Building AI Deal Sourcing Tools for Real Estate Brokers Needs
- September 04
- 19 min


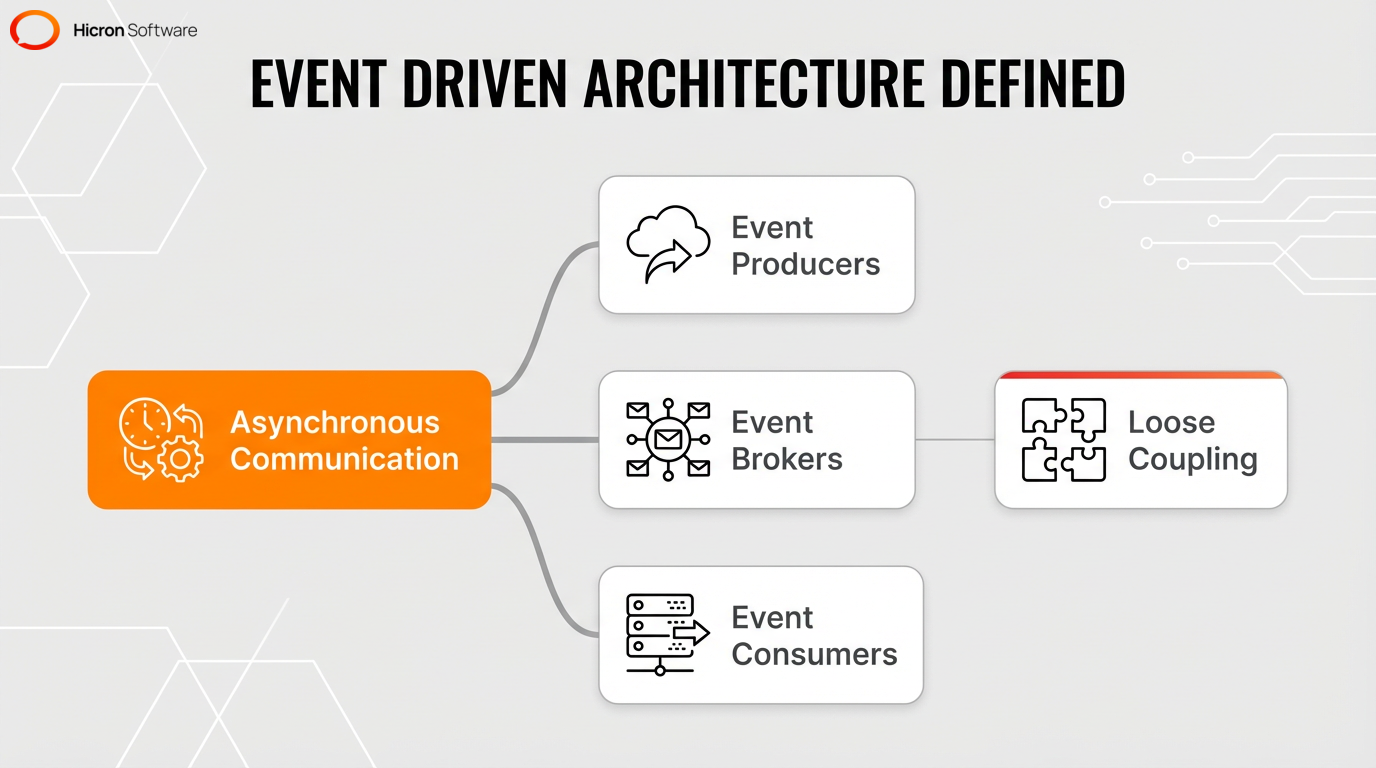
Event-driven architecture (EDA) allows independent system components to communicate by producing and responding to events in real-time. This model shifts systems from periodic data polling to push-based, asynchronous communication, relying on three primary components:
Loose coupling allows systems running on different technology stacks to share information without direct dependencies. These environments span legacy applications, IoT devices, and cloud-native microservices, and this interoperability creates highly decoupled services. By using an event broker for asynchronous communication, the system improves scalability and supports processing data the moment it arrives.
