Modernizing Insurance Frontends with Java-Based Frameworks like Vaadin
- June 07
- 13 min



Insurance fraud detection is the systematic process of identifying and preventing deceptive practices where individuals or groups try to obtain illegitimate payments from insurance providers. It involves analyzing claims data, behavioral patterns, and historical records to distinguish between genuine losses and fabricated incidents. By understanding these mechanisms, you gain insight into how modern technology protects honest policyholders from rising costs while securing the financial stability of the entire industry.
This article explores how artificial intelligence and advanced analytics are revolutionizing the fight against financial crime in insurance. You will learn about the sophisticated methods used to detect insurance fraud, the role of machine learning algorithms in identifying suspicious activities, how these technologies and insurance software help insurers stay one step ahead of fraudsters.
Key Takeaways:
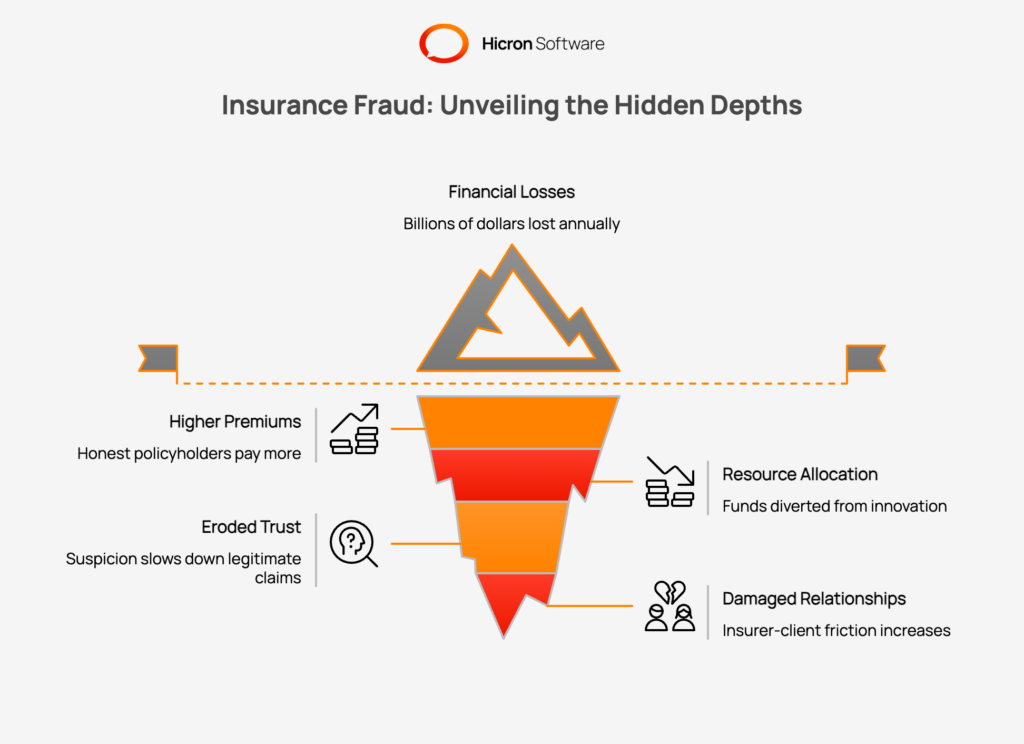
Fraud is a pervasive issue that extends far beyond a few isolated incidents of dishonesty. According to the Coalition Against Insurance Fraud, insurance fraud costs the U.S. an astounding $308.6 billion annually.
The impact of insurance fraud ripples through the entire insurance sector, creating a financial burden that affects everyone involved. When fraudsters succeed in deceiving insurance companies, the losses are not absorbed silently by the corporation. Instead, these losses translate into higher operational costs, which inevitably leads to higher premiums for the honest policyholder.
