11 DevOps Automation Tools to Streamline Your Workflow
- May 21
- 10 min



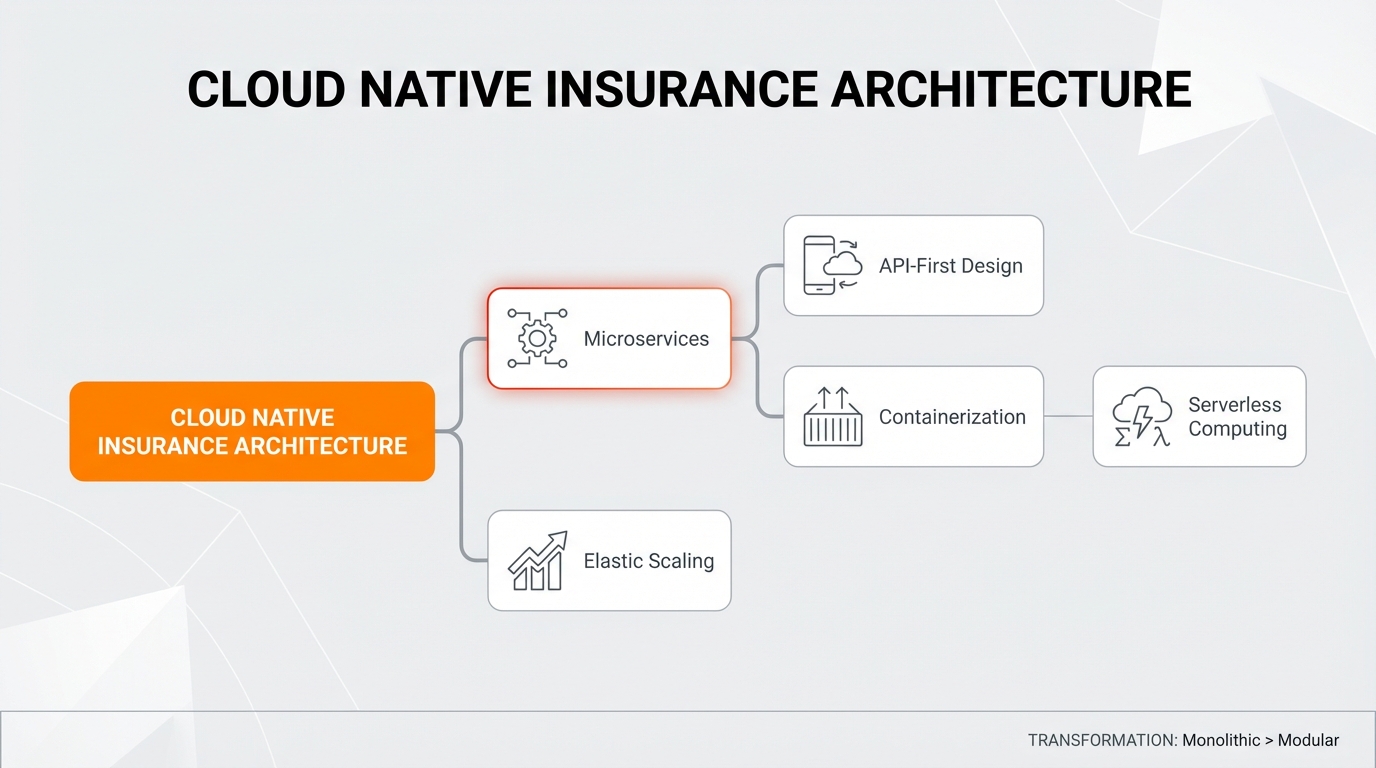
Moving to a cloud-native insurance architecture means abandoning rigid, on-premise monoliths for flexible, modular systems. It’s a shift that builds highly agile and resilient environments. At the heart of this infrastructure are a few essential building blocks:
Digital transformation in the insurance sector depends on this transition. Cloud platforms scale elastically, directly solving legacy limitations like slow deployment cycles and high maintenance costs. To process real-time policy data, engineering teams use event-driven architectures. This ensures the ability to handle sudden surges in traffic under varying workloads, such as sudden claims processing spikes or seasonal policy renewals.