|
Category |
Element |
Description & Function |
|
Core Component |
Event Producer |
|
|
Core Component |
Event Broker |
|
|
Core Component |
Event Consumer |
|
|
Communication Model |
Publish-Subscribe (Pub/Sub) |
|
|
Communication Model |
Event Streaming |
|
|
Design Pattern |
CQRS |
|
|
Design Pattern |
Event Sourcing |
|
|
Design Pattern |
Change Data Capture (CDC) |
|
|
Design Pattern |
Fanout Pattern |
|
|
Design Pattern |
Choreography vs. Orchestration |
|
|
System Challenge |
Eventual Consistency |
|
|
Infrastructure |
Event Mesh |
|
In software architecture, an event represents a significant state change or system update that initiates data exchange between decoupled services. In my experience building distributed systems, getting this definition right early on saves countless hours of debugging later. Think of this change as the system’s basic unit of conversation. Software design differentiates between the actual physical occurrence and the digital notification the system broadcasts. State changes happen continuously during user interactions. Examples include:
Event producers generate these notifications to support asynchronous communication and real-time processing across the infrastructure. Each message contains a specific payload detailing the occurrence. By design, these records act as immutable events, meaning the historical log cannot be altered once written. When event consumers receive these messages, a designated event handler processes the data. It then triggers the next required step. Data architectures frequently implement change data capture (CDC) technologies to identify database modifications and automatically publish these state changes.
An event payload is the data and context that event producers pack into a message. This information travels through message queues or an event broker to reach decoupled services. The payload delivers the exact facts necessary for event consumers and the designated event handler to execute operations. Examples include a purchase price, a customer address, and specific transaction identifiers.
Effective payloads balance two things: they’re lightweight and highly informative. A good rule of thumb I always share with my teams is to only include the data the consumer absolutely needs to do its job. This structure ensures systems can process events instantly and efficiently without unnecessary overhead.
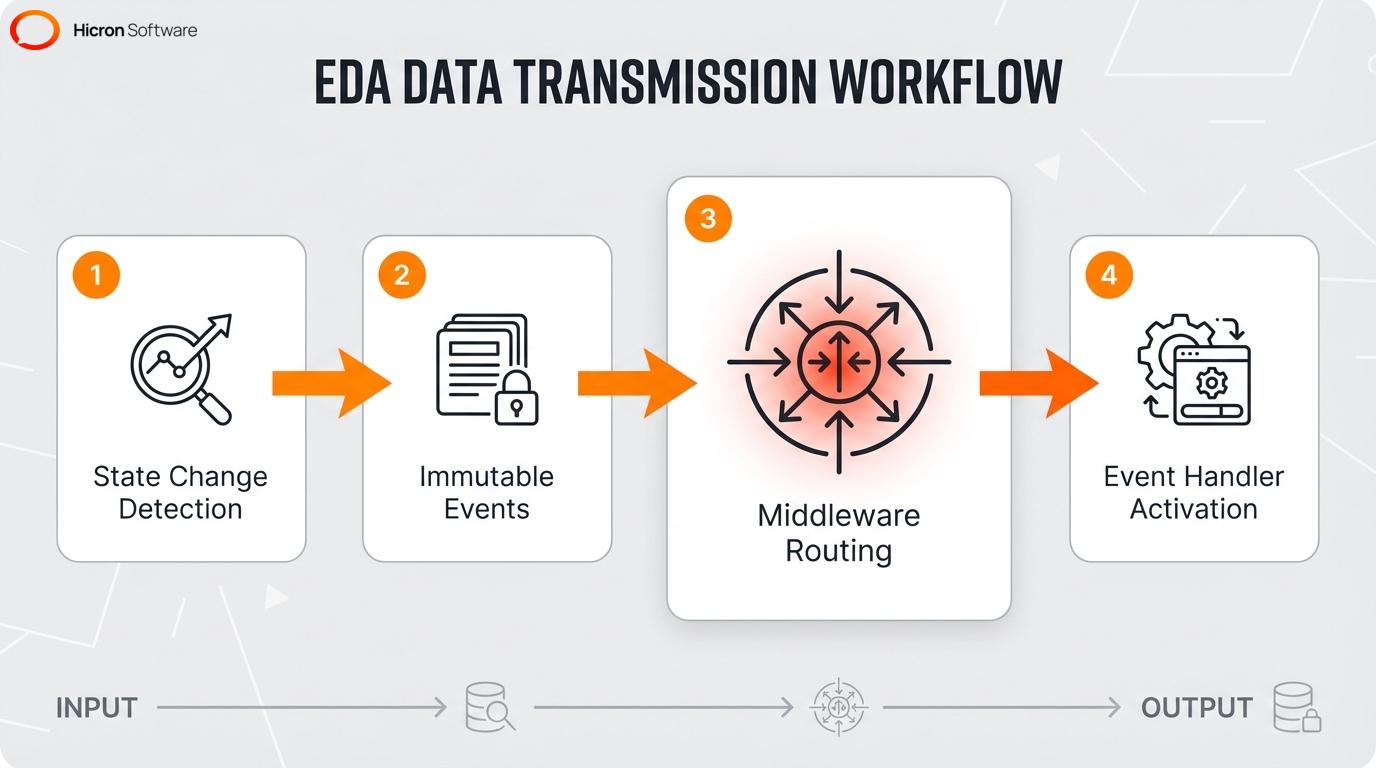
Event-driven architecture relies on a multi-step workflow where several decoupled components work together for data transmission. Middleware components separate the sender from the receiver, which enables asynchronous communication without requiring direct connections between applications.
