
Proactive management and capacity planning lower expenses by reducing emergencies. By implementing IT service management frameworks, teams can streamline daily workflows. Maintaining strong cybersecurity and executing detailed disaster recovery planning protects critical assets, and these integrated practices guarantee continuous functionality across the enterprise.
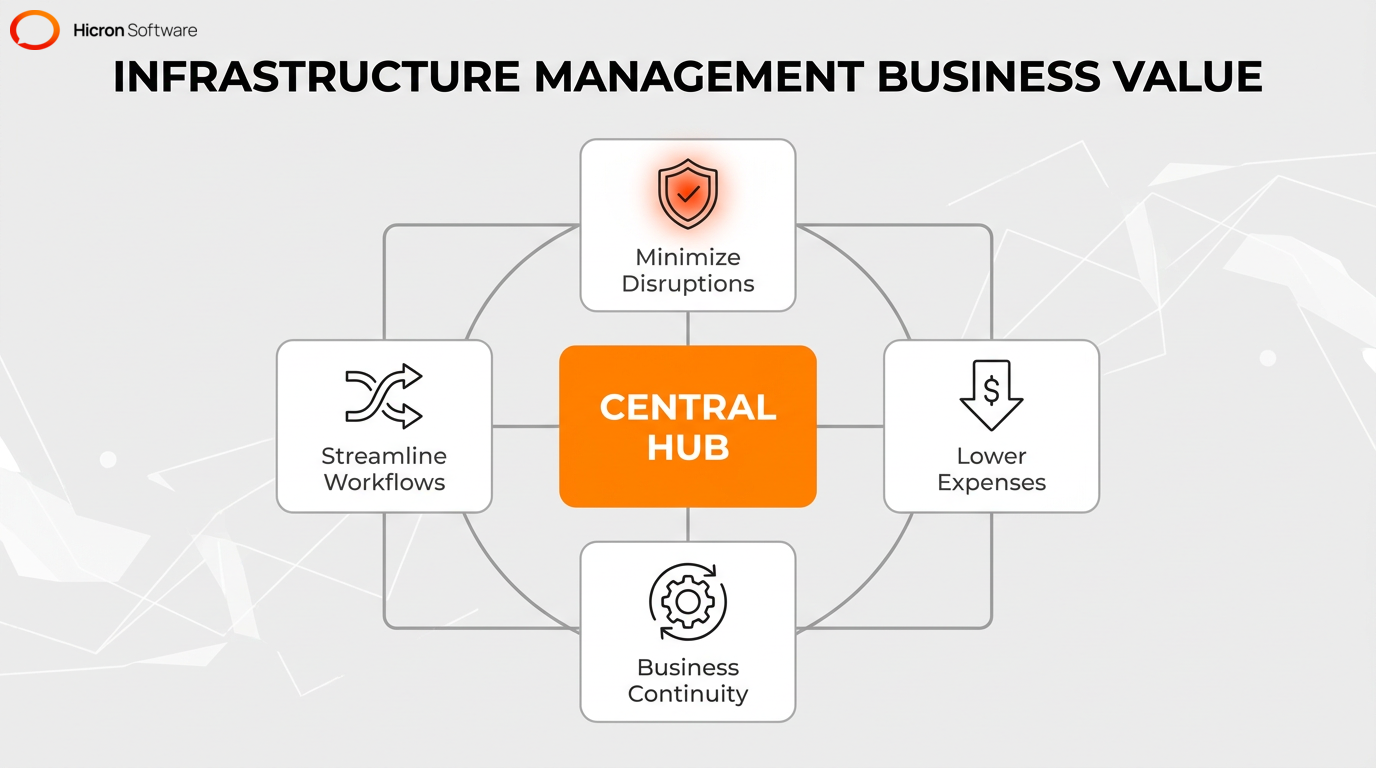
Continuous and proactive performance monitoring maximizes uptime and system reliability by detecting potential issues early. This strategy prevents system downtime by resolving anomalies before costly operational disruptions occur. Administrators typically track system health through monitoring tools and log management.
This analysis ensures hardware isn’t wasted and strengthens problem management. Integrating automation streamlines routine tasks to reduce manual errors during incident management.
You can’t scale your IT if you aren’t using your current resources efficiently, which ensures systems grow without interruption. Optimizing current assets through continuous performance monitoring is necessary before scaling to prevent bottlenecks during periods of growth. Capacity planning determines the exact IT resources required to meet future demands and avoid overspending. This analysis connects current system performance with future requirements to balance resource availability with cost-effectiveness.
