DevOps: How to Use Kubernetes Ingress for Hybrid Public Access
- January 14
- 28 min


Enterprise Kubernetes is a container orchestration platform that automates the deployment, scaling, and management of containerized applications across the entire organization. When managing multiple internal departments, administrators use multitenancy to isolate workloads securely. To understand the business value of the enterprise version, we first need to look at where the open-source foundation falls short.
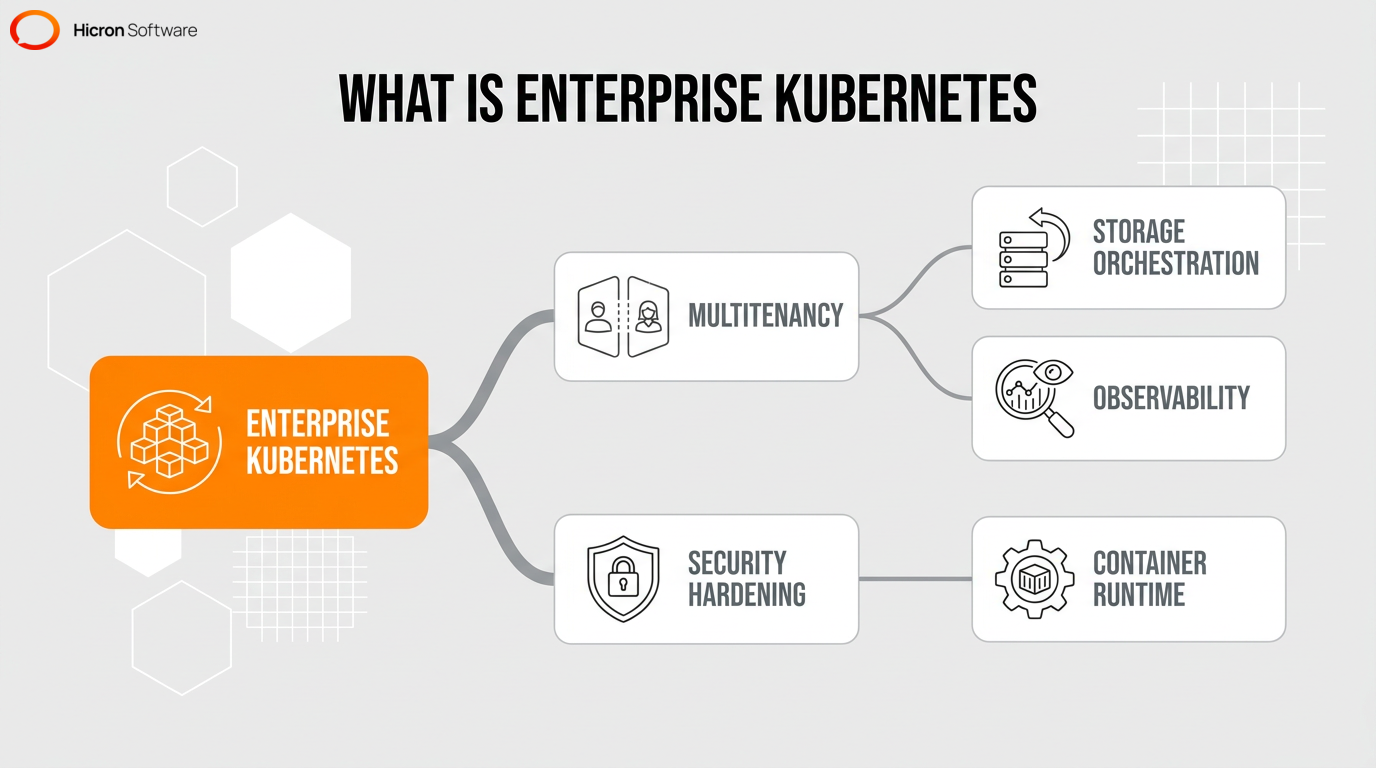
Upstream Kubernetes is community-supported open-source software that lacks native integration for large-scale production. The main shift is moving toward a vendor-supported infrastructure with enterprise-grade security hardening. Enterprise Kubernetes transforms the raw platform by embedding critical operational technologies such as:
A hardened platform actively patches security vulnerabilities found in upstream releases, which is essential for regulatory compliance. In my experience, trying to manually track and patch these vulnerabilities across a growing cluster is a fast track to burnout. This proactive approach also ensures high availability and simplifies lifecycle management. When operating complex workloads, administrators rely on continuous monitoring to track system performance.
