What is Hybrid and Multi-cloud Computing?
- June 25
- 22 min


Microservices architecture is a software architecture style in which an application is built as a set of small, independently deployable services. Each microservice handles a specific business capability. Services communicate with each other through APIs or message protocols, rather than sharing code or a common database.
This article covers what microservices are and how they compare to monolithic architecture. It explains the real benefits of microservices, the design patterns that make them work, and what implementing microservices requires in practice. You will find guidance on when to use microservices and when a simpler approach is more appropriate. Whether you are planning a new project or managing a migration from a monolith, this guide gives you a clear foundation. It includes examples of how organisations use microservices and closes with common questions and practical takeaways to support your decisions.
Key takeaways:
Microservices are an architectural approach to building software in which a large application is broken into a collection of small, independently deployable services. Each microservice is responsible for a specific business capability:
A microservice communicates with other services via well-defined APIs or lightweight message protocols. Microservices are an architectural style that stands in direct contrast to building everything as a single monolithic application.
At the heart of the microservices model is the principle that each microservice should be loosely coupled and independently deployable. This means that teams can deploy, update, and scale individual microservices without touching the rest of the application.
Microservices are an architectural approach that enables organisations to decompose complex systems into manageable, focused units that each own their data and their logic. In software architecture terms, this is often described as high cohesion within a service and low coupling between services.
Microservices are typically small enough to be understood by a single team, yet powerful enough that multiple microservices working together can compose sophisticated distributed system capabilities. The microservice is the fundamental unit of deployment, scaling, and ownership in this model. Understanding that unit is the foundation for everything that follows in application architecture.
A monolithic architecture builds the entire application as a single deployable unit. All components:
are tightly coupled, share a single codebase, and typically use one database. This makes early development straightforward: one team, one tech stack, one deployment pipeline.
Microservices decompose that unified system into a collection of loosely coupled, independently deployable services. Each service owns its own database, exposes functionality via APIs, and can be developed, deployed, and scaled in isolation. Communication between services happens over a network, typically via REST, gRPC, or an event bus like Kafka.
The table below summarizes the core structural differences between traditional monolithic applications and microservices:
|
Aspect |
Monolithic Architecture |
Microservices Architecture |
|
Structure |
Single codebase, all-in-one deployment |
Multiple independent services, individual deploys |
|
Scalability |
Scale entire app (vertical/horizontal) |
Scale specific services independently |
|
Development |
Simpler initially; one team, uniform tech stack |
Parallel teams; diverse tech per service |
|
Deployment |
All-or-nothing; slower releases |
Frequent, independent updates |
|
Fault Impact |
Single failure risks whole app |
Isolated failures; higher resilience |
|
Complexity |
Easier debugging/maintenance early on |
Higher ops overhead (networking, monitoring) |
|
Performance |
Faster internal calls; lower latency |
Network overhead between services |
The benefits of microservices are most tangible at scale. The single most important advantage is that services independently can be scaled: only the microservice under load needs additional compute resources, rather than the entire application. This makes scaling both more cost-efficient and more precise. A payment microservice experiencing a Black Friday surge can be scaled independently of the browsing or recommendation services.
Microservices allow teams to choose the best tool for each job. A data-heavy analytics microservice might use Python, while a high-throughput API gateway is written in Java. This freedom from a single programming language or framework accelerates innovation and lets teams optimise at the service level.
