How to Rescue a Failing Software Project Step by Step


What is software project recovery?
Software project recovery stabilizes and revives a struggling initiative through a structured, corrective process. Instead of resorting to panic decisions like sudden team changes or skipping testing phases, this approach relies on a methodical recovery plan. Rushed, temporary fixes often worsen the situation. This corrective approach focuses on making the software reliable again and restoring delivery. Executing a recovery successfully integrates strict project governance and risk management back into the software development lifecycle.
Transparent project management and agile methodologies, such as Scrum sprints and Kanban workflows, align the team and improve adaptability. Why throw it all away? In most cases, recovering a failing system costs significantly less than abandoning the existing code and restarting the project from zero.
Key Elements of Software Project Recovery
|
Project Phase / Category |
Core Components & Indicators |
Impact & Required Actions |
|
Causes of Project Failure |
|
Technical debt causes architectural drift, making the foundation unstable. A lack of documentation forces new developers to manually reverse-engineer complex systems, significantly slowing down recovery. |
|
Warning Signs |
|
Poor governance leads to missed deadlines and defective releases. Uncontrolled scope creep drains the budget, requiring an immediate project health check to detect failure points before total collapse. |
|
4-Step Recovery Process |
|
Stop immediate failures by securing admin access and enforcing a strict code freeze (Triage). Conduct a deep software audit and root cause analysis (Assessment). Create a recovery plan with realistic timelines (Planning) to deliver quick wins (Execution). |
|
Stabilization Strategies |
|
Restore momentum by focusing on the 20% of features that deliver 80% of business value (MVP). Use CI/CD as an automated safety net to block flawed updates, and aggressively refactor to clean up structural shortcuts. |
|
Prevention & Risk Management |
|
Routine evaluations catch minor deviations early. Change control prevents scope creep by evaluating new requests before work begins. An exit strategy overcomes the sunk cost fallacy by defining exact criteria for shutting down non-viable modules. |
Why do software projects fail?
When a project goes off the rails, the culprits usually fall into three camps:
- Planning issues: Unrealistic timelines and poorly defined scope.
- Structural issues: Mounting technical debt and architectural drift.
- Documentation issues: Missing logic maps that end up leaving new developers completely in the dark.
Without clear leadership and a plan for risks, teams waste time and the system falls apart. If you’ve ever been part of a team during one of these downward spirals, you know exactly how overwhelming it feels. To fix the project, you first have to find exactly where it broke.
How does technical debt cause architectural drift?
Think of technical debt like a credit card: it’s the implied cost of choosing a quick solution over a better approach during the development process. Opting for an easy fix damages the software architecture. It forces developers to build on a compromised foundation. Architectural drift occurs when the original structure can no longer support new features, resulting in an unstable codebase. Without peer-level code reviews, this degradation often goes unnoticed.
Teams conduct specific quality assurance practices, such as technical assessments and code audits, to identify structural deviations. If the codebase remains salvageable, regular refactoring supports system stabilization, but an unaddressed structural breakdown identified during a technical audit will eventually force you to completely rebuild the outdated system.
How does scope creep affect resource allocation?
When project requirements expand without corresponding adjustments to budgets or timelines, you’re dealing with scope creep. This silent project killer forces teams to squeeze extra tasks into original constraints, quickly depleting resources. Inefficient resource allocation drains developer hours and stalls progress throughout the development process. Unplanned additions disrupt the project roadmap and cause delivery failures, including missed deadlines and exhausted budgets.
Software project recovery efforts often reveal missing scope and undocumented feature requests. If a team experiences severe scope creep, the project requires an immediate change control evaluation to reassess the workload. Clear leadership helps get everyone back on the same page regarding exact deliverables. Project management teams use agile methodologies, like prioritized backlogs and iterative sprints, to adapt to changes safely. Tracking progress prevents burnout by comparing active developer hours against the planned baseline.
What is the impact of a documentation vacuum?
A documentation vacuum obscures the software architecture, significantly slowing down recovery efforts. It’s like trying to navigate a sprawling, unfamiliar city without a map or GPS. When previous teams leave behind no clear technical guides, new developers must manually reverse-engineer complex systems. They struggle to understand critical components, including:
- Third-party dependencies
- Custom algorithms
- Deployment configurations
This missing context increases risk and significantly slows down recovery. Here is a hard-learned pro-tip: never underestimate the time it takes to unravel undocumented custom logic. To bypass this knowledge gap, teams must run deep code audits and technical reviews. A thorough documentation review becomes impossible if past developers ignored project governance. Proper risk management practices can still restore system stabilization once the recovery team successfully maps the undocumented logic.
