June 12
8 min



Securing an API isn’t about a single tool or a simple checklist—it’s a discipline built on defense-in-depth. A solid architecture anticipates threats at every layer, from the first access request all the way to data storage. This means establishing tight controls over who can access the API and shielding data from eavesdroppers with solid encryption. You also need to block threats with strict input validation and keep a close watch through continuous monitoring.
Encryption isn’t optional; you need modern SSL/TLS protocols (TLS 1.2+) for data in transit and strong algorithms like AES-256 for data at rest. You must validate all incoming data against a predefined schema to shut down common attacks, and use aggressive rate limiting and throttling to fend off denial-of-service (DoS) attempts. Security is a continuous process that demands thorough logging and monitoring to spot suspicious activity and stay compliant with standards like GDPR, HIPAA, PCI DSS, and SOC 2.
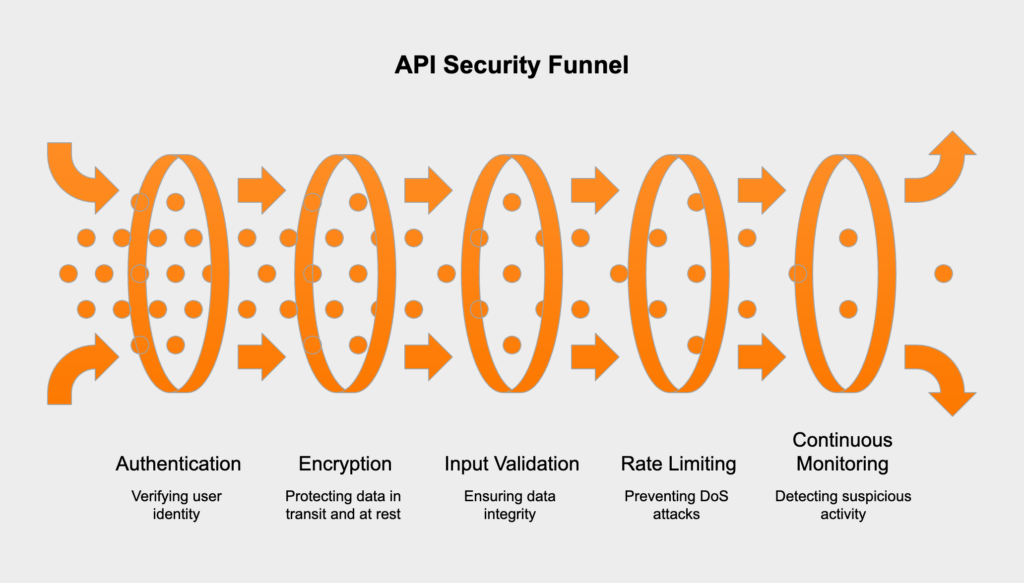
Your first line of defense is making sure every single request comes from a legitimate, verified source. Authentication answers the question “Who are you?” while authorization answers “What are you allowed to do?” To get this right, you should always stick to proven, industry-standard protocols.
It’s also critical to manage API keys and tokens carefully. Have a clear process in place to revoke them immediately if you even suspect a compromise.
Scalability is all about how well your API handles a growing amount of traffic without degrading performance or falling over. You don’t get there just by throwing more servers at the problem; it’s the result of intentional design choices that prioritize efficiency and resilience. Getting these principles right means your system can grow smoothly as your user base and traffic expand.
Statelessness is a fundamental principle of scalable API design, especially for REST. In a stateless system, every single request from a client contains all the information the server needs to process it. The server holds no memory of past requests, which makes load balancing dramatically simpler because any server can handle any request. This works hand-in-hand with loose coupling, where you minimize the dependencies between your API and its backend services so they can be scaled, updated, or replaced independently.
Some tasks are just too slow to handle in a single, synchronous API call. Think about generating a big report or processing a large file upload—trying to do that synchronously will tie up server resources and probably time out. Asynchronous processing is the solution. It offloads these heavy jobs to background workers, freeing up your API to handle other requests. Message queues like RabbitMQ or AWS SQS are perfect for this, acting as a buffer that smooths out traffic spikes and makes your system more resilient by ensuring jobs aren’t lost if a worker fails.