An event producer is a service, API, or device that detects a system state change and publishes an event notification. Its main job is to generate immutable events, such as a user login record or a transaction log. Event producers represent specific data sources, ranging from an IoT sensor detecting a temperature change to an external application.
The producer handles two main steps: formatting the payload and transmitting it to an event broker or event bus. It operates without knowing the identity of the receiving application, which maintains decoupled services like isolated billing modules and independent inventory trackers. By keeping these elements separate, the architecture supports asynchronous communication within the publish-subscribe model. Systems frequently use change data capture (CDC) to automate this publishing process when database modifications occur.
An event broker functions as the central middleware hub that receives, filters, and routes events from producers to the appropriate subscribers. This middleware manages the data flow between independent systems, such as a fraud detection engine and a customer notification service. The broker uses message queues and event routers to handle this distribution.
Implementing an event bus removes the need for custom routing code within individual applications. This centralized system ensures reliable delivery and simplifies how applications subscribe to data feeds, while the broker acts as a single location to audit application activity and define administrative rules, including global security policies and access controls. Advanced architectures deploy an event mesh to connect services more smoothly if the infrastructure spans multiple cloud regions.
Event consumers are independent applications that listen for specific events and activate a designated event handler to perform their required tasks. These decoupled services use the pub/sub model to subscribe to distinct topics, filtering the exact payload they receive. Upon receiving a notification, subscribers execute specific actions, such as updating a database or sending a confirmation email after a checkout event.
If a consumer is offline or busy, the system simply holds the records in message queues until it’s ready. This asynchronous communication ensures continuous real-time processing and enables parallel processing across the infrastructure.
The fanout pattern is a distribution method where an event broker pushes a single event to multiple consumers simultaneously for parallel processing. These consumers might include a communication module, an analytics engine, and a CRM platform. One event triggers multiple independent processes at once because event routers—such as a topic exchange or a message filter—replicate the original payload for every active subscriber. The producer generates exactly one message, eliminating the need to transmit duplicate records.
Operating within the publish-subscribe (pub/sub) model, this mechanism enhances system scalability and improves efficiency in high throughput environments. During distribution, the architecture keeps systems independent, safely isolating components like recommendation engines from shipping logistics trackers. If a user signup event occurs, the system triggers three distinct actions simultaneously:
Primary communication models in event-driven architecture allow systems to communicate asynchronously across an infrastructure. Both methods use message queues to maintain highly decoupled services and support complex system coordination. Implementing these patterns eliminates the need for continuous polling, which reduces strain on the network.
The publish-subscribe model enables event producers to broadcast a message to a shared channel, allowing senders and receivers to interact without a direct connection because the central middleware tags an event with a specific topic. This pub/sub mechanism allows the event broker or an event bus to identify the exact payload category. The system then routes this data to event consumers, such as an analytics engine or a database, based on their active subscriptions.
A subscriber receives only the precise record matching its interest and ignores all other network traffic. This filtering supports asynchronous communication while preserving completely decoupled services, like a payment processor or a notification module. While standard pub/sub routes messages based on specific topics, the architecture can apply a fanout pattern to broadcast an event to all active subscribers simultaneously, regardless of their specific topic filters. If a receiving application is offline, message queues—such as a standard queue or a dead-letter queue—retain the payload.
Event streaming is a communication model where systems process continuous, unbounded flows of event data by publishing immutable events to an appended broker log. This architecture differs from standard message queues because the log retains historical records for replay and analysis. Decoupled services, such as analytics engines and auditing platforms, read from this continuous stream at any specific point to communicate asynchronously.