To optimize allocation, administrators focus on server consolidation, storage, and network management. These practices optimize system performance.
Cloud computing shifts how teams manage infrastructure by introducing new deployment models and environments. This transformation requires administrators to adapt their strategies to oversee both on-premises and external cloud resources effectively.
A hybrid cloud integrates on-premises systems with cloud resources, whereas a multi-cloud uses services from multiple distinct public cloud providers. Hybrid cloud environments connect local infrastructure with external platforms to optimize data center operations. This architecture secures sensitive data on-premises while using external cloud computing power. Multi-cloud environments deploy assets across two or more third-party providers (such as AWS and Google Cloud) to enhance scalability and prevent vendor lock-in.
These distinct structures demand end-to-end cloud infrastructure management to maintain performance, and modern management solutions unify oversight across both on-premises and cloud-based systems in a hybrid setup. As a result, centralized administration maximizes resource utilization across all distributed environments.
IaaS, PaaS, and SaaS are three distinct cloud computing models delivering varying levels of virtualized IT services, such as infrastructure provisioning, platform hosting, and software delivery. IaaS provides virtualized computing resources over the internet. This model grants administrators maximum control over hardware management involving virtualized devices, such as servers and storage networks. Teams execute rapid provisioning to ensure resources aren’t wasted.
PaaS offers hardware and software tools typically needed for application development, such as operating systems and database environments. By restricting underlying infrastructure control, PaaS allows developers to focus strictly on coding.
SaaS delivers software applications over the internet on a subscription basis, such as communication platforms and enterprise tools. Because it provides the least administrative control, users only perform basic software management tasks, such as user access adjustments and data configuration. The SaaS provider handles all underlying infrastructure management, allowing internal IT teams to focus on integrating the software with broader business workflows. This division of responsibility guarantees smooth growth.
When it comes to standardizing IT services, ITSM and ITIL 4 are the go-to frameworks. These structured methodologies design, deliver, and manage technology to align directly with business objectives.
ITSM standardizes IT operations by connecting technology investments with overarching enterprise goals to ensure value delivery. ITIL 4 operates as a best-practice framework for service delivery. Infrastructure management provides the foundation for broader ITSM processes to ensure uninterrupted service. These integrated practices guarantee business continuity.
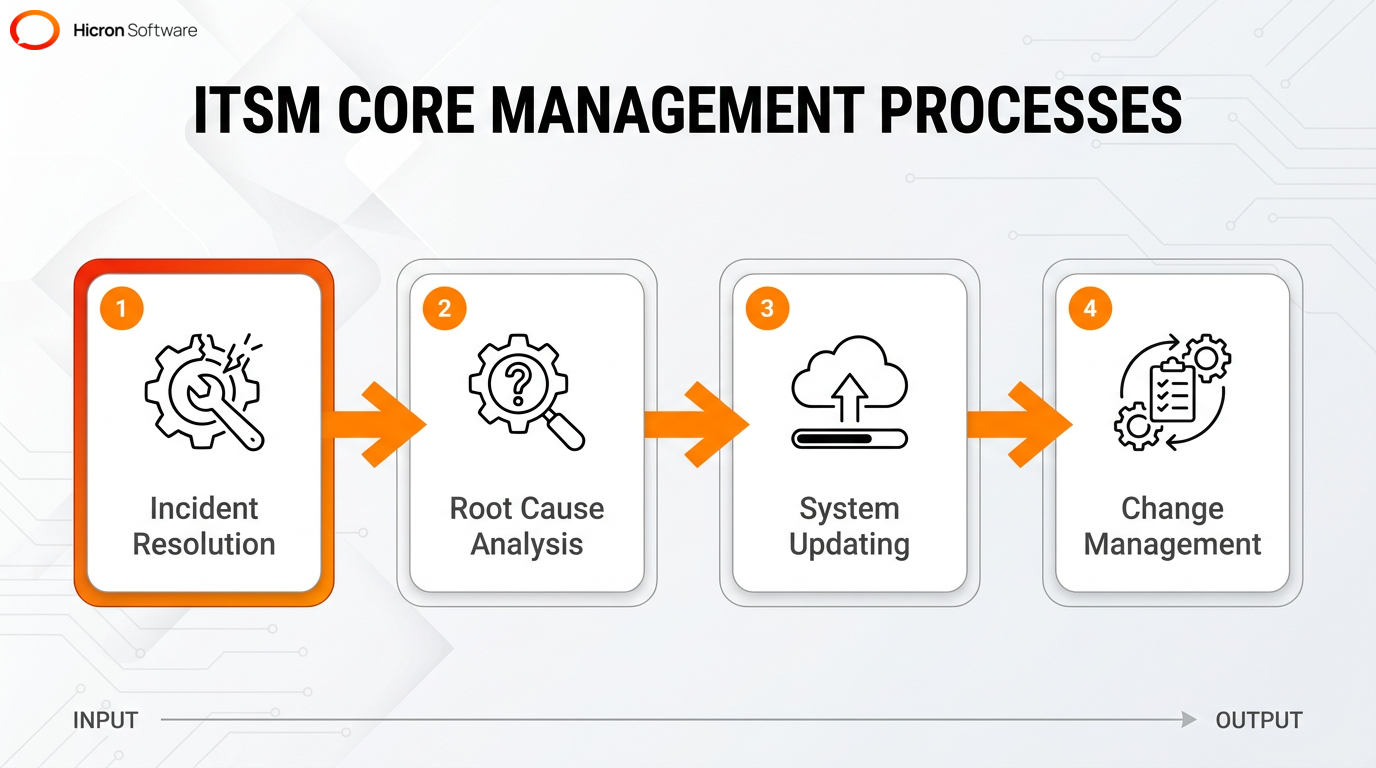
IT service management (ITSM) and ITIL 4 help IT teams work better with the rest of the business by establishing clear, standardized processes. ITSM provides a structured way to manage the entire lifecycle of IT services, ensuring technical capabilities actually meet user needs. Meanwhile, ITIL 4 modernizes these operations, offering a flexible system that focuses on continuous improvement rather than rigid rules. While these frameworks might sound overly bureaucratic at first glance, they are absolute lifesavers when things go wrong.