The financial toll is staggering, with billions of dollars lost annually across the globe due to fraud schemes. These costs associated with fraud force insurers to allocate substantial resources toward fraud investigations and legal defenses rather than innovation or customer service improvements. The Coalition Against Insurance Fraud highlights that fraud costs the average family hundreds of dollars per year, proving that fraud doesn’t just affect the bottom line of a corporation, it impacts the household budget of everyday consumers.
Beyond direct monetary loss, widespread insurance frauds erode trust in financial services. When insurance providers must scrutinize every claim with suspicion to combat insurance fraud, the claims process slows down for legitimate customers. This friction can damage the relationship between the insurer and the client. Therefore, effective fraud prevention is about preserving the integrity and efficiency of the entire insurance business.
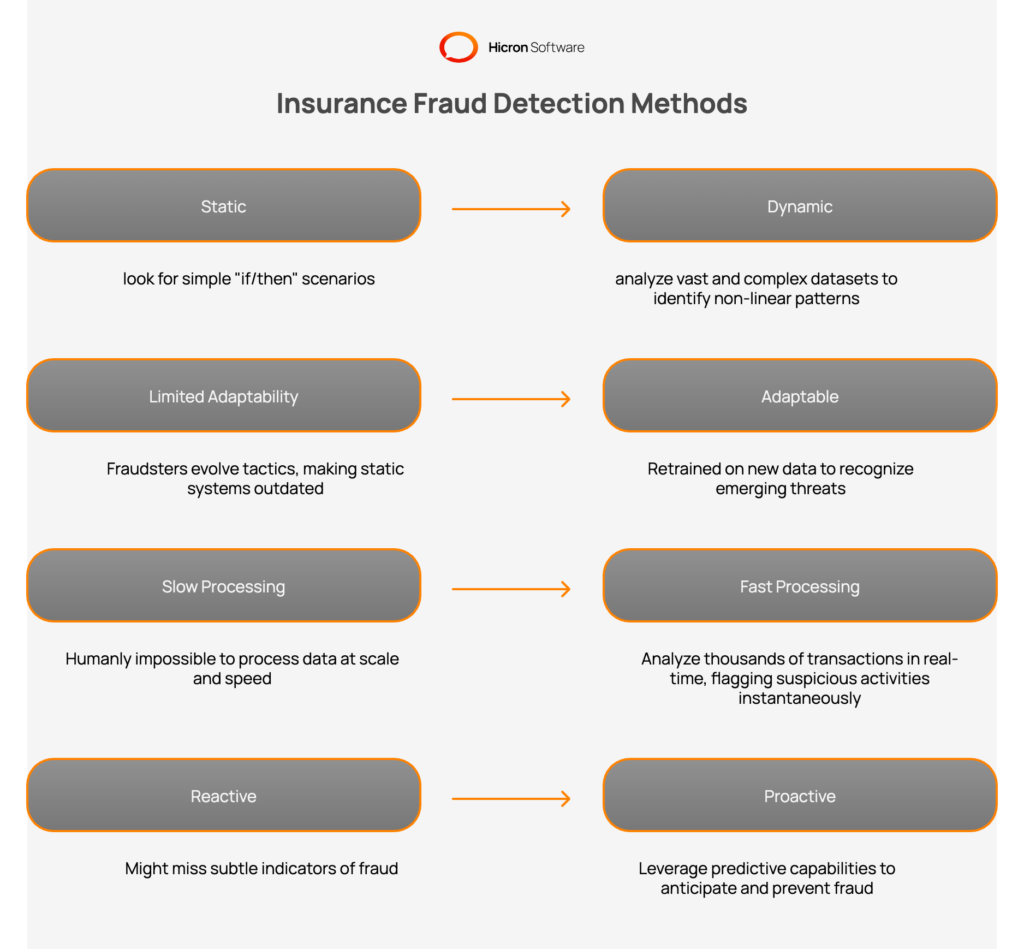
Historically, insurance companies relied on traditional methods to identify questionable claims. This process was heavily manual, depending on the intuition and experience of claims adjusters to spot red flags. While human expertise remains valuable, it is simply not scalable in the face of modern insurance claim volumes. Manual reviews are time-consuming, prone to human error, and often inconsistent. As insurance claims increase in number, it becomes impossible for humans to review every file with the depth required to catch sophisticated fraud.