|
Component / Strategy |
Description & Function |
Insurance Industry Benefit |
|
Microservices Architecture |
Splits monolithic systems into independent, autonomous services using domain-driven design (DDD). |
|
|
Event-Driven Architecture |
Uses data state changes as triggers for real-time processing and continuous event streaming (e.g., Apache Kafka). |
|
|
Containerization & Kubernetes |
Packages isolated software components into portable units and automatically handles deployment, scaling, and self-healing. |
|
|
Serverless Computing |
Executes code on-demand for sporadic, resource-heavy tasks instead of paying for idle servers. |
|
|
API-First Design |
Treats APIs as primary products to decouple backend core logic from frontend experiences. |
|
|
Strangler Fig Pattern |
Intercepts backend calls through an API gateway to gradually route traffic from legacy components to modern distributed systems. |
|
|
Data Mesh |
A decentralized architecture that gives ownership of data back to specific business domains, treating data as a product. |
|
|
DevSecOps & Zero-Trust |
Integrates automated vulnerability scanning into CI/CD pipelines and authenticates every request while encrypting data. |
|
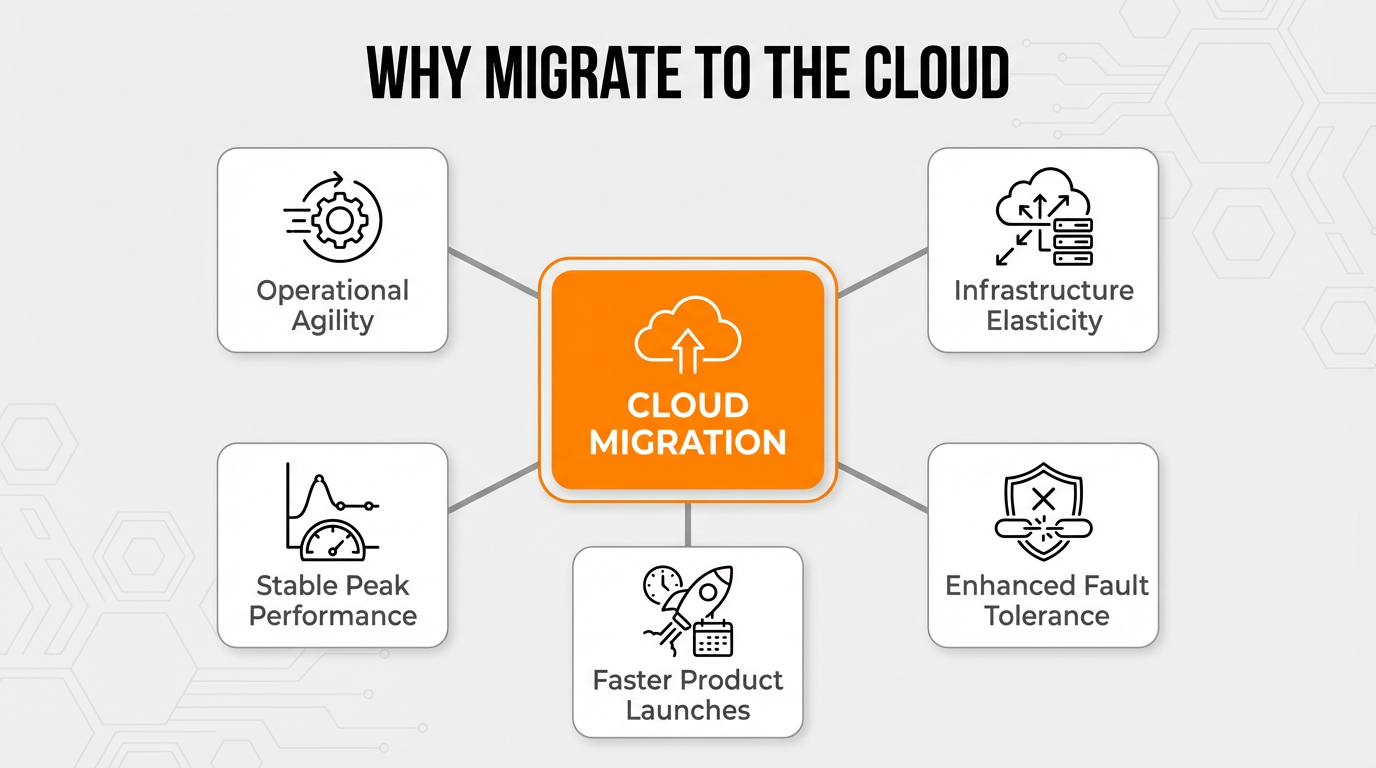
Traditional monolithic systems slow down product launches and stifle innovation. Moving to the cloud removes these roadblocks by unbundling the architecture. Why make the leap? It usually comes down to three things:
Old monolithic systems hold companies back. If you’ve ever held your breath during a weekend deployment, you know exactly how stressful this tangled web can be. Because everything is tangled together, you can’t easily update one piece without breaking another across core operations, including policy administration systems, underwriting modules, and claims processing frameworks.