When users report errors, incident and problem management help resolve root causes rapidly. Additionally, implementing change and configuration management minimizes deployment risks when administrators update infrastructure components. These frameworks streamline IT workflows and safeguard business continuity. Using these practices helps administrators eliminate unexpected downtime and performance degradation.
Incident, problem, and change management are core ITSM processes. They focus on incident resolution, root cause analysis, and system updating, respectively. Each methodology differs significantly in its primary objective. Incident management focuses on resolving an IT disruption to restore normal operation quickly. This discipline operates as a core process within the ITSM framework, supported by solid infrastructure management to keep systems online.
While problem management investigates the underlying root cause of a recurring incident, change management controls the lifecycle of system modifications to minimize disruption risks. A system administrator uses configuration management to track network adjustments, which keeps the network stable and predictable. Integrating this methodology strengthens disaster recovery planning.
Optimizing performance generally comes down to continuous monitoring, efficient resource allocation, and system standardization.
Network management prevents data bottlenecks. Using network optimization strategies, such as load balancing and efficient routing protocols, ensures smooth data delivery across a complex environment.
Load balancing distributes this traffic evenly to prevent server overload during sudden spikes.
Beyond network optimization, addressing legacy system compatibility through a phased upgrade modernizes outdated technology without causing severe service disruptions. This gradual modernization supports long-term scalability.
Proactive performance monitoring shifts IT operations from reactive troubleshooting to proactive health tracking. By relying on advanced tools like network analyzers and server dashboards, administrators can detect anomalies and resolve potential issues before they escalate into costly outages.
Administrators deploy monitoring tools to gain real-time visibility into asset behavior, detect anomalies early, and maintain operational stability. To maintain this visibility, teams typically integrate log management, network management, and AIOps. This continuous oversight maximizes uptime, reduces waste, and streamlines daily tasks.
Log management and monitoring tools (such as SolarWinds and Zabbix) detect anomalies by continuously collecting and analyzing system-generated data for irregular patterns. This process aggregates log files from various network devices, such as routers and switches, to maintain network security. Think of a log file as an airplane’s black box or a detailed digital receipt. It’s recording every single event, error, and transaction that occurs on a server, giving administrators a precise, second-by-second timeline to investigate when something goes wrong.
By analyzing this information, administrators can detect security breaches and optimize traffic flow during data congestion. Continuous data analysis ensures regulatory compliance and monitors system health. When you integrate log management with routine vulnerability assessments, you strengthen advanced cybersecurity, preventing operational disruptions and keeping the network healthy.