|
Category |
Key Features & Technologies |
Business Impact & Goals |
|
Platform Foundation |
|
|
|
Security & Governance |
|
|
|
Cloud Strategy & Portability |
|
|
|
Developer Experience (DX) |
|
|
|
Advanced Workloads |
|
|
|
Adoption Challenges |
|
|
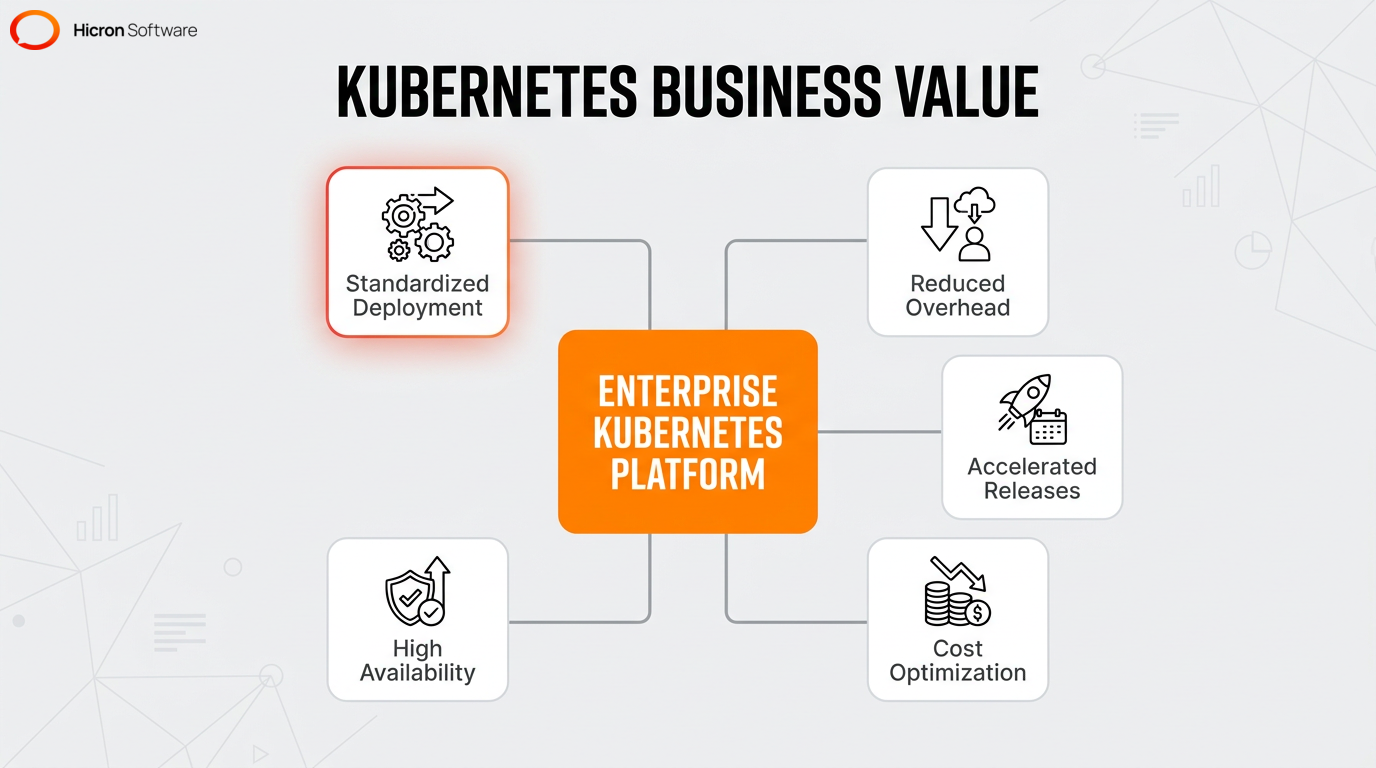
Adopting advanced container orchestration resolves the conflict between operational stability and developer speed. Enterprises typically make the switch to achieve key goals like:
By standardizing application deployment across their entire IT infrastructure, organizations minimize the resources required for production workloads, such as specialized skills, deployment time, and manual maintenance. Strategic adoption optimizes resource usage so companies don’t overspend on infrastructure. To do this, the platform adjusts computing capacity using horizontal and vertical scaling methods.