Insurers often set up a hybrid IT estate to maintain operational continuity while shifting workloads to distributed environments. By using cloud scalability, companies keep system performance stable during peak usage periods.
How do you keep a massive insurance platform running smoothly? You break it into pieces. Developers use domain-driven design to align software components with specific functions, such as:
The CQRS pattern separates read and write operations to optimize performance. Think of it like a restaurant kitchen: the waiters taking new orders (writes) don’t stand in the same line as the food runners picking up finished dishes (reads). I’ve found this restaurant analogy is usually the exact “aha” moment for non-technical stakeholders trying to understand the value of decoupling. This separation keeps customer dashboards loading instantly without bogging down the core systems processing new policies. To make this setup work in the real world, engineering teams use API-first design principles to ensure smooth data flow. As a result, a cloud-native architecture maintains high availability even when individual modules experience sudden workload spikes.
Instead of running a massive, interconnected application, developers split the system into independent, autonomous services. Breaking things down like this gives you three big wins: independent scalability, rapid software updates, and specialized data management.
With Domain-driven design (DDD), developers build software that mirrors the actual business, creating separate modules for areas such as automated underwriting engines, claims processing workflows, and customer service portals. A cloud-native approach ensures that core policy administration systems remain online and functional, even if individual backend components fail during peak renewal periods.
Event-driven architectures use data state changes as triggers for real-time processing. It’s a setup that keeps everything moving instantly alongside microservices. Distributed systems manage continuous event streaming and real-time ingestion through specialized platforms like Apache Kafka and Amazon Kinesis. This configuration integrates with IoT sensors and telematics to power innovative products, including usage-based auto policies and dynamic pricing models.
Advanced analytics trigger automatic payouts for parametric insurance based on external data, such as severe weather patterns or flight cancellations. By combining API-first design with serverless computing, the platform easily handles high-volume data spikes, like a sudden influx of claims after a storm, without performance degradation.
Kubernetes serves as the standard for orchestrating containerized insurance workloads by handling deployment, scaling, and self-healing automatically. The platform automates the lifecycle management of a microservices architecture. Containerization packages isolated software components, like rating engines and customer portals, into portable units.
Kubernetes provides a consistent orchestration layer across diverse infrastructure models, including hybrid IT estates and multi-cloud strategies. Distributed systems stay highly available and grow on demand when engineering teams use infrastructure as code (IaC) for cluster configuration.
Instead of paying for idle servers, insurers can use serverless computing to execute code on-demand for sporadic, resource-heavy tasks. Insurers typically apply serverless functions to tasks like on-demand data processing, real-time pricing engines, and document OCR. This model reduces operational costs while ensuring the ability to scale instantly.
Integrating serverless computing with an event-driven architecture helps distributed systems maintain high reliability. Because of this, a cloud-native platform achieves smooth real-time data processing alongside its microservices. An API-first design acts as the connective tissue, allowing these serverless functions to communicate securely with the rest of the microservices architecture.