Configuration management enforces standardization by maintaining IT systems in a consistent, desired state across a deployed platform. Standardizing system settings prevents configuration drift and minimizes deployment errors. This process defines a stable baseline for all IT assets to reduce complexity and simplify maintenance. Administrators enforce this by standardizing hardware, software, and configurations across the environment.
By maintaining a stable IT baseline, standardization makes troubleshooting faster and deployments far more reliable. When an enterprise rolls out changes, this consistency ensures systems remain in their desired state. And when you pair this standardization with automation, you not only lock in strict security compliance but also drastically reduce the chances of unexpected downtime. Combining configuration management with asset management aligns with IT service management frameworks to ensure uninterrupted service delivery.
Automation transforms IT infrastructure by handling repetitive tasks, reducing human error, and significantly increasing operational speed and accuracy. Automating these tasks primarily leads to accelerated deployment, enhanced security, and a lighter manual workload. This transformation occurs by streamlining routine IT tasks, such as rapid provisioning, systematic patch management, and automated backup and recovery.
Automation tools frequently handle patch management to improve security and stability against emerging vulnerabilities. Implementing Infrastructure as Code (IaC) standardizes system setups by replacing manual hardware setup with machine-readable definition files. This approach integrates smoothly with configuration management to maintain consistent environments across deployed platforms. Integrating automation within DevOps and CI/CD pipelines accelerates software delivery when development teams release frequent updates.
Delegating manual maintenance to software scripts frees up IT staff to focus strictly on strategic initiatives, such as architecture modernization and long-term capacity planning. Advanced platforms use AIOps to analyze system data and resolve performance issues instantly. This continuous optimization ensures no compute power is wasted across the entire technology ecosystem. These automated frameworks guarantee high accuracy and business continuity.
Automation platforms enable IT teams to automate the provisioning and management of infrastructure across a cloud environment. Administrators generally rely on IaC, containerization platforms, and orchestration tools to implement this automation. IaC defines resources across major cloud providers (like AWS and Google Cloud).
For example, Terraform handles infrastructure provisioning using a declarative configuration language, while containerization platforms like Docker ensure consistent application deployment. When it’s time to scale, orchestration tools like Kubernetes take over. Together, this technology integrates with configuration management to maintain continuous stability.
Securing an IT environment requires a multi-layered approach involving continuous vulnerability assessments, strict access controls, and regular patch management. Foundational security relies on strong protocols, IAM, and routine assessments. Management involves implementing security protocols and ensuring strict compliance to protect sensitive data. Integrating these cybersecurity practices into daily infrastructure management secures physical and virtual assets, such as local servers and cloud databases, across data center operations.
While network security defends communication channels against external threats, adhering to regulatory standards ensures compliance across deployed platforms. Detailed disaster recovery planning guarantees rapid system restoration, creating a strategic approach that maintains business continuity.
Think of vulnerability assessments as finding the holes in your fence, while patch management is the process of actually fixing them with necessary system updates. This combined approach reduces risk by continuously discovering and fixing exposures. Effective software management ensures that operating systems, such as Windows and Linux, remain secure and updated.
Administrators use automation to ensure patches roll out without manual intervention. Integrating automated deployment with log management strengthens network security and advanced cybersecurity. This continuous cycle guarantees regulatory compliance, improves risk management, and strengthens system resilience.
Identity and access management (IAM) protects networks by ensuring that only authorized individuals or systems access specific IT resources. Controlling user access minimizes the risk of internal or external data breaches. This discipline enforces the principle of least privilege across both network and cloud infrastructure management.
To strengthen cybersecurity, administrators control user authentication and authorization across the entire IT ecosystem. By integrating IAM systems with log management, teams can track user activity and quickly detect unauthorized access attempts from malicious actors. Not only does this continuous tracking support routine vulnerability assessments for strict regulatory compliance, but enforcing these access controls also secures the environment and aligns perfectly with IT service management frameworks.
The primary goal of disaster recovery planning is to restore critical IT systems (such as enterprise databases and communication networks) and data swiftly following a disruptive event. This strategy prepares an organization for unforeseen events like cyberattacks, hardware failures, or natural disasters. Administrators conduct a business impact analysis to prioritize critical business functions, such as transaction processing and client communication, and maintain overall business continuity. I can’t stress this enough: a disaster recovery plan is only as good as your last successful test of it.
An IT infrastructure manager oversees the creation and testing of recovery protocols, such as automated failover and data restoration, which integrates strict risk management with data center operations to keep systems running. During severe outages, IT teams execute systematic backup and recovery alongside advanced cybersecurity to protect digital assets. To ensure a rapid response, effective IT infrastructure management aligns this planning with incident management, while administrators use advanced storage management to secure redundant data across distributed repositories.