Automated deployment replaces manual configuration to maintain high availability. The system relies on a self-healing mechanism to automatically restart failed containers, which enables reliable disaster recovery during unexpected hardware failures. These capabilities mean IT can launch new products faster without breaking existing systems, ensuring the infrastructure can adapt to future growth.
Container orchestration speeds up software delivery by removing manual infrastructure bottlenecks from the developer’s daily workflow. By automating container management, companies increase business agility and innovation. Operational automation and self-service APIs also improve the developer experience (DX).
Automation and CI/CD pipelines assist with legacy application migration and new cloud-native architecture development. When a business faces dynamic market demands, automated deployment ships microservices, such as payment services and user databases, much faster, keeping services online for users through horizontal scaling and self-healing.
Container orchestration abstracts the underlying infrastructure to enable a cloud-agnostic approach. This means your applications, both stateless and stateful, aren’t tied down to specific hardware constraints.
Infrastructure as code and automated deployment make containerized applications entirely environment-agnostic. Workload portability allows the exact same microservices to execute without modification on a developer’s laptop or in a public cloud. Organizations can move resources with less friction across a hybrid cloud to optimize costs.
Container orchestration provides a unified, consistent operational environment across distinct hosting models, such as on-premises data centers and public clouds. This orchestration layer unifies private data centers and public cloud providers by standardizing application deployment. Location no longer matters. Hybrid cloud setups are the primary driver for enterprises seeking true workload portability, delivering the freedom to use any combination of local and remote infrastructure.
Multi-cluster management guarantees true cloud-agnosticism across a distributed network. By using infrastructure as code, administrators standardize system configurations to maintain operational consistency. Continuous operation is then maintained through high availability and automated disaster recovery. Even if an enterprise deploys workloads into edge computing, a centralized control plane executes consistent management policies.
Container orchestration prevents cloud vendor lock-in to achieve platform flexibility. Enterprises can design systems independent of a single public cloud provider to maintain infrastructure freedom. Using a standard upstream API rather than a proprietary extension supports a long-term cloud-agnostic strategy. Teams can deploy critical microservices, such as payment gateways and authentication services, without relying on vendor-specific tools. If you’ve ever tried to untangle a legacy application from a specific cloud provider’s proprietary ecosystem, you know exactly why this flexibility is so valuable.
Infrastructure as code ensures workload portability across a hybrid cloud, which means organizations achieve cost optimization by migrating computing resources if hosting prices increase. Multi-cluster management enforces strict compliance across multiple external infrastructure providers, such as AWS and Google Cloud.
Adopting Kubernetes at an enterprise scale isn’t easy. It requires overcoming operational complexity, defining clear governance frameworks, and getting all teams on the same page. Scaling container orchestration presents primary technical and organizational hurdles: managing administrative overhead, aligning internal teams, and maintaining operational consistency. Enterprises face ongoing administrative and maintenance costs associated with complex environments, particularly regarding multi-cluster management and continuous lifecycle management.
Regulated industries demand high levels of scalability and maturity to maintain strict compliance. Implementation requires evaluating critical security configurations:
Administrators use RBAC and multitenancy to isolate workloads securely when multiple departments share a cluster. By doing this, one department’s vulnerability won’t compromise the rest of the network.
Organizations often struggle to achieve exact cost optimization if deployments lack clear resource boundaries. Because operating a complex architecture requires advanced observability to track system health, central IT teams rely on diagnostic tools like continuous monitoring, automated log aggregation, and real-time alerts. Platform engineers must also implement reliable disaster recovery to prevent data loss during critical system failures.