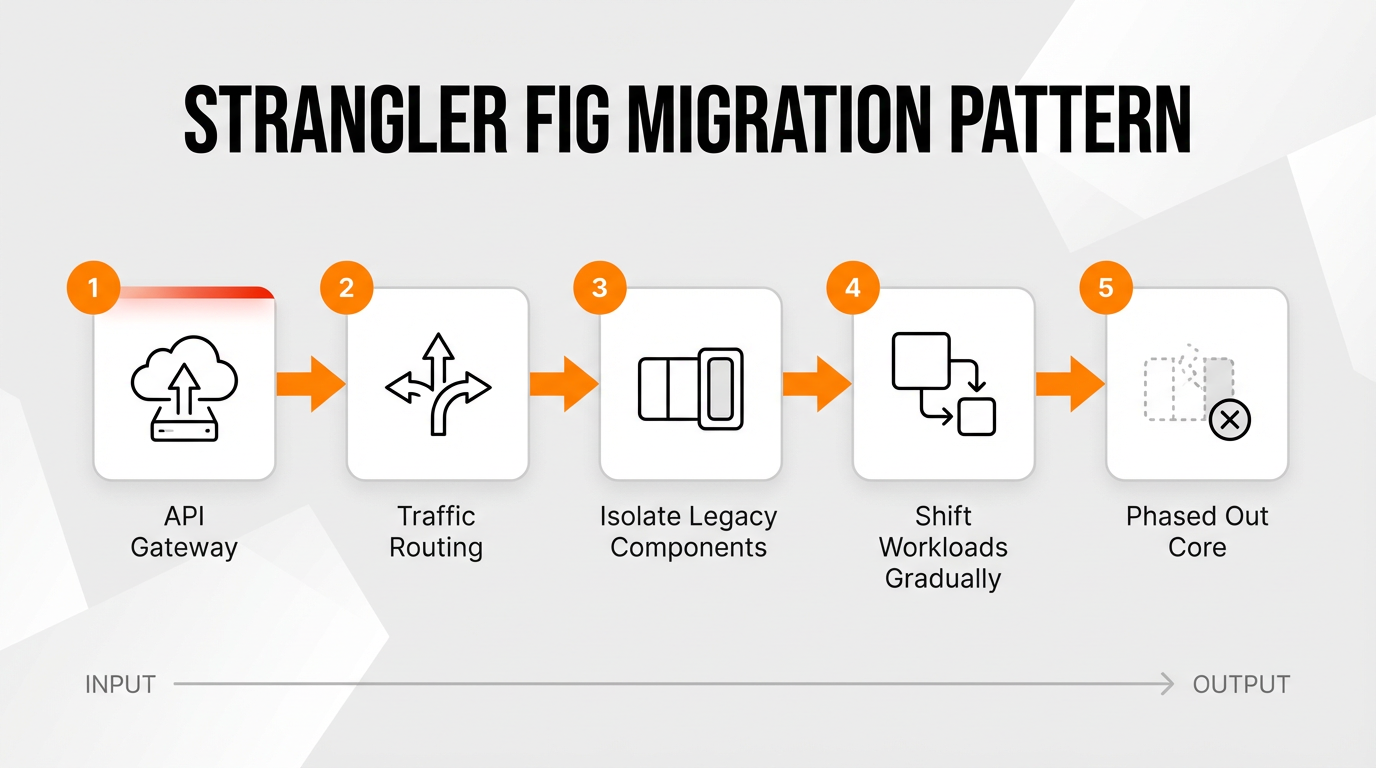
The most effective and least risky strategy for modernizing a legacy platform is a phased approach that safely transitions operations from rigid on-premise infrastructure to a flexible, modular environment. This method mitigates operational risk by avoiding a sudden overhaul of critical systems, such as mainframe-based underwriting platforms and on-premise billing databases. From my experience in the trenches, trying to rip and replace everything at once is a guaranteed recipe for disaster. Engineers generally rely on a couple of proven methods to unbundle a monolithic core during cloud migration: the Strangler Fig pattern and API Wrapping.
By implementing an API-first design, an IT department maintains a stable hybrid IT estate during the transition. This phased migration allows companies to advance their digital transformation safely, preserving continuous operations while achieving room to grow.
The Strangler Fig pattern reduces the risk of “big bang” system replacements by doing two things: intercepting backend calls through an API gateway and routing traffic to modern distributed systems. Breaking the monolith into a microservices architecture serves as the core technical strategy here. Policy administration systems maintain continuous operations because developers isolate specific legacy components.
Cloud migration advances safely as engineering teams shift workloads gradually. The new cloud-native architecture keeps the system stable and responsive while the outdated core is slowly phased out.
During a cloud migration, API wrapping bridges the gap between outdated monolithic cores and cloud-native architectures by exposing legacy policy administration systems to modern digital interfaces. Insurers use it to integrate older platforms with modern digital channels, such as new frontend experiences and insurtech integration platforms.
An API gateway manages the data connection between the old backend and a new microservices architecture. By implementing an API-first design, engineering teams extend the utility of existing legacy investments. This gradual modernization allows developers to update the backend without disrupting the customer-facing experience.