Reliable backup and recovery processes ensure business continuity by preventing permanent data loss and minimizing system downtime. This component of disaster recovery planning establishes critical metrics like recovery point objectives (RPO) and recovery time objectives (RTO), which define acceptable downtime limits. Administrators execute secure data duplication across diverse environments, such as physical data center operations and cloud computing platforms, to strengthen risk management.
Advanced storage management uses automation to synchronize off-site storage continuously. Regular testing of these systems guarantees successful data restoration. This strategy minimizes the time your business is offline and restores normal business functions rapidly.
An IT infrastructure manager provides strategic oversight, design, maintenance, and security for an organization’s entire technology ecosystem and personnel. Core duties typically include executing IT strategy, managing vendor contracts, ensuring cybersecurity, and overseeing disaster recovery. Executing this strategy requires strict lifecycle control over physical and digital resources. The manager uses hardware management and network management to maintain operational stability.
They also manage vendor relationships and contracts to ensure cost-effective resource acquisition. By overseeing the creation and testing of disaster recovery protocols, they protect critical data during unexpected system failures. The manager ensures team coordination by maintaining updated documentation of assets and strategies, which supports capacity planning to optimize system performance. Integrating IT service management standards aligns daily technical operations directly with overarching enterprise objectives.
Managing a modern IT environment often involves overcoming hurdles like integrating outdated technology, unifying distributed platforms, and mitigating security risks. Addressing legacy system compatibility presents a significant hurdle. We’ve all encountered that one ancient server sitting in a closet that everyone is afraid to turn off. Strong management focuses on virtualizing older infrastructure to remove performance bottlenecks. This strategy involves executing a phased upgrade to modernize legacy systems without causing operational disruptions.
Unifying oversight across a distributed architecture creates administrative difficulties. Administrators face significant challenges monitoring on-premises systems and cloud-based platforms simultaneously. Centralizing control across a hybrid cloud and a multi-cloud requires advanced configuration management to maintain consistent settings. Preventing performance bottlenecks becomes increasingly complex as data streams and resource demands grow. Teams manage resources efficiently and use network management to support continuous scalability during unexpected data traffic spikes.
Mitigating security threats requires continuous vigilance across an integrated platform. Managing this risk demands routine vulnerability assessments to identify hidden flaws. Administrators integrate advanced cybersecurity to protect sensitive assets across an expanding attack surface. This continuous effort maintains system stability and supports uninterrupted growth.
Emerging trends in IT infrastructure management focus heavily on increased automation, artificial intelligence, and decentralized processing to handle growing data demands, driven by technologies like AIOps, edge computing, hyperconverged infrastructure, and Infrastructure as Code.
Implementing Infrastructure as Code (IaC) across cloud computing environments accelerates automation. These integrated advancements keep systems running at their best.
AIOps uses artificial intelligence and machine learning to analyze vast operational data, identifying patterns that precede system failures. Artificial intelligence improves proactive monitoring by automating complex IT operations and detecting anomalies before outages occur. Integrating this automation enhances continuous performance monitoring by predicting issues before they impact system uptime. Administrators typically use AIOps to analyze data from log management systems and network sensors.
This predictive insight allocates resources dynamically to prevent severe bottlenecks. Identifying threats early strengthens incident management by shifting strategies from reactive recovery to proactive prevention. This predictive capability maximizes system resilience during sudden demand spikes.
Edge computing manages distributed data by relocating processing power closer to the data source rather than centralizing data center operations. This distributed computing model manages massive data streams generated by IoT devices, such as smart sensors and industrial monitors. Pushing computational tasks to the network edge primarily reduces latency and minimizes bandwidth usage.
A hybrid cloud incorporates edge computing to balance local processing and remote cloud computing. This integration makes better use of available hardware and improves network management. Balancing this architecture optimizes processing speeds and ensures continuous scalability.
Hyperconverged infrastructure (HCI) is a software-defined system that unifies physical components into a single, easily managed appliance. This technology simplifies data center operations by consolidating traditional IT silos. HCI uses virtualization to abstract resources across hardware, network, and storage management. Administrators execute server consolidation to reduce hardware footprint.
Integrating compute, storage, and virtualization into a single appliance reduces management complexity significantly. This approach significantly enhances scalability. Teams expand environments through modular additions.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