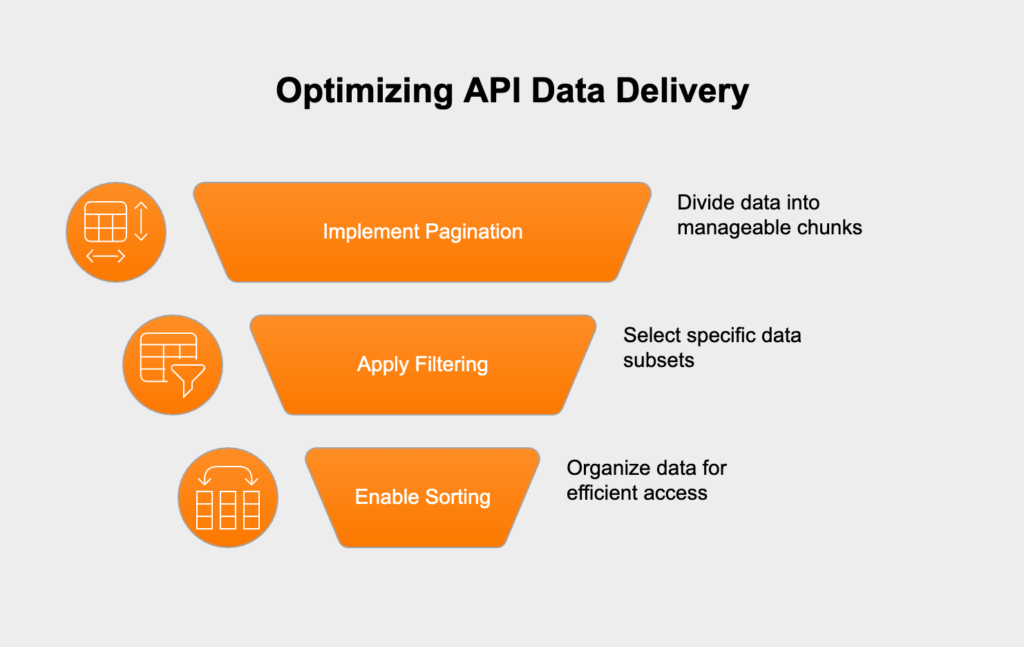
Endpoints that can return huge collections of data are a serious performance risk. Dumping thousands of records in one response can overload your server, clog the network, and even crash the client’s application. Server-side pagination is the standard fix, letting clients request data in smaller, manageable chunks. When you pair this with good filtering and sorting options, you give clients the ability to ask for only the data they actually need, which shrinks payloads and speeds up responses.
APIs always evolve. Business needs change, you find better ways to do things, and you’ll inevitably have to modify endpoints, alter data structures, or retire old features. You need a clear API versioning strategy to manage these changes without breaking existing client applications. Common methods include putting the version in the URL path (like `/api/v2/users`) or in a custom request header. This lets you roll out new features while giving older clients a stable endpoint to use, backed by a clear timeline for when they’ll need to upgrade.