Organized fraud rings have become adept at bypassing these manual checks. They understand the thresholds and triggers that prompt a human review and design their fraudulent activities to fly under the radar. Without advanced tools, insurers often miss subtle connections between seemingly unrelated claims. Legacy systems struggle to process large amounts of data from disparate sources, leaving blind spots that criminals exploit. This inability to effectively detect complex schemes highlights the urgent need for advanced analytics and automation to modernize the insurance process.
The reactive nature of traditional methods is another major weakness. Often, fraud is discovered only after the claim has been paid, making recovery of funds difficult or impossible. Fraud prevention requires a proactive approach. Insurers need to stop fraud before the check is cut. This shift from reactive investigation to proactive detection is where traditional methods fail and where modern technology must step in to close the gap.
According to Coinlaw.io Insurance Fraud Statistics, US insurers employ a diverse array of techniques and technologies to detect fraudulent claims.
Machine learning has emerged as a critical tool in the effort to detect and prevent fraud. Unlike static, rules-based systems that look for simple “if/then” scenarios, a machine learning model can analyze vast and complex datasets to identify non-linear patterns. By training algorithms on historical data containing both legitimate and fraudulent claims, these systems learn to recognize subtle indicators of fraud that a human analyst might miss.
The adaptability of AI and machine learning is central. Fraudsters are constantly evolving their tactics to outsmart detection systems. Machine learning algorithms can be retrained on new data to recognize these emerging threats, allowing insurers to stay ahead of the curve. This dynamic capability helps mitigate the risk of new fraud types, such as synthetic identity theft or sophisticated cyber crimes involving online fraud. By leveraging predictive machine learning, companies can move to a proactive stance.
Machine learning enables the processing of data at a scale and speed that is humanly impossible. It can analyze thousands of transactions in real-time, flagging suspicious activities instantaneously. This speed is crucial for insurance fraud detection because it allows for intervention before a payment is made. By integrating these tools, insurance companies can vastly improve their ability to detect insurance fraud, reducing losses and protecting their honest customers.
Advanced analytics engines ingest data from internal sources, such as policy history, past claims, and call center notes. However, internal data is rarely enough. Insurers also pull from external sources, including public records, credit reports, social media, and even connected devices (IoT). For instance, telematics data in auto insurance can verify if a car was actually at the scene of an alleged accident, helping to validate or debunk claims for injuries.
This aggregation of data creates a 360-degree view of the claim. By analyzing text from adjuster notes or medical bills, analytics tools can spot inconsistencies that suggest exaggerated claims or medical expenses padding. Network analysis can link a single policyholder to known fraud rings or identify multiple claims originating from the same IP address. This holistic view allows insurance fraud detection software to identify patterns that would otherwise remain hidden in silos.
The quality and variety of the insurance dataset directly impact the effectiveness of the machine learning model. The more diverse the data, ranging from structured fields in an application to unstructured images of damage, the more accurate the fraud detection systems become. This comprehensive data analysis is the foundation of modern insurance fraud solutions, enabling insurers to see the full picture and make informed decisions.
|
Data Category |
Data Source Examples |
Application & Impact on Fraud Detection |
|
Internal Data |
• Policy history |
Foundational Analysis: Establishes baseline behavior for policyholders and identifies discrepancies in current claims against historical patterns. |
|
External Data |
• Public records |
Validation & Context: Verifies claimant details and location (e.g., using telematics to confirm vehicle location at the time of an accident) to validate or debunk injury claims. |
|
Unstructured Data |
• Medical bills |
Inconsistency Detection: Uses text analytics to spot exaggerated claims or medical expense padding that structured data fields might miss. |
|
Network Data |
• IP addresses |
Link Analysis: Connects single policyholders to known fraud rings or identifies multiple claims originating from the same source, revealing organized fraud schemes. |
|
Combined Dataset |
• Aggregation of all above sources |
Holistic View: Creates a 360-degree view of the claim, directly improving the accuracy of machine learning models and enabling informed decision-making. |
Anomaly detection operates on the premise that fraudulent claims behave differently from legitimate ones. By establishing a baseline of “normal” behavior for various types of insurance, algorithms can instantly flag outliers. Whether it is life insurance, car insurance, or liability insurance. For example, if a medical provider submits claims for injuries at a frequency that is statistically impossible compared to their peers, the system flags it for review.