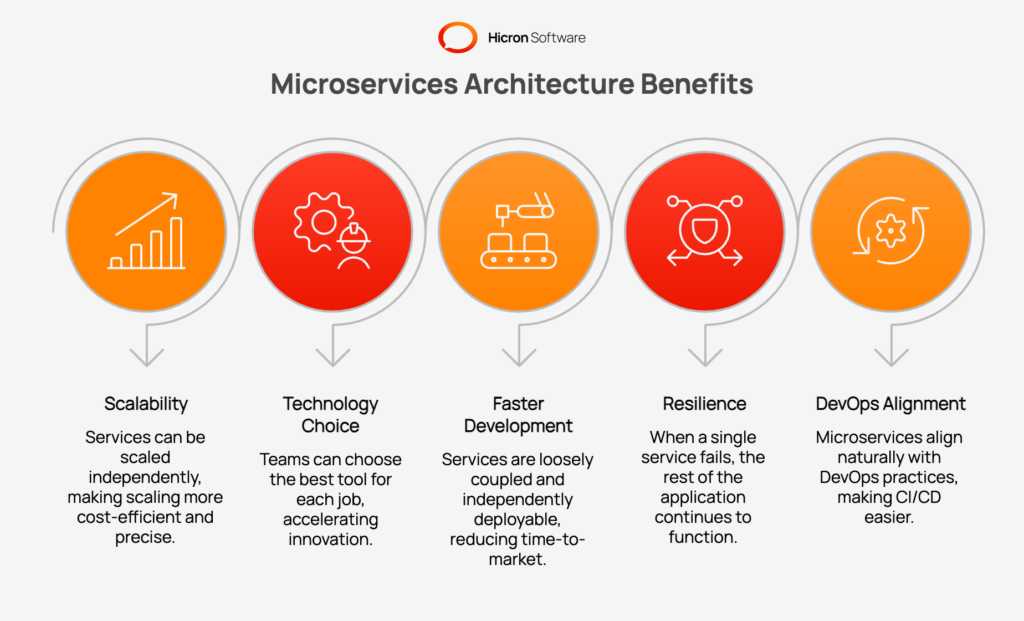
Microservices also enable faster development cycles: because services are loosely coupled and independently deployable, different teams can work in parallel without blocking each other, significantly reducing time-to-market.
Microservices provide resilience by containing failures. When a single service fails, the rest of the application continues to function, a property that is nearly impossible to achieve in a tightly coupled monolith. Microservices architecture also aligns naturally with DevOps practices: continuous integration and continuous delivery become much easier when each microservice has its own lightweight pipeline. Deployment risk is reduced because each deploy is smaller and more targeted.
The core insight: microservices are independent units that can be developed, deployed, and scaled without affecting the rest of the system, enabling both technical agility and organisational autonomy.
Knowing when to use microservices is as important as knowing how. The right use case for microservices is one where
Large applications with high traffic, like e-commerce platforms, streaming services, and fintech systems, are typical candidates.
You should not use microservices without first honestly assessing your team’s DevOps maturity. Microservices architecture requires robust tooling for
A small team without this foundation will spend more time managing infrastructure than building features. The overhead of maintaining microservices in a resource-constrained environment often outweighs the benefits.
Microservices are used most successfully in organisations that have already felt the pain of a monolith: slow deploys, team conflicts, inability to scale a specific component. If your current monolithic application is causing these problems, that is a strong signal that a microservices transformation is warranted. If it isn’t causing these problems yet, the cost of decomposing the application into smaller units may not be justified.
Microservices architecture examples from Netflix, Amazon, and Uber reveal a common toolkit of design patterns that make distributed microservices work reliably. The most widely adopted software design pattern is the API Gateway. It provides a single entry point for all client requests, handling routing, authentication, rate limiting, and protocol translation before forwarding requests to the appropriate microservice. This keeps internal microservices shielded from external complexity.
The Saga pattern addresses one of the hardest problems in microservices: distributed transactions. When an operation spans multiple microservices, for example, placing an order that debits a wallet and reserves inventory, the Saga coordinates a sequence of local transactions with compensating rollbacks if any step fails. Domain-driven design principles underpin how teams identify service boundaries, using bounded contexts to ensure each microservice maps to a coherent business domain.
The Strangler Fig pattern is the dominant design approach for teams undertaking a monolithic to microservices migration. New microservices are built around the edges of the current monolithic application, with traffic gradually routed to them. The service-oriented architecture of earlier decades shares DNA with microservices. Modern microservices architecture focuses on much finer-grained services, independent deployability, and decentralised data management, making it a more radical and more powerful approach.
Microservices communicate primarily through two mechanisms: synchronous APIs and asynchronous message passing.
In practice, microservices use both patterns, depending on the interaction type. Synchronous APIs work well for queries and commands that require an immediate response. Asynchronous messages work well for notifications, background processing, and decoupling high-throughput producers from slower consumers. Microservices to communicate effectively across a distributed system requires careful design of both the message schema and the API contract, along with versioning strategies to handle changes gracefully among microservices.
Implementing microservices successfully is an organisational challenge as much as a technical one. Microservices architecture requires teams to be structured around services rather than technical layers. A shift often described as moving from horizontal (frontend, backend, database) teams to vertical, product-aligned teams. Each team owns a microservice end-to-end:
This ‘you build it, you run it’ model is central to how microservices work.