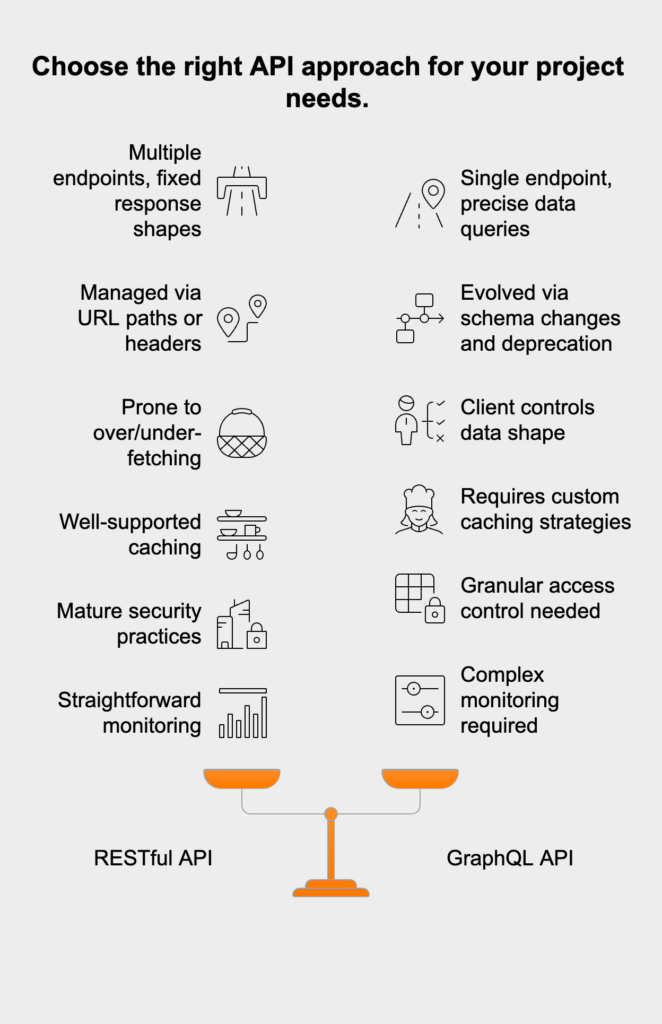
REST and GraphQL are two popular, but very different, ways to build APIs. REST is an architectural style that revolves around resources and standard HTTP methods. GraphQL, on the other hand, is a query language that gives the client total control over exactly what data it gets back. Understanding this difference helps you pick the right tool for your project.
When it comes to security, REST APIs benefit from a mature ecosystem of tools designed to lock down individual endpoints. GraphQL, however, needs a more granular security model. Since every request hits a single endpoint, you have to enforce security rules deep inside your resolver logic for each field.
One of the biggest risks with GraphQL is a denial-of-service attack using an overly complex query. You have to guard against this by analyzing queries for depth, complexity, and recursion before you run them. Which integration patterns improve security and scalability? Once you’re managing dozens or even hundreds of APIs, things can get chaotic. This is where architectural integration patterns come in, offering proven solutions to restore order and boost both security and scalability.
An API gateway acts as a single front door for all clients, letting you centralize tasks like authentication, rate limiting, and logging. To create tailored user experiences, the Backend for Frontend (BFF) pattern gives each client type (like web or mobile) its own dedicated backend to aggregate and shape data perfectly. For communication between your internal microservices, a service mesh provides a dedicated infrastructure layer to handle secure, reliable communication. It manages critical tasks like service discovery, load balancing, and mutual TLS encryption.
| Feature | RESTful API | GraphQL API |
|---|---|---|
| Data Fetching | Multiple endpoints, fixed response shapes | Single endpoint, precise data queries |
| Versioning | Managed via URL paths or headers | Evolved via schema changes and deprecation |
| Over/Under-fetching | Prone to both, mitigated by endpoint design | Client controls data shape, reducing over-fetching |
| Caching | Well-supported (HTTP caching, ETags, etc.) | Requires custom caching strategies |
| Security | Mature best practices, many middleware options | Needs granular access control per query field |
| Monitoring | Straightforward with standard logs per route | More complex, as queries can be highly dynamic |
When it comes to security, REST APIs benefit from a mature ecosystem of tools designed to lock down individual endpoints. GraphQL, however, needs a more granular security model. Since every request hits a single endpoint, you have to enforce security rules deep inside your resolver logic for each field. One of the biggest risks with GraphQL is a denial-of-service attack using an overly complex query. You have to guard against this by analyzing queries for depth, complexity, and recursion before you run them.
Once you’re managing dozens or even hundreds of APIs, things can get chaotic. This is where architectural integration patterns come in, offering proven solutions to restore order and boost both security and scalability. An API gateway acts as a single front door for all clients, letting you centralize tasks like authentication, rate limiting, and logging. To create tailored user experiences, the Backend for Frontend (BFF) pattern gives each client type (like web or mobile) its own dedicated backend to aggregate and shape data perfectly. For communication between your internal microservices, a service mesh provides a dedicated infrastructure layer to handle secure, reliable communication. It manages critical tasks like service discovery, load balancing, and mutual TLS encryption.
Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