This method is particularly effective against organized fraud where criminals automate the submission of claims or use templates. Machine learning techniques sift through thousands of transactions to find these statistical deviations. It helps identify patterns and anomalies, such as a sudden spike in high-value claims in a specific zip code or a policyholder who buys insurance policies and files a claim shortly after, a classic sign of potential fraud.
While anomaly detection is potent, it requires careful tuning to avoid a high rate of false positives. If the system is too sensitive, it might flag legitimate, unusual events as fraud, causing delays for honest customers. Continuous refinement of the models helps reduce the risk of these errors. By balancing sensitivity with precision, insurers can effectively use anomaly detection to spot suspicious activities without disrupting their core insurance business.
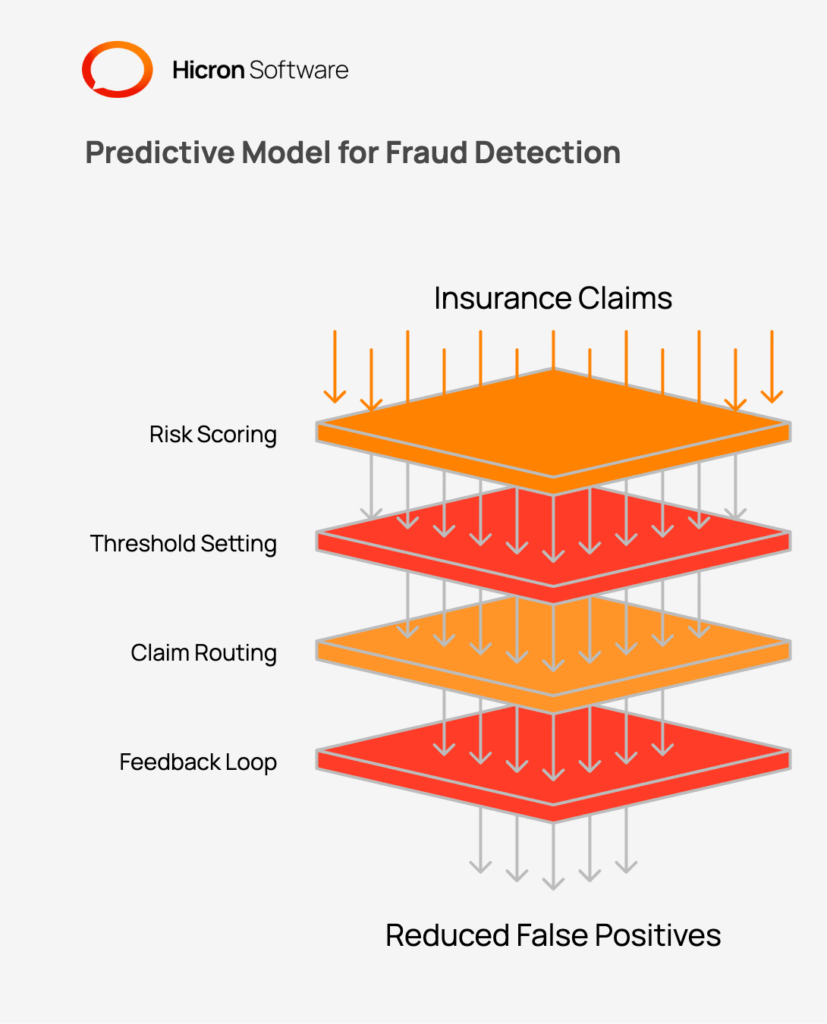
One of the biggest challenges in fraud detection in insurance is balancing security with the customer experience. If a system generates too many false alarms, it wastes investigative resources and frustrates legitimate claimants. Predictive models help solve this by assigning a risk score to every claim. Instead of a simple binary output, the model predicts the probability of fraud. Insurers can then set thresholds: low-risk claims are fast-tracked, while high-risk ones are routed to investigators.