If your team spends all day managing clusters, they aren’t building new features. I’ve seen too many talented engineering teams get bogged down acting as help-desk support for basic cluster requests. High operational overhead stalls infrastructure growth unless an organization implements strategic platform management. Excessive administrative costs limit the capacity to execute horizontal and vertical scaling, but strategic enterprise platforms reduce the complexity of managing raw clusters, decreasing the time required for production work.
Companies can scale a container environment without proportionally increasing IT staff by implementing engineering practices like automated deployment and infrastructure as code. Automation pipelines simplify multi-cluster management and lifecycle management to achieve exact cost optimization. To handle expanding workloads, administrators use comprehensive observability and proactive monitoring to evaluate performance.
Managing container orchestration securely at scale requires establishing a central governance team to enforce best practices, oversight, and operational guidelines. This team creates a clear framework to align technology adoption directly with strategic business goals. The central governance team enforces critical operational standards across hundreds of distributed teams: security hardening, strict compliance, and standardized access control.
Administrators implement role-based access control (RBAC) and multitenancy to isolate workloads securely when multiple internal departments share computing resources. A strong governance model simplifies multi-cluster management and continuous lifecycle management across complex environments. Governance frameworks mandate foundational deployment practices like infrastructure as code and comprehensive observability to maintain operational consistency.
A center of excellence provides the necessary strategic direction and centralized governance for secure enterprise-wide adoption. This dedicated team centralizes expertise to set clear operational rules. The governance team oversees the creation of internal platforms, a self-service portal and a shared cluster environment, to ensure they follow best practices.
Centralized oversight enforces strict compliance and strong security hardening across every organizational deployment. A dedicated Center of Excellence ensures that as the company adds more clusters, developers have a clear, secure path to deploy their code without waiting on IT bottlenecks. Standardized infrastructure improves the developer experience (DX) by integrating engineering solutions like automation pipelines and advanced observability. This structure helps teams manage lifecycles without overspending.
By abstracting infrastructure complexity, an internal developer platform provides a self-service layer. This abstraction directly enhances developer productivity and satisfaction by hiding the operational complexity of the underlying orchestration layer. Through APIs designed for operational automation, the technology improves the developer experience (DX). Platforms also integrate CI/CD pipelines to connect code commits and automated deployment.
Software engineers don’t have to worry about infrastructure; they can focus entirely on writing code when deploying modern architectures like microservices and serverless computing. If a system error occurs, automation pipelines use infrastructure as code to execute a self-healing process.
Self-service catalogs provide developers with pre-approved infrastructure templates. This eliminates IT bottlenecks and fast-tracks automated deployment. Curated marketplaces of IT services speed up the software development lifecycle, enabling software engineers to provision approved clusters independently. An internal developer platform uses these catalogs to reduce the operational burden on IT teams while maintaining strict governance standards. Providing self-service options directly lowers overall administrative overhead.
Automation and CI/CD pipelines quickly provision resources for modern architectures like microservices and serverless environments. If an organization adopts GitOps practices, a centralized catalog improves the developer experience (DX) using infrastructure as code. By centralizing these catalogs, organizations can secure access and streamline lifecycle management across distributed teams.