What are the warning signs that a project needs rescuing?
How do you know it’s time to step in? Look out for these five red flags:
- Continuous delivery failures
- Mounting technical debt
- Architectural drift
- Declining team morale
- A breakdown of stakeholder trust
Delivery failures quickly derail your roadmap. As delays pile up, technical debt grows and the codebase degrades. To make matters worse, uncontrolled scope creep drains the budget, and a lack of clear leadership causes quality to plummet.
Poor governance directly causes missed deadlines and defective software releases. Declining team morale quickly follows when developers constantly fix critical bugs instead of building new features. Stakeholder trust breaks down when project management fails to provide transparent reporting. A regular project health check acts as an early-warning system for these operational red flags. Before the system collapses entirely, a deep software project audit reveals the exact failure point. Teams implement strict risk management and continuous performance monitoring to detect these negative indicators early.
How do you execute a software project recovery?
Turning a failing project around usually comes down to four main steps: triage, assessment, planning, and execution. Following this process stops the panic and gets the system working again. Teams use agile methodologies and disciplined project management to deliver quick wins and rebuild client trust.
How do you conduct a software project audit?
To uncover technical defects and process breakdowns, teams conduct an in-depth software project audit. This evaluation targets four specific areas: code quality, architecture, the delivery pipeline, and documentation. By performing peer reviews, evaluators can accurately measure the health of the codebase.
Specialists begin by using root cause analysis methods, such as the 5 Whys technique and fault tree analysis, to understand exactly why a project is failing. From there, a thorough documentation review reveals missing technical context if previous developers ignored design logs. Next, engineers analyze the delivery pipeline and software testing protocols to ensure reliable quality assurance. If the software architecture experiences severe load bottlenecks, continuous performance monitoring tracks system stability. Ultimately, extracting this precise data during a technical audit forms the basis of the recovery plan.
How does root cause analysis identify core issues?
Investigators typically use tools like the Fishbone diagram or the 5 Whys to trace symptoms back to their source. Once these root causes are identified, the team can fix the underlying architectural flaws and set up monitoring to ensure the system remains stable.
How do you create a project recovery plan?
A project recovery plan is the primary output of the assessment phase and guides system stabilization. Creating this document requires defining essential elements within a project roadmap, such as prioritized fixes, reassessed goals, and realistic timelines. In my experience, the most critical part of this step is brutal honesty about what the team can actually deliver. Managers update estimates based on real progress rather than optimistic projections. This factual baseline ensures efficient resource allocation, while leaders assign clear tasks to keep everyone accountable.
The schedule prioritizes two specific quick wins—resolving critical bottlenecks and launching an MVP—to rebuild trust with clients and confidence. Teams integrate agile methodologies and a reliable delivery pipeline to release stabilized code rapidly. If unexpected defects emerge, the recovery unit adjusts the plan to handle new risks to protect the new timeline.
Which strategies help stabilize a failing software system?
Turning around a failing software project requires a few key strategies. Project management uses agile methodologies and continuous performance monitoring to prioritize core deliverables effectively. Integrating strict development discipline and automated testing keeps the codebase stable throughout the recovery process.