On the technical side, microservice architecture requires a solid foundation of container orchestration tools such as Kubernetes, automated CI/CD pipelines, centralised log aggregation, metric collection, and distributed tracing. Microservices are deployed as containers, and container orchestration manages their lifecycle: scaling, self-healing, and rolling deployments. Without this infrastructure, it becomes nearly impossible to maintain microservices reliably across dozens of services.
Authentication and authorisation must be handled consistently across all microservices. Centralising authentication at the API gateway is a common pattern, with each microservice trusting tokens issued by an identity provider rather than implementing its own authentication logic. A microservices platform, whether built in-house or using a managed service like AWS ECS or Google Cloud Run, ties these capabilities together, providing the runtime environment in which each microservice lives and communicates with other services.
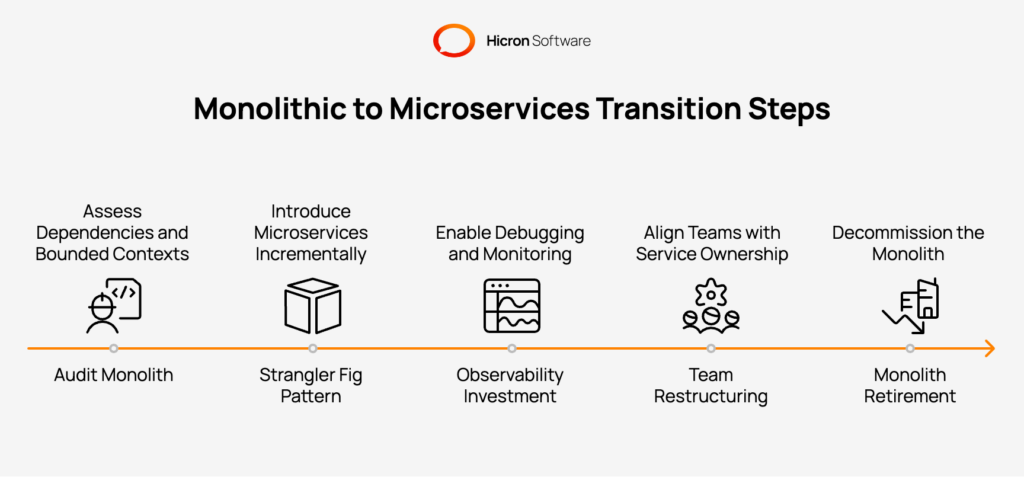
The transition from a monolithic to a microservices architecture is rarely a big-bang rewrite. The monolithic to microservices journey is incremental, starting with identifying the most painful or highest-value bounded contexts to extract.
A well-governed transition from a monolithic application begins with an audit of the current monolithic application:
The Strangler Fig pattern is the most reliable way to execute a monolithic to a microservices architecture migration. New microservices are introduced alongside the monolith, and traffic is progressively routed to them. This allows teams to run microservices in production and validate them before the monolith is retired. Monolithic applications into smaller components must be decomposed along natural business boundaries, not technical layers. Trying to split a monolith by its database tables, for instance, typically creates brittle microservices that are harder to maintain than the original monolith.
Enable faster iteration during the transition by investing in observability from day one. Distributed microservices are harder to debug than a monolith. Log aggregation, distributed tracing, and metric dashboards must be in place before teams deploy microservices to production. Many organisations also restructure teams during their microservices transformation, aligning team ownership with service ownership to reduce coordination overhead.
Real-world microservices architecture examples reveal the breadth of contexts in which this architectural style succeeds.
Amazon is arguably the most influential microservices architecture example of all. In the early 2000s, Amazon mandated that all internal microservices expose their functionality through APIs, a directive that not only transformed Amazon’s software architecture but ultimately gave birth to AWS. Microservices are an architectural approach that Amazon used to enable different teams across the company to deploy, scale, and evolve their services independently, transforming what had been a tightly coupled monolith into the world’s most scalable e-commerce platform.
Even outside of tech giants, microservices are used across industries:
Microservices often appear in contexts where many microservices must collaborate to deliver a superior user experience, from authentication to logging to payment processing, while being maintained and deployed by separate teams.
A successful microservices architecture requires alignment across technology, process, and organisational culture. Microservice architecture requires teams to invest in the infrastructure and tooling that makes distributed services manageable: container orchestration, service meshes, centralised logging, metric collection, and automated deployment pipelines. Without this foundation, the operational burden of running microservices quickly becomes unsustainable.
Microservices architectural decisions must be governed carefully. Not every service boundary is a good one: poorly decomposed microservices that are tightly coupled to each other via shared databases or synchronous chains of API calls can be worse than the monolith they replaced. Domain-driven design provides the conceptual tools to identify natural service boundaries. Different microservices should map to genuinely different domains, owned by different teams, with minimal cross-service dependencies.