When migrating to the cloud, insurers generally choose from three infrastructure models: hybrid IT estates, multi-cloud strategies, and software as a service (SaaS). Insurers use this strategic mix to balance security, regulatory compliance, and scalability needs.
Regardless of whether an insurer chooses a hybrid or multi-cloud path, managing these diverse environments requires specialized tools. Kubernetes acts as the traffic cop, ensuring applications run smoothly across different clouds, while Infrastructure as Code (IaC) allows teams to automate and scale these complex setups reliably.
A hybrid IT estate serves as a transitional model during cloud migration. It keeps sensitive policyholder data secure on-premise while using public cloud environments for scalable workloads. Insurers frequently choose this path to manage data sovereignty alongside the need to scale quickly. Cloud-native systems allow organizations to maintain control over encryption and access on private clouds to meet regional data laws. Distributed systems allocate tasks based on security needs and computing demands.
To secure this hybrid setup, insurers implement zero-trust security, which authenticates every request regardless of where it originates. Kubernetes helps enforce these strict security policies consistently across both on-premise servers and public clouds.
A multi-cloud strategy prevents vendor lock-in and allows insurers to take advantage of optimal features, resilience, and pricing from different cloud providers. A cloud-native architecture enables companies to switch providers for better pricing or specific capabilities without rewriting core logic.
Deploying a microservices architecture across multiple environments helps distributed systems maintain high performance under load. Kubernetes orchestrates containerization efforts across these diverse platforms to guarantee efficient resource allocation. Engineering teams automate these complex deployments across multiple providers by using infrastructure as code (IaC).
Software as a service (SaaS) optimizes a modern IT estate by providing ready-to-use applications that reduce infrastructure management and accelerate speed to market. This deployment model supports cloud migration by shifting non-differentiating capabilities to managed services, such as standard policy administration systems, routine claims processing, and basic underwriting workflows. Insurers achieve rapid deployment and reduced IT overhead by relying on these third-party platforms.
SaaS models accelerate the launch of new products, like usage-based auto coverage and parametric weather policies, by removing the need for backend infrastructure management. Connecting these managed services using an API-first design ensures the platform maintains the ability to handle growth. Building on these cloud environments allows insurers to easily plug in third-party insurtech solutions, such as AI-driven fraud detection APIs or automated property valuation tools.
API-first design treats APIs as primary products that decouple backend core logic from frontend experiences to accelerate digital transformation. Developers isolate specific core operations, including policy administration, claims processing, and underwriting modules. If you want to embed insurance products into external platforms, this approach isn’t just helpful. It’s required.
External platforms, such as car-buying websites and real estate portals, benefit greatly from this architecture. Direct connectivity with third-party platforms brings two major benefits to the table: open insurance expansion and rapid insurtech integration. An API gateway manages secure data routing between these external partners and internal distributed systems. Deploying a cloud-native architecture alongside these decoupled interfaces gives legacy insurers the technical foundation they need to scale rapidly and partner with modern digital ecosystems.
Standardized APIs act as the connective tissue for open insurance, enabling insurtech integration and embedded insurance models like retail warranties and travel coverage. This API-first design expands the traditional ecosystem by powering the mechanics of embedded insurance at the point of sale through digital partnerships with e-commerce platforms and banking apps.
Traditional insurers participate in this broader network by using an API gateway to easily swap third-party services, such as AI analytics and fraud detection mechanisms, in and out of their core workflows. Companies achieve high capacity and real-time data processing by deploying distributed systems, like rating engines and billing modules, within a cloud-native architecture. This modular approach allows insurers to continuously upgrade their fraud detection or analytics capabilities without rebuilding their core systems.
Effective data management across decoupled microservices requires decentralized architectures to ensure isolation and efficiency. Teams usually rely on two main frameworks to make this work: data mesh and polyglot persistence. Polyglot persistence allows each component within a microservices architecture to use different database technologies based on specific data needs.
Engineering teams use purpose-fit datastores, like relational databases for policy records and NoSQL for telemetry data. To keep information synchronized across these isolated databases without creating tight dependencies, developers rely on event-driven architectures. This setup not only powers real-time analytics but also ensures the platform stays fast and responsive during complex queries.
A data mesh gives ownership of data back to specific business domains. This drastically improves how fast and accurately teams like underwriting and claims processing can run analytics. I’ve seen firsthand how giving a claims team direct control over their own data pipelines completely transforms their daily operations. Domain-driven design (DDD) structures this framework by assigning data control directly to the relevant department. Within this distributed system, insurers treat data as a product rather than a byproduct.