Event stream processing (ESP) manages high throughput and low latency data feeds. Technologies like Apache Kafka power this continuous transmission. Organizations use this real-time processing to analyze data in flight, such as monitoring financial transactions or tracking live telemetry. If a failure occurs, systems can replay these retained logs.
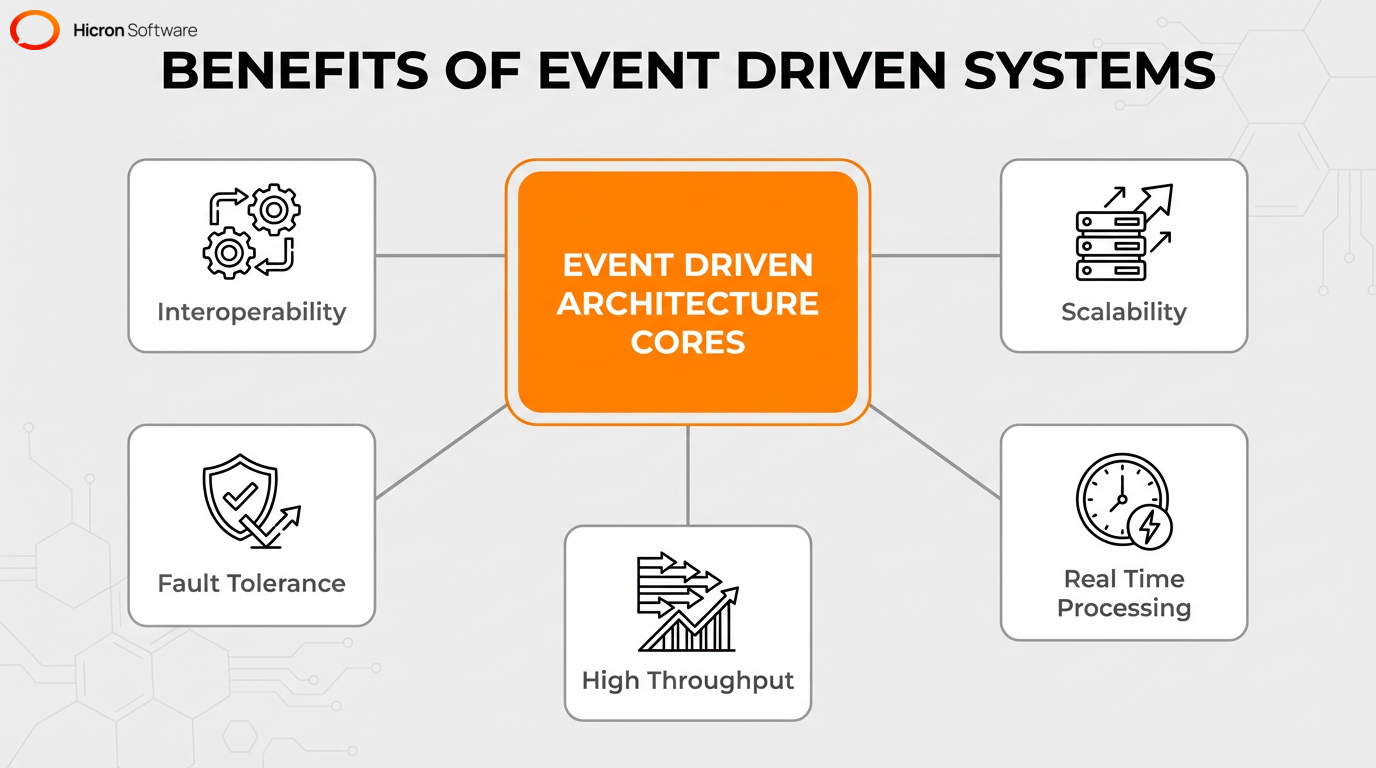
Event-driven systems offer distinct operational benefits. The architecture integrates heterogeneous platforms to ensure interoperability across a network. Independent teams can deploy and update a specific application without disrupting the entire infrastructure.
Loose coupling ensures system components operate independently, regardless of where they’re hosted. By using an event broker as an intermediary, applications can share data without being directly tied to one another’s underlying infrastructure.