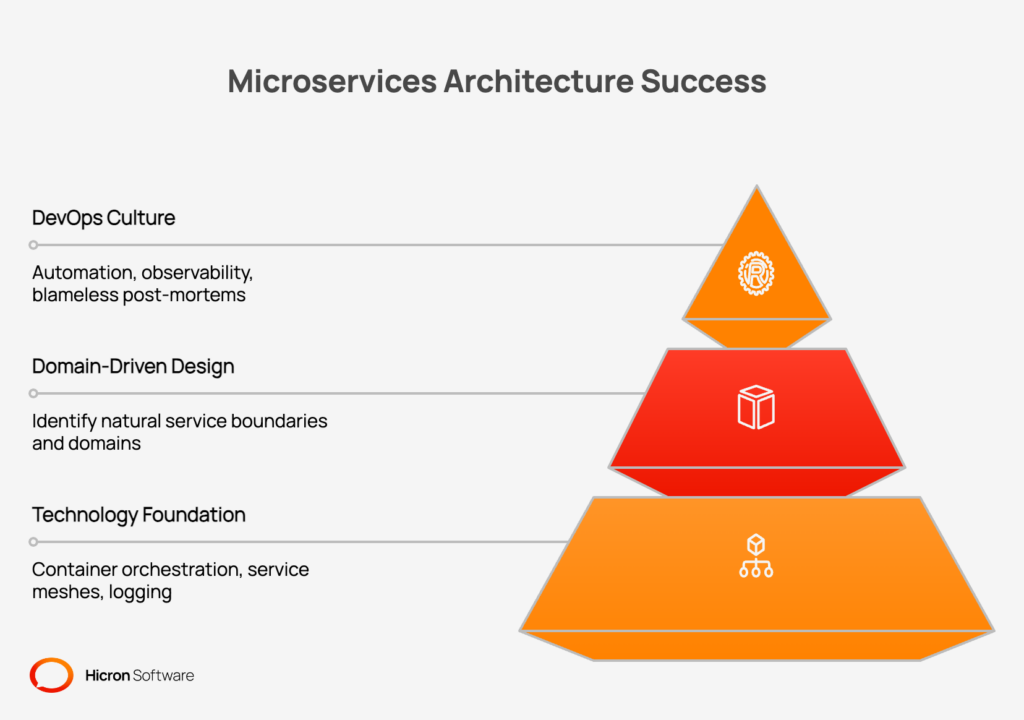
Finally, microservices are an architectural commitment that extends beyond technology. Teams must embrace DevOps practices: automation, observability, blameless post-mortems, and accept the operational complexity that comes with a distributed system. The way microservices deliver their full value is through this combination:
Since microservices place so much responsibility on individual teams, the human dimension of this architecture style is as important as the technical one.
Adopting microservices successfully requires technical rigor and operational maturity. Focus on the following best practices:
Microservices have become a foundational architecture for modern AI workloads, especially for large teams and scalable solutions. In AI-driven systems:
The advantages come with significant trade-offs. Organizations that rush into microservices without adequate preparation often find themselves managing a distributed system more complex than the monolith they left behind.
Higher Complexity
Managing distributed services introduces a new category of challenges: network latency between service calls, the need for service discovery, managing distributed configuration, and coordinating deployments across dozens or hundreds of services. What was previously a simple in-process function call becomes a network hop with all the failure modes that entails.
Data Management Challenges
One of the most underestimated challenges is maintaining data consistency across services. Each service owns its database, which means there is no single transactional boundary. Ensuring consistency, particularly for operations that span multiple services, such as placing an order that deducts inventory and charges a payment, requires careful design using patterns like the Saga pattern or event sourcing.
Testing and Debugging Difficulties
Integration testing in a microservices environment must span multiple services, each potentially running different versions. Reproducing production bugs requires orchestrating the right combination of service instances, and tracing an error across distributed logs is significantly harder than reading a single stack trace in a monolith. Tools like distributed tracing (Jaeger, OpenTelemetry) are essential but add operational complexity.
Operational Overhead
Microservices require a robust operational foundation. Teams need tools for container orchestration (Kubernetes), service discovery, centralized logging, metrics collection, and deployment pipelines. Without mature DevOps practices, the operational burden of managing dozens of independently deployable services quickly becomes unsustainable.