This strategy improves data management and accelerates critical analytical capabilities, including predictive modeling and automated decision-making. When engineering teams implement this model alongside a microservices architecture, the platform remains highly responsive during complex query execution. Decentralized units execute real-time data processing independently to evaluate changing risk profiles instantly.
Engineers use Apache Kafka as the standard distributed event-streaming platform to ingest real-time data and decouple microservices. The platform acts as the core ingestion layer for continuous data pipelines that feed into critical components, such as analytics engines and usage-based models.
Event-driven architectures improve system resilience by isolating data producers from consumers. By using Apache Kafka to manage high-volume workloads, engineering teams ensure distributed systems don’t crash under pressure. Integrating this streaming technology with an API-first design allows the platform to achieve real-time data processing.
Modern cloud environments embed defensive mechanisms directly into the infrastructure rather than bolting them on as an afterthought. The most critical components include automated configuration validation, a zero-trust security model, and an immutable audit log. Distributed systems manage security effectively by automating adherence to major regulatory frameworks like GDPR and DORA. Engineering teams use specific validation methods, such as policy-as-code and immutable audit trails, to provide the exact traceability that regulatory authorities require.
A DevSecOps pipeline integrates this process natively within a microservices architecture. To take it a step further, the IT department implements advanced observability software, ensuring strict data sovereignty and full auditability across a hybrid IT estate. During cloud migration, infrastructure as code (IaC) standardizes secure cluster configurations across the entire network. Ultimately, maintaining these automated compliance protocols guarantees continuous protection against external intrusion.
Instead of treating security as an afterthought, DevSecOps bakes it right into the CI/CD pipeline by integrating automated vulnerability scanning. Let’s be honest, catching a critical security flaw the day before a major launch is a nightmare no development team wants to experience. This shift-left approach guarantees continuous security enforcement before code reaches production. The pipeline automatically enforces specific regulatory standards across distributed systems.
These standards include GDPR data privacy rules and zero-trust security policies. By using infrastructure as code (IaC), engineering teams standardize these checks across the entire microservices architecture, ensuring no deployment bypasses the rules. Integrating advanced observability tools into this automated delivery cycle ensures the platform maintains strict regulatory compliance.
Zero-trust security is a critical framework for protecting sensitive policyholder data in distributed cloud environments. It operates on a simple principle: “never trust, always verify.” Insurers adopt this model to guarantee regulatory compliance across diverse infrastructure setups, including hybrid IT estates and multi-cloud strategies. The system maintains security by authenticating every request and encrypting data at rest and in transit across the service mesh.
Routing internal traffic through an API gateway achieves continuous protection for the platform. By integrating DevSecOps practices, developers ensure distributed systems maintain strict data isolation across the microservices architecture. Plus, deploying advanced observability tools allows network administrators to detect unauthorized access instantly.
Modern development practices build resilient systems capable of elastic scaling, rapid recovery, and zero-downtime deployments. Building these resilient systems usually comes down to three main practices: CI/CD pipelines, infrastructure as code (IaC), and observability.
Kubernetes orchestrates the microservices architecture to guarantee high availability when developers deploy these automated configurations. Integrating these monitoring capabilities with DevSecOps workflows ensures the platform stays online and handles growth effortlessly.
CI/CD pipelines accelerate software delivery by automating the testing and deployment of code. The process relies on two main workflows, continuous integration and automated deployment, to reduce the time from code commit to production release. This architecture enables faster updates for specific components, such as new features and rating algorithms, without disrupting core services.
Since microservices are isolated, teams can push new features through CI/CD pipelines without worrying about taking down the whole system. When paired with automated infrastructure (IaC) and DevSecOps, this drastically shortens the time to market for new rating algorithms or customer portal updates.
Infrastructure as code (IaC) maintains environment consistency through version-controlled code, while observability provides deep insights to detect and resolve issues proactively. GitOps and IaC tools, such as Terraform, trigger automated, auditable infrastructure deployments for Kubernetes clusters. Observability speeds up rapid troubleshooting by relying on system monitoring, logging, and tracing.
Using these practices allows the platform to grow seamlessly and avoid downtime. When developers integrate these observability insights with DevSecOps and CI/CD pipelines, distributed systems guarantee overall reliability across the microservices architecture.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