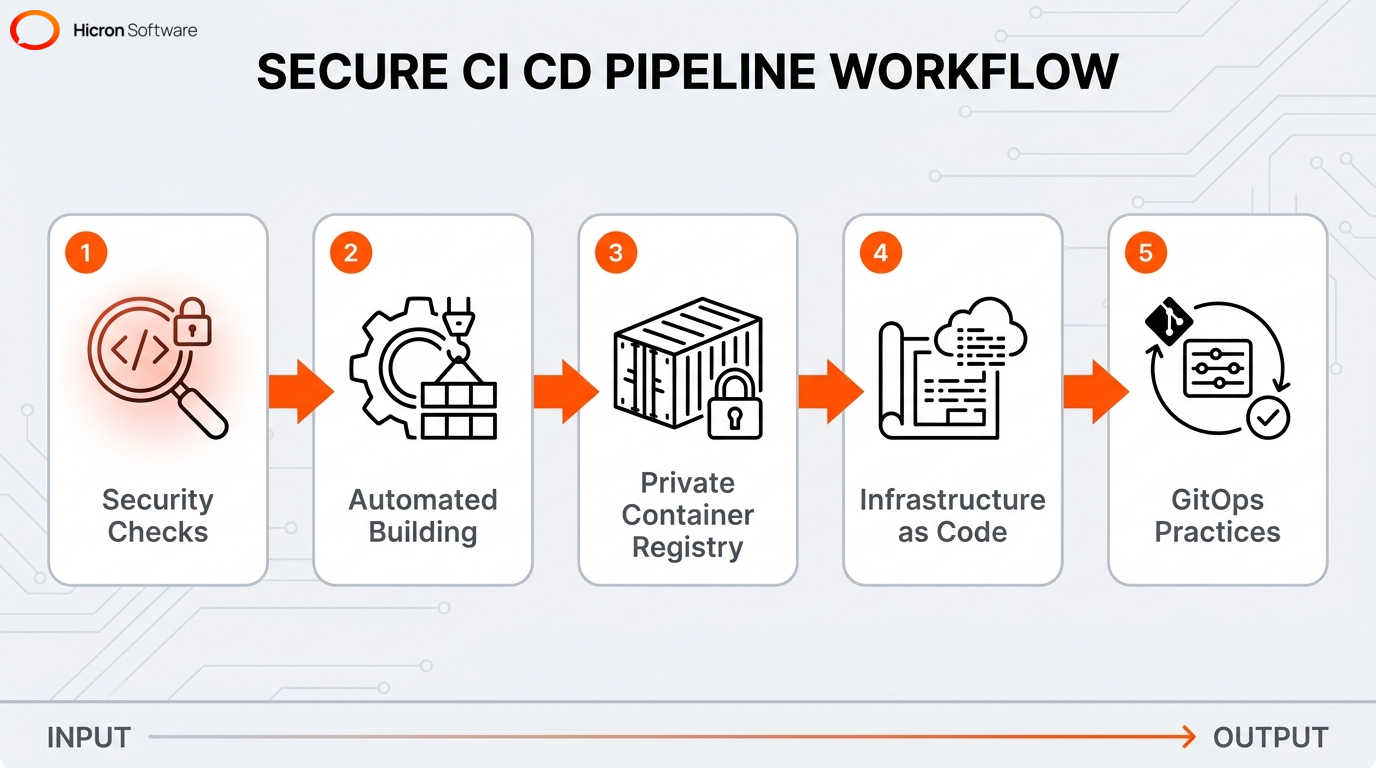
Security hardening requires a multi-layered approach to reduce vulnerability surfaces through strict configuration management, policy enforcement, and secure supply chains. Doing so ensures that deployments meet critical benchmarks like regulatory compliance and internal security standards. Securing a container orchestration environment for production involves foundational steps such as: implementing strict access controls, enforcing execution policies, establishing resource segmentation, and securing a container registry.
The container runtime serves as the foundation for essential security features: execution-policy enforcement and data encryption. By maintaining a secure runtime, organizations prevent malicious activity if an external threat targets the host system. Centralized secret management protects sensitive credentials from exposure during automated deployment. Because advanced observability tracks system behavior, it can detect anomalies early during a security breach. Implementing these foundational steps requires specific access frameworks and deployment pipelines.
You don’t want your marketing team accessing financial databases. RBAC and multitenancy prevent this by working together to isolate computing resources and enforce the principle of least privilege across a shared enterprise cluster. Organizations safely share cluster capacity among internal teams, such as development groups and financial departments, by regulating network access based on specific user roles. Security hardening involves implementing strict RBAC to ensure users only access the exact data they require. Take it from me: mapping out these access roles early on is infinitely easier than trying to retrofit them after a security audit.
Multitenancy allows distinct business units—such as a marketing division and an engineering department—to share a single platform while ensuring complete resource isolation. Administrators execute configuration management and multi-cluster management securely when a system establishes clear tenant boundaries. An enterprise platform uses network technologies to direct traffic securely: ingress controllers and a service mesh. If a regulated industry requires strict compliance, IT departments integrate centralized secret management to protect sensitive credentials.