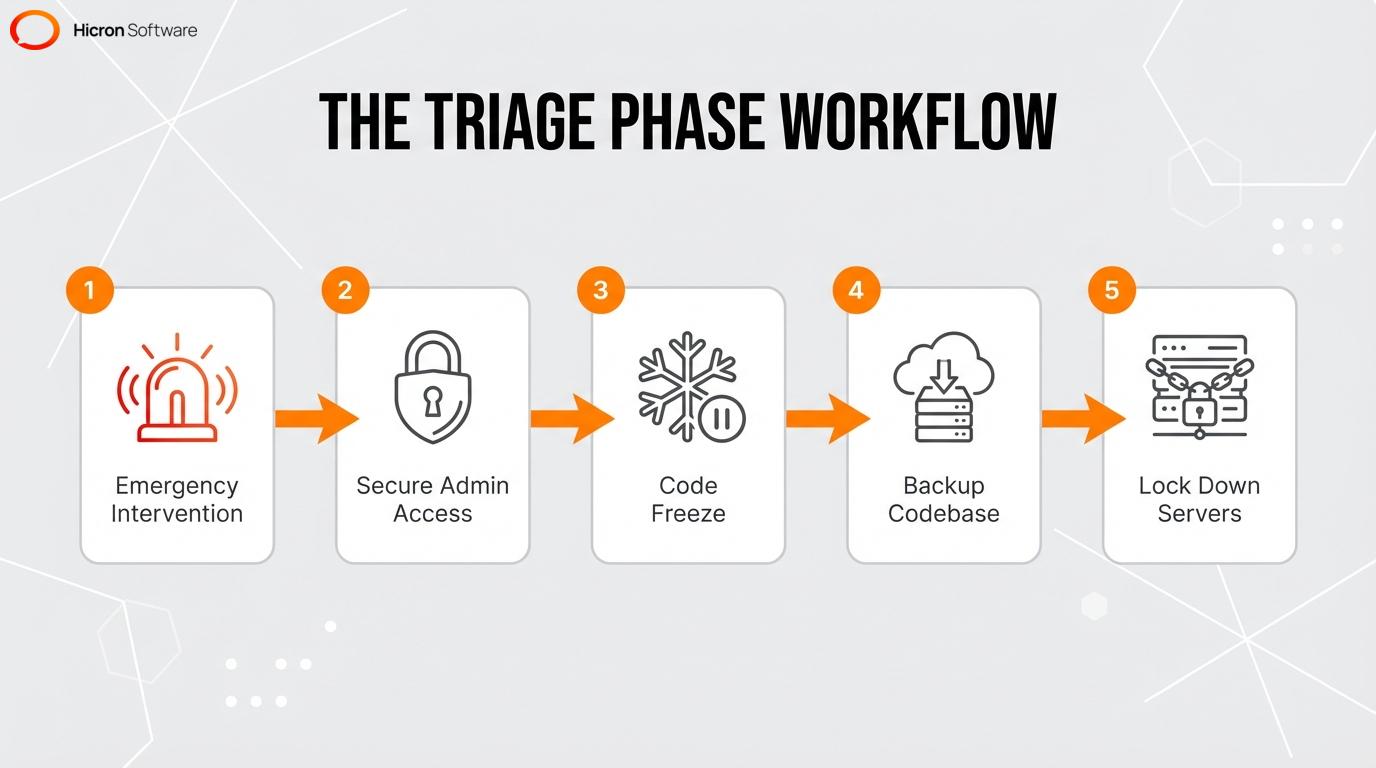
How does the triage phase stop immediate delivery failures?
The triage phase acts as an emergency intervention to stop immediate delivery failures. This high-stakes period focuses on stopping the bleeding during a project rescue and typically happens within the first 48 hours. Teams take two immediate actions to halt the failure: securing admin access and putting a strict code freeze in place. This freeze hits pause on the delivery pipeline to prevent further damage to the architecture.
Once the environment is halted, managers enforce strict oversight while engineers and DevOps specialists work together to back up the codebase and lock down servers against unauthorized changes. Creating this static pause gives evaluators the stable environment they need to accurately identify core defects.
How can a minimum viable product restore delivery momentum?
Rescoping a failing initiative to a minimum viable product (MVP) restores delivery momentum and stakeholder trust by eliminating bloated features. In the context of recovery, an MVP requires ruthless minimalism. It can be painful to cut features you’ve already spent weeks discussing, but it is absolutely necessary. This approach rescues a bloated software project by identifying the 20 percent of features that deliver 80 percent of business value. Project management uses agile methodologies to adjust the project roadmap toward these core features.
If a team experiences severe scope creep during the software development lifecycle, focusing on essential functions creates breathing room and improves resource allocation. Delivering these essentials quickly rebuilds team morale and stakeholder confidence. A streamlined delivery pipeline ensures the rapid deployment of these critical components. This targeted approach yields two primary outcomes: a stable system and happy clients.
How do agile methodologies improve stakeholder alignment?
When a project is failing, communication usually breaks down. Agile helps fix this by encouraging flexibility, transparency, and a unified understanding of project goals. Through collaborative workshops and agile sprints, these frameworks bridge the communication gap between business and technical teams. Project management uses two primary iterative practices, Scrum and Kanban, to enable rapid responses to issues during the software development lifecycle.