This scoring mechanism allows insurance companies to focus their resources where they are most needed. By using a predictive model, investigators do not waste time on low-probability cases. This efficiency not only helps reduce the risk of financial loss but also improves the speed of service for honest customers. Feedback loops from investigators help the model “learn” from its mistakes.
If a flagged claim turns out to be legitimate, that data is fed back into the system to improve future accuracy. This iterative process helps reduce fraud management costs and improves the overall efficiency of the insurance sector. By minimizing the false positive rate, insurers can deploy fraud solutions that are both effective at stopping crime and respectful of their honest clients.
A substantial portion of the data in the insurance industry exists as unstructured text, for example police reports, medical evaluations, emails, and adjuster notes. Natural language processing (NLP), a subset of artificial intelligence, allows computers to “read” and understand this text. In the context of claims fraud, NLP can analyze the narrative of an accident description to find inconsistencies. For example, if the damage described in an auto insurance claim does not align with the physics of the described accident, the system can flag it.
Text mining is also crucial for identifying soft fraud, such as opportunistic exaggerated claims. It can detect subtle changes in sentiment or language use during the insurance application or claims process that correlate with deception. By converting this unstructured text into structured data, insurers can feed it into their machine learning models, adding another layer of depth to their fraud detection systems.
This capability allows insurance providers to audit 100% of claims for indicators of fraud, rather than just a random sample. It tightens the net around fraudsters by ensuring that even the narrative details of a claim are subject to scrutiny. Text mining transforms words into actionable insights, making it a vital component of modern insurance fraud solutions.
Fraud involves networks. Often, insurance frauds are not committed by isolated individuals but by organized groups involving body shops, doctors, lawyers, and claimants working in collusion. Social network analysis (SNA) is a powerful analytics tool used to map these relationships. By visualizing the connections between different entities in the insurance dataset, SNA can reveal hidden links. For instance, it might show that a specific doctor and a lawyer appear together on an unusually high number of liability insurance claims.
This technique is vital to detect complex fraud rings. A single claim might look legitimate on its own, but when viewed as part of a web of interconnected events, the fraud becomes obvious. SNA helps insurance companies move beyond looking at claims in isolation. It enables them to identify clusters of suspicious activity and dismantle entire criminal networks rather than just denying individual claims.
This systemic approach is one of the most effective fraud solutions available to the insurance sector today. It allows investigators to see the forest for the trees, identifying the central nodes in a criminal enterprise. By disrupting these networks, insurers can combat insurance fraud at its source, preventing future losses and protecting the integrity of the system.
|
Key Aspect |
How Social Network Analysis (SNA) Works |
Impact on Fraud Prevention |
|
Mapping Relationships |
SNA visually maps connections between different entities in an insurance dataset, such as claimants, doctors, lawyers, and body shops. |
It reveals hidden links that are not obvious when viewing claims in isolation, helping to uncover organized collusion. |
|
Detecting Fraud Rings |
The analysis identifies unusually dense clusters of connections. For example, it can show a specific doctor and lawyer appearing together on a high number of claims. |
This technique is vital for detecting complex, organized fraud rings rather than just individual fraudulent claims. |
|
Identifying Suspicious Clusters |
By analyzing patterns, SNA highlights groups of interconnected events or individuals that deviate from normal behavior, flagging them as suspicious. |
It enables insurers to identify clusters of suspicious activity, allowing them to focus investigative resources more effectively. |
|
Systemic Approach |
Instead of treating each claim as a standalone event, SNA provides a holistic view, showing how individual fraudulent acts are part of a larger criminal enterprise. |
This systemic approach helps dismantle entire criminal networks, preventing future losses and protecting the integrity of the insurance system. |
|
Identifying Central Nodes |
The analysis pinpoints the most influential entities (central nodes) within a network, such as the primary organizer of a fraud scheme. |
By identifying and targeting these central figures, insurers can disrupt the entire network and combat insurance fraud at its source. |
Speed is critical in fraud prevention. Once money has been paid out, the chances of recovering it are slim. Real-time analytics enables insurers to assess the risk of a claim the moment it is filed—or even during the insurance application process. By integrating fraud detection technology directly into the claims workflow, suspicious activities are halted immediately.