By integrating security checks directly into the delivery process, CI/CD pipelines enforce compliance. They also automate the building, testing, and secure deployment of containerized applications. To ensure secure software supply chains, these automated pipelines pull hardened images exclusively from a private container registry.
Automated deployment contributes to maintaining a secure and compliant infrastructure by standardizing configurations using infrastructure as code. Adopting GitOps practices significantly strengthens security hardening by making infrastructure changes auditable, version-controlled, and easily reversible. Enterprises integrate operational practices like advanced observability and automated testing to streamline continuous lifecycle management.
Centralized management solutions allow enterprises to oversee, control, and enforce policies across numerous distributed clusters. Implementing a centralized control plane prevents operational chaos when an organization runs dozens or hundreds of clusters. It directly addresses the operational sprawl that occurs when scaling container orchestration across distinct environments like hybrid and public clouds. A unified platform provides a centralized view for critical administrative functions: continuous monitoring, security enforcement, and continuous lifecycle management.
Centralized management offers a way to efficiently oversee and control numerous clusters across the enterprise to guarantee high availability. Administrators use infrastructure as code to standardize configurations as deployments expand across multiple regions. To maintain system health, advanced multi-cluster management relies on diagnostic technologies: comprehensive observability and automated log aggregation. If a critical failure occurs, a consolidated operational strategy supports reliable disaster recovery.
Service discovery automatically detects and routes network traffic to distributed services to enable uninterrupted communication in multi-cluster setups. Microservices find and communicate with each other across complex networks by using this automated detection mechanism. This matters because it prevents downtime and ensures users always reach the services they need, rather than getting lost in complex external and internal traffic routing.
This ensures high availability across a hybrid cloud if a primary server fails. Load balancing distributes network requests evenly during automated deployment to prevent resource exhaustion. Maintaining a dynamic endpoint registry simplifies multi-cluster management to guarantee reliable connectivity.
Container orchestration optimizes complex workloads beyond basic web applications through advanced scheduling and scaling capabilities. Advanced computing scenarios benefit directly from an enterprise platform: AI/ML workloads, edge computing, legacy application migration, and modern software development. The orchestration layer provides the exact scheduling and resource management required for complex data processing. High-performance scheduling executes resource-intensive processing tasks efficiently when an organization analyzes large datasets.
The system adjusts computing capacity automatically using scaling methods like horizontal scaling and vertical scaling. By dynamically allocating resources, the system guarantees high availability for demanding data science applications. To support both legacy application migration and modern development simultaneously, the platform provides structured frameworks. Companies modernize their infrastructure by adopting cloud-native patterns like microservices and serverless computing.
When an enterprise deploys edge computing, the technology extends centralized management policies outward to remote physical locations, handling these diverse requirements through specialized resource allocation and architecture management.
Container orchestration has become the standard infrastructure for data science and machine learning because it provides the rapid horizontal scaling and advanced resource management necessary for massive data processing tasks. Artificial Intelligence workloads demand dynamic resource allocation to handle fluctuating application traffic without manual intervention. The system efficiently allocates specialized hardware resources like GPUs and TPUs across distributed processing jobs. Given the current cost and scarcity of these components, ensuring they are fully utilized rather than sitting idle is a massive win for any engineering budget. As a result, data models can execute intensive demands without crashing.
Enterprises use automated deployment to provision AI/ML workloads across complex environments like centralized data centers and edge computing. To track algorithm performance, administrators rely on observability and continuous monitoring. If a machine learning task requires larger memory capacities, advanced storage orchestration maintains persistent data access during vertical scaling.
Container orchestration differentiates computing workloads by smoothly scaling stateless applications while using advanced storage orchestration to ensure data persistence for stateful applications, such as web portals and relational databases. The platform manages stateless services through automated deployment and self-healing to maintain high availability if a server fails. It relies on horizontal scaling to distribute network traffic across ephemeral resources like web APIs and frontend interfaces.
On the other hand, the system requires integration with external storage tools to make a stateful workload production-ready: cloud volumes and distributed file systems. Integrating these external solutions manages the lifecycle of persistent data to guarantee reliable disaster recovery during hardware malfunctions. Centralized lifecycle management ensures continuous operation for data-intensive services like user registries and financial ledgers.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