Integrating an MVP into the delivery pipeline delivers quick wins that rebuild stakeholder trust. An updated project roadmap guarantees transparent progress tracking, while clear leadership ensures the team keeps tracking their progress to maintain this shared vision. Developers ensure rapid, visible progress by using automated deployment practices like continuous integration and continuous deployment.
How do CI/CD pipelines enforce quality assurance?
Automated CI/CD pipelines enforce QA and maintain high development standards by instantly blocking flawed updates before they reach production. During the fragile recovery phase, this automated safety net is especially critical because it prevents stressed developers from accidentally introducing new bugs into the codebase.
Establishing CI/CD pipelines enforces strict development discipline and is a primary technical strategy for getting the code back on track. DevOps specialists integrate automated testing into these workflows to guarantee consistent quality assurance. To protect a recovering software project from further defects, automated pipelines execute three critical validation checks: unit tests, security scans, and continuous performance monitoring.
Why are code reviews and refactoring necessary?
During a rescue, code reviews systematically examine code to find the hidden bugs that caused the project to derail in the first place. Refactoring then steps in to fix two specific development flaws: quick hacks and structural shortcuts. Because these shortcuts contribute directly to mounting technical debt, rigorous code reviews and continuous refactoring remain essential to eliminate it and ensure long-term architectural fitness.
Without peer code reviews, the system’s architecture can quickly degrade. To stabilize it, the recovery team must audit the existing code and aggressively refactor it, cleaning up shortcuts left by previous developers. Once the code is cleaned up, a final technical review ensures the foundation is solid.
When is legacy system modernization required?
You have to modernize legacy systems when an outdated tech stack turns into a liability for business growth and project stability, despite extensive refactoring. A rescue requires a complete rebuild if accumulated technical debt causes total obsolescence during the software development lifecycle. To save a failing platform, recovery teams execute two specific upgrade processes: cloud migration and transitioning to microservices.
Rebuilding outdated software components to modern frameworks improves three core system metrics: application performance, code maintainability, and data security. Developers restructure the underlying software architecture to support advanced technical capabilities, such as smooth API integration and an optimized data schema. DevOps specialists implement these major code changes to ensure the system stays reliable long-term.
Who should lead a software project rescue?
Successful software project rescues require experienced professionals who bring both technical depth and an unbiased perspective. Projects frequently stall when the wrong people tackle the wrong tasks, making specialized leadership essential for getting things back on track. Organizations rely on specialized architects and project managers because they have direct experience navigating severe development setbacks and crisis resolution, ensuring clear ownership prevents the initiative from stalling further.
These leaders execute a deep technical assessment and a software project audit to identify core bottlenecks accurately. Good leaders keep the team focused to optimize resource allocation across the entire development team. If communication breaks down between business units, directors use agile methodologies to get everyone communicating again. DevOps specialists and system architects implement rigorous risk management during a technical audit to protect the existing codebase. This objective oversight guarantees a factual evaluation of the failing system.
Should you hire an independent rescue team?
Sometimes, it’s best to bring in an outside team. They aren’t caught up in office politics and can look at the code objectively to provide an unbiased assessment. They bring two primary advantages to a failing initiative: specialized turnaround skills and deep technical knowledge. Independent teams excel at leading the triage phase and securing administrative control when you need it most. Specialists conduct objective technical and software project audits to identify hidden structural flaws.
A technical assessment provides factual data to support these initial findings. An independent team helps rebuild trust between business and technical stakeholders. This objective mediation gets everyone on the same page through transparent project management and strong leadership. External evaluators enforce reliable quality assurance and execute a rigorous code audit to fix the system. Implementing strict risk management prevents further architectural degradation during the rescue.
How does a vendor takeover work?
When the original team can’t fix the project, a vendor takeover moves the work to a turnaround specialist. This transition is a common exit strategy if the original team cannot meet new recovery standards. The takeover process transfers three critical project assets to a new partner: institutional knowledge, active codebases, and administrative access. This strategy mitigates business risk by placing the initiative in the hands of experienced recovery experts who implement strict project governance and risk management to secure the transferred environment.