The architecture improves cloud-native applications and external platforms by isolating codebase management and enabling fine-grained scalability of microservices. The system maintains high fault tolerance when developers modify a consumer application, as this isolated update prevents downtime for event producers.
Asynchronous communication enables a sender and a recipient to operate independently without waiting for an immediate response, creating a non-blocking exchange that eliminates the bottlenecks of synchronous models. Decoupled services, such as an independent billing module and a separate analytics engine, achieve high throughput and low latency through parallel processing. A system manages an increased workload simply by adding a new instance to read from message queues.
The architecture ensures deferred execution and fault tolerance if a consumer disconnects. The infrastructure scales efficiently during high-traffic events, such as Black Friday sales or holiday promotions, allowing an organization to scale up an event consumer without affecting producer performance. This loose coupling directly improves overall system scalability.
Event-driven architecture enables real-time processing because systems react immediately to generated data instead of waiting for legacy data collection methods like scheduled batch jobs or periodic polling. This framework shifts data distribution from a pull-based model to a push-based model. This immediate reaction drives two main business outcomes: proactive business responses and automated operations.
Decoupled services use event stream processing (ESP) and complex event processing (CEP) to manage a high throughput environment with low latency. This push-based transmission supports asynchronous communication across an infrastructure. Take real-time fraud detection as an example of this immediate system reaction. If an application detects suspicious activity, an event triggers immediate analysis and account freezing before a transaction completes.
Adopting event-driven architecture introduces complexities in data accuracy, performance, and maintenance. It can be incredibly difficult for developers to trace the exact path of a single business transaction or payload across multiple decoupled services during asynchronous communication.
Eventual consistency is a data model where stateful entities lack immediate synchronization across a distributed system but guarantee alignment over time. If you’re used to traditional relational databases, wrapping your head around this delay can be one of the biggest mental hurdles. Processing delays mean data looks different across decoupled services at the exact same moment. Deferred execution leads to temporary data discrepancies between microservices, so developers design user interfaces and business logic to account for these delays using adaptations like loading indicators and background polling mechanisms.
You might observe two different states during this delay, such as an updated primary database alongside an outdated secondary cache. For example, a user updates a profile, but a secondary service displays the old data for 5 seconds until the system fully processes the immutable events. Engineers use two specific design patterns to manage this data flow: event sourcing and Command Query Responsibility Segregation (CQRS). These patterns separate read and write operations to maintain accuracy. Ignoring these synchronization gaps creates significant technical debt as an organization scales its infrastructure.
Deferred execution occurs when an event broker holds messages instead of triggering an event handler instantly if a consumer isn’t ready. This asynchronous communication protects decoupled services from failing during traffic spikes. The primary trade-offs of this mechanism include sacrificing immediate synchronization and low latency to maintain high fault tolerance.
Message queues hold data safely if an application goes offline. Once the service recovers, the system processes these retained records to maintain eventual consistency and handle heavy traffic.
Complex event processing (CEP) introduces significant operational overhead and technical debt if an organization lacks strict governance. Analyzing complex trends through event stream processing (ESP) creates long-term maintenance challenges during continuous real-time processing. Engineers often struggle with tasks like maintaining multi-stage event flows and debugging asynchronous communication across decoupled services.
Undocumented event schemas and routing rules degrade system maintainability over time. I’ve seen firsthand how quickly a lack of strict documentation can turn a sleek architecture into a tangled mess. Relying heavily on CEP without an event portal makes safely updating core services nearly impossible. Ultimately, an event broker distributes these intricate payloads, but unmanaged architectures restrict overall system scalability.
Five standard blueprints for building reliable event-driven applications include Command Query Responsibility Segregation (CQRS), event sourcing, choreography, orchestration, and the fanout pattern. These architectural design patterns solve specific distributed system problems by managing complex connections across microservices.
Engineers use these frameworks to handle complex workflows when an infrastructure requires high interoperability. By implementing these specific structures, teams can directly improve overall system scalability and network resilience. These methods rely on generating immutable events and using the publish-subscribe model to maintain completely decoupled services. This pub/sub mechanism guarantees continuous data flow across an environment as an organization scales its operations.
Command Query Responsibility Segregation (CQRS) is an architectural design pattern that separates read (query) and update (command) operations into different models. This division improves overall performance, security, and scalability. Decoupling reads and writes improves distributed systems by enabling the independent optimization of decoupled services. Microservices manage a high throughput environment efficiently because administrators scale the command and query components independently based on specific traffic demands. Commands publish immutable records through asynchronous communication to initiate system state changes.