The decision to adopt microservices should be driven by specific organizational and technical needs, not by industry trends.
Microservices are well-suited for large-scale, high-traffic systems where different components have vastly different scaling requirements. They are a strong fit for organizations with multiple teams that need to work in parallel without blocking each other, and for products that need to evolve rapidly with frequent, independent deployments. They also shine in contexts where technology diversity is a genuine advantage. For example, AI-heavy systems where different services benefit from different frameworks.
However, there are clear scenarios where microservices should be avoided:
A useful heuristic: start with a monolith, and decompose into microservices only when specific scaling or team autonomy pain points emerge, and only when your DevOps infrastructure is mature enough to support it.
|
Scenario |
Why Avoid Microservices |
Prefer Monolith When… |
|
Simple App |
Unneeded complexity |
Rapid prototyping needed |
|
Small Team |
High ops burden |
Limited DevOps experience |
|
Data Consistency |
Hard distributed transactions |
ACID requirements critical |
|
Startup/Greenfield |
Slows initial velocity |
Time-to-market is priority |
Microservices and DevOps are inseparable. The architectural model is only sustainable with mature automation, observability, and operational tooling.
|
Practice |
Benefit for Microservices |
Key Tools |
|
Independent deploys per service |
Jenkins, GitLab CI, ArgoCD |
|
|
Containers |
Portability and consistent scaling |
Docker, Kubernetes |
|
End-to-end visibility across services |
Prometheus, Grafana, Jaeger |
|
|
Infrastructure as Code |
Reproducible, version-controlled infra |
Terraform, Pulumi |
|
Resilience Patterns |
Fault tolerance and graceful degradation |
Istio, Resilience4j |
Data consistency is arguably the hardest problem in microservices design. Because each service owns its own database, there is no shared transactional boundary, and classical ACID guarantees across services are impractical.
The pragmatic approach is to embrace eventual consistency: allow temporary inconsistencies that are resolved asynchronously through events. For most business use cases: order updates, inventory adjustments, notification triggers, eventual consistency is entirely acceptable, even if it feels counterintuitive at first.
Four patterns address distributed data consistency effectively:
Saga Pattern
Orchestrates distributed transactions as a sequence of local transactions, each publishing events that trigger the next step. When a step fails, compensating transactions roll back earlier steps. This is the primary pattern for multi-service workflows like order processing.
Event Sourcing and CQRS
Event sourcing stores state changes as an immutable log of events rather than mutable rows. CQRS (Command Query Responsibility Segregation) separates write models from read models, optimizing each for its workload. Together they provide strong auditability and high read/write throughput.
Change Data Capture (CDC)
CDC automatically propagates database changes via transaction logs to sync data across services reliably and asynchronously, without requiring services to publish events explicitly.
Microservices architecture is increasingly important for AI systems, where different components: data ingestion, model training, inference, and post-processing, have different resource requirements and update frequencies.
AI-specific microservices patterns include Model as a Service (MaaS), which exposes individual models via APIs for independent scaling; pipeline patterns that chain services for sequential tasks from data preparation through inference; and event-driven patterns for asynchronous AI tasks like real-time predictions or batch retraining.
When integrating Large Language Models (LLMs), microservices provide critical benefits:
Security for LLMs in microservices deserves special attention. The attack surface expands, with each service endpoint representing a potential injection vector. Key security practices include
The OWASP Top 10 for LLM Applications (2025 edition) is the primary compliance standard for teams running LLMs in microservices. It covers critical risks including prompt injection, insecure output handling, training data poisoning, model denial of service, and supply chain vulnerabilities. Organizations should combine OWASP guidance with the NIST AI Risk Management Framework (AI 600-1) for comprehensive AI governance.
Microservices offer genuine, powerful advantages for the right organizations: independent scalability, faster development cycles, improved resilience, and technology flexibility. But they are not universally appropriate, and their benefits only materialize when an organization has the DevOps maturity, team structure, and operational tooling to support them.
The path forward is pragmatic: start with a monolith, identify specific pain points that microservices would address, build the operational foundation before extracting the first service, and migrate incrementally using proven patterns like the Strangler Fig. Invest heavily in observability, CI/CD automation, and data consistency patterns from day one.
As AI and LLM workloads become central to modern applications, microservices will play an increasingly important role in enabling modular, scalable AI infrastructure. The organizations that master this architecture, its patterns, its pitfalls, and its operational demands, will be best positioned to build the next generation of high-performance, resilient software systems.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