This immediacy acts as a powerful deterrent. If a fraudster knows that insurance fraud detection systems are running in real-time, the perceived risk of getting caught increases. For example, in unemployment insurance or card fraud, real-time checks can stop a transaction before it completes. In the context of property and casualty, it means a claim can be flagged for a deep dive before the check is cut.
This capability to detect and prevent fraud at the point of interaction is the gold standard for modern insurance fraud solutions. It minimizes the financial leakage associated with “pay and chase” models. By stopping the outflow of funds to criminals, insurers can protect their reserves and maintain competitive pricing for their honest policyholders.
The future of fraud detection in insurance lies in the continued evolution of artificial intelligence and the integration of even more diverse data sources. We will likely see a rise in image analytics, where AI analyzes photos of damage to estimate repair costs and detect if images have been doctored or reused from previous claims (a common tactic in online fraud). Automation will handle the vast majority of routine checks, leaving human experts to tackle the most complex insurance fraud cases.
However, as detection capabilities improve, so do the tactics of criminals. The industry must remain vigilant against new fraud vectors, such as deepfakes or AI-generated documents. The battle to combat insurance fraud is an arms race. Continued investment in advanced analytics, collaboration across the insurance industry to share data on known bad actors, and the adoption of cutting-edge fraud solutions will be essential.
Ultimately, the goal is to create an ecosystem where insurance fraud detection is so robust that fraud becomes a low-reward, high-risk endeavor. By staying ahead of technological trends and constantly refining their models, insurers can ensure a fair and sustainable market for everyone. The combination of human expertise and machine intelligence will define the next generation of fraud prevention. Contact us to discuss further your insurance fraud detection software.
AI-powered fraud detection in insurance refers to the use of artificial intelligence and machine learning technologies to identify and prevent fraudulent activities. These systems analyze large volumes of data, detect unusual patterns, and flag potentially suspicious claims, enabling insurers to act quickly and accurately.
AI enhances fraud detection by automating data analysis, identifying complex patterns that are often missed by manual methods, and learning from past fraud cases to improve accuracy over time. Using techniques like predictive modeling and anomaly detection, AI can reduce false positives and improve efficiency in fraud investigations.
Soft fraud, also known as opportunistic fraud, occurs when a legitimate policyholder exaggerates a valid claim, such as inflating the value of stolen items. Hard fraud involves deliberate planning, such as staging an accident or inventing a theft, solely to collect an insurance payout.
Machine learning models analyze vast amounts of historical data to learn the specific characteristics of genuine versus fraudulent claims. By assigning a precise risk score to each claim, these models can distinguish between unusual but legitimate behavior and actual fraud, reducing the number of incorrect flags.
Insurance fraud detection software faces some common challenges:
No, scalable solutions are available for insurers of all sizes. While large carriers may build custom in-house systems, many software providers offer cloud-based fraud detection platforms that allow smaller and mid-sized insurers to leverage advanced analytics and machine learning without massive infrastructure investments.
Yes, small insurance companies can significantly benefit from fraud detection software. These tools help streamline operations by automating fraud checks, making fraud prevention accessible without the need for extensive in-house resources. Additionally, the scalability of modern software solutions ensures that small insurers can adapt the technology to fit their specific needs and budgets.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