These generated events eventually update the isolated read databases, relying heavily on eventual consistency for synchronization. To maintain a complete history of state changes, engineers frequently pair CQRS with event sourcing—a combination that easily supports continuous real-time processing during complex data retrieval. Consider an e-commerce platform: The service handling order placements acts as the command model and scales differently than the service displaying order history. The query model processes heavy read requests independently, preventing performance bottlenecks during customer traffic spikes.
Event sourcing is a design pattern that captures all modifications to an application state as a chronological sequence of immutable events, rather than simply storing the current state. This append-only log provides a highly reliable audit trail to enable exact state reconstruction if a system failure occurs. Storing a complete history of state changes is more reliable because the database never overwrites old data. A classic example is a bank account ledger.
A financial application calculates the current balance by replaying historical records, such as past deposit and withdrawal events. To make this efficient, event sourcing often pairs directly with Command Query Responsibility Segregation (CQRS) to build materialized views for efficient querying across decoupled services. An event broker distributes these structural updates through message queues to maintain eventual consistency. Organizations use event stream processing to analyze these continuous historical logs and ensure accurate data synchronization.
Change data capture (CDC) is a mechanism that identifies database modifications and automatically publishes these state changes as system events. It watches for specific operations, including inserts, updates, and deletes. CDC acts as a primary event producer, transforming legacy database operations into continuous event stream processing.
This integration ensures accurate data synchronization across decoupled services. For example, a CDC tool monitoring a legacy SQL database instantly transmits a specific payload to a modern search index when someone adds a new product. The architecture routes these immutable events through an event broker to communicate asynchronously. This automated mechanism supports continuous real-time processing across an infrastructure.
Choreography and orchestration offer two distinct approaches to managing complex workflows. In a choreographed system, there’s no central controller; each service listens for events and independently decides how to react, much like dancers responding to music. This decentralized approach promotes high autonomy but can make tracking the overall process difficult. Orchestration, however, relies on a central coordinator—an orchestrator—that explicitly directs each service on what to do and when. While orchestration simplifies monitoring and error handling, it introduces a single point of failure and tighter coupling. Choosing between them depends on whether your priority is service independence or strict process control. As a pro-tip, many successful architectures actually end up using a hybrid of both, depending on the specific business workflow.
Event-driven architecture is a natural fit for microservices because it inherently prevents tight coupling. In a traditional synchronous request-response model, if one microservice fails, the dependent services waiting for a response can also fail, leading to cascading system outages. How do events solve this? By using events, microservices can broadcast state changes without needing to know which other services are listening. If a downstream service is temporarily offline, the event broker retains the message until the service recovers. This isolation ensures that failures remain localized, allowing development teams to build, deploy, and scale individual microservices independently.
Building an event-driven architecture requires core infrastructure components, including event brokers, streaming platforms, and serverless functions. For data distribution, teams primarily use message queues for discrete events and streaming platforms for continuous data flows.
Central middleware provides the necessary routing and queuing capabilities to manage these transmissions, and organizations use cloud-native technologies to support highly scalable event-driven designs. By combining these tools, engineering teams can build infrastructure capable of handling massive, unpredictable event loads without degrading performance.
Apache Kafka is a distributed event streaming platform designed to handle continuous, unbounded flows of events with exceptionally high throughput and low latency. This event broker manages massive data volumes through two main features: an append-only log structure and distributed partitions. The append-only log structure allows for fast disk writes and reads during event stream processing (ESP).
Distributed partitions divide data across multiple servers to support massive scalability and high fault tolerance if a system node fails. Organizations use this infrastructure to process millions of events per second for two main use cases: real-time analytics and data pipelines. This continuous event streaming ensures immediate real-time processing across an enterprise infrastructure.
An event mesh is an infrastructure layer that a network of interconnected event brokers forms, which routes events across different environments. Organizations route events across complex, multi-cloud environments by deploying this specific middleware. This network uses event routers to extend loose coupling across distinct locations, such as multiple clouds, on-premises data centers, and IoT devices.
The architecture ensures global interoperability and smooth event distribution for decoupled services. For instance, an event mesh routes a supply chain event from an on-premises factory system directly to a cloud-native analytics application. Even if a specific network node fails, this interconnected infrastructure maintains high scalability and fault tolerance.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