The new team initiates backup and disaster recovery protocols immediately to protect existing data. Experts execute targeted evaluations to understand the inherited system and identify foundational flaws before the turnaround team assumes full project management responsibilities. This methodical handover rebuilds trust by establishing transparent development timelines. If the inherited codebase is beyond saving, the new partner will recommend scrapping it and building a modern replacement from scratch.
How do you measure the success of a project turnaround?
You know a turnaround is successful when you move from chaos to a stable system, and you track this using specific KPIs. The transition from a chaotic failing state to a working product is the primary indicator of a successful recovery. If leaders communicate these precise improvements effectively, a transparent reporting process gets everyone back on the same page.
Which metrics are used in performance monitoring?
To make sure the system stays stable, teams use specific KPIs to monitor performance, including developer delivery velocity, defect rates, system uptime, defect resolution rates, budget adherence, and sprint velocity. Tracking these exact numbers proves the effectiveness of renewed quality assurance protocols.
Visual management approaches, such as Obeya Control, use these metrics to display real-time progress. For example, DevOps teams measure defect rates by tracking bugs that QA teams identify during software testing. Meanwhile, when engineers implement continuous integration and continuous deployment (CI/CD), automated testing within the delivery pipeline calculates system uptime, giving everyone a clear, interconnected picture of project health.
How can you prevent future software project failures?
Organizations prevent future software project failures through strong leadership, active performance monitoring, and regular assessments. Project management teams establish clear task ownership to maintain accountability across all development phases. These proactive evaluations and rigorous risk management practices ensure keeping the software healthy long-term and mitigate future risk.
Why are regular project health checks necessary?
Regular project health checks act as an early-warning system to prevent the need for a full-scale software project recovery. These checks involve scheduled reviews of two primary project dimensions: tangible aspects like budgets and intangible aspects like team well-being. Routine evaluations remain essential for long-term software success because they identify minor deviations before they become critical failures. Project management uses technical assessments and software project audits to catch these issues early.
Consistent performance monitoring identifies architectural drift and scope creep during the software development lifecycle, allowing teams to mitigate these risks efficiently by applying strong oversight and risk management. As part of this process, routine health checks catch a documentation vacuum early, reducing long-term risk. To maintain this clarity, engineers execute specific evaluation methods—such as documentation reviews, code audits, and technical audits—which together guarantee continuous quality assurance, provided developers document their logic consistently.
How does a change control process mitigate risk?
A change control process keeps risk in check by making sure every new request is evaluated and approved before work begins. This structured evaluation prevents uncontrolled scope creep and further project derailment during the software development lifecycle. Clear leadership ensures all stakeholders agree on the exact impact new requirements will have on timelines and budgets.
A software project rescue frequently introduces change control and impact evaluation to manage previously missing scope. By implementing these approval workflows, project management teams protect the project roadmap. Agile methodologies use continuous performance monitoring to support this risk management strategy. Structuring new requests provides major benefits: it keeps the team focused, ensures everyone agrees on the goals, and keeps the software running smoothly.
When should you implement an exit strategy?
You need an exit strategy from day one so you know exactly when the rescue is over—or when it’s time to pull the plug. An exit strategy uses pre-planned criteria for two specific outcomes: transitioning to normal operations or shutting down a non-viable project. I always remind clients that walking away from a doomed module is often a smarter business decision than pouring more money into it. Implementing this predefined plan overcomes the sunk cost fallacy and prevents a permanent emergency mode during a rescue. This approach helps leaders make objective decisions regarding resource allocation rather than continuing to invest in failing modules.
A structured recovery requires an exit strategy to ensure the initiative reaches a definitive, stable conclusion. Project management uses these pre-planned criteria to keep everyone aligned and accountable. Tracking the system’s health throughout the development process helps determine the exact transition point. If the project roadmap dictates a complete shutdown, teams initiate backup and disaster recovery protocols to protect core assets. Ultimately, knowing exactly when and how to exit a project helps organizations cut their losses and move forward intelligently.
Sources
- https://mmantyla.github.io/Lehtinen_IST_2014_Perceived_causes_of_software_project_failures_an_analysis_of_their_relationships.pdf
- https://people.eecs.ku.edu/~saiedian/Teaching/811/Papers/Proj-Success-Failure/standish-2013-report.pdf
- https://obeya-association.com/2024/11/04/a-specific-obeya-for-agile-product-development/
Testimonials
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
Get in touch
