
6 Solutions for Cloud Migration Strategies You Should Know
- March 27
- 21 min



The presented here solution and links to our GitHub repository are the authorship of our Lead DevOps Engineer – Kamil Piwowarski. Feel invited to explore a feasible approach to optimizing costs associated with Azure cloud computing.
Cloud cost optimization is an important part of maximizing the value of your cloud investment. By leveraging dynamic pricing models and tailoring solutions, enterprises can take advantage of lower overall costs and improved resource utilization, while reducing their risk of overspending. Through smart approaches, businesses can optimize the amount they spend on cloud computing resources and get the best for their infrastructures with Azure.
In today’s rapidly-evolving technological landscape, businesses are seeking to leverage the power of Continuous Integration/Continuous Deployment (CI/CD) environments to accelerate their software development processes. To that end, it is crucial to tailor the CI/CD environment to the unique requirements of each organization.
At Hicron Software, we firmly believe that anything is possible in the IT world, and we approach each client with the goal of creating solutions that meet their specific needs. Since the challenge is probably a universally common one, we decided to share our expertise. We were tasked with addressing a challenge that had been plaguing multiple stakeholders: how to release multiple components at the same time in a particular month without causing delays or errors in the build process.
The specific requirements:
Investigation: There exists a plethora of alternatives at our disposal to accomplish our objective. One potential approach involves the creation of a Virtual Machine Scale Set, which can be scaled through the utilization of an external Azure DevOps (ADO) pipeline, utilizing tools such as Terraform. All we require is a specialized virtual machine image, which consolidates everything we need, effectively saving us an enormous amount of time.
Nevertheless, an even more intriguing and fitting alternative involves locating a solution that can scale our system based on the essential Azure DevOps pipeline queue. This alternative is highly appealing, as it aligns well with our requirements. Additional detailed exposition, together with a higher semantic richness, is necessary to fully expound on this proposition.
This is a basic overview of what we would like to achieve here. There are many different options and extensions that could be added here but let’s focus on the main functionality of this test.
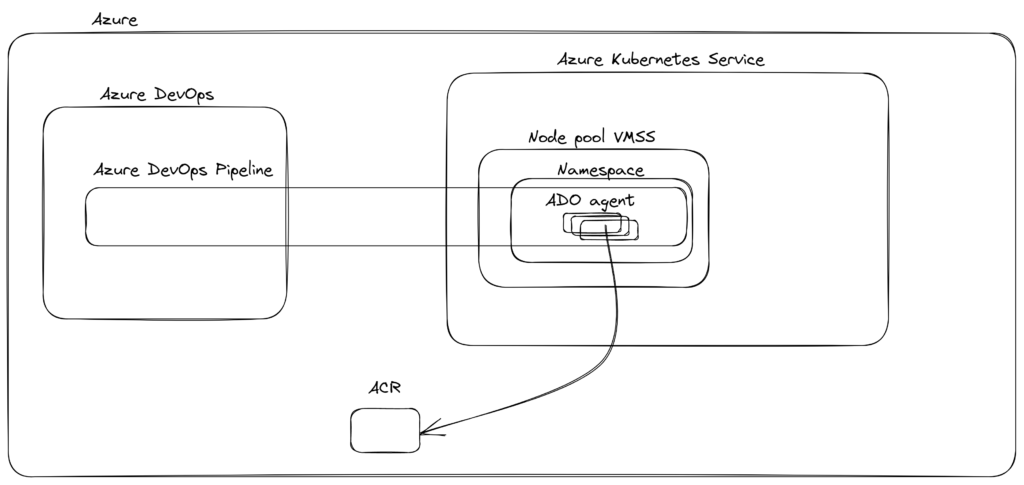
You can see in the previous step the solution which gives us great benefits:
When I was digging into the existing solution for this scenario and decided to prepare my own feature I found a solution from Keda, see here. This is exactly what we are looking for. It would be like a dream if they have a Helm chart for this, here we go.
We are not focusing on the best practices for AKS deployment, we would like to have a minimal impact on an additional configuration to give you a clear insight into this solution.
What do you need on your local machine:
#1
The first thing in our infrastructure is Azure Kubernetes Service. We already prepared minimal configuration for this including autoscaling:
resource "azurerm_kubernetes_cluster" "ado-aks" {...
default_node_pool {
name = "default"
type = "VirtualMachineScaleSets"
enable_auto_scaling = true
node_count = 1
max_count = 3
min_count = 1
vm_size = "Standard_D2_v2"
}
...
}We need to also have a Docker registry to be able to push created image for the Azure DevOps agent pool.
resource "azurerm_container_registry" "acr" {
name = "acradoagents"
resource_group_name = azurerm_resource_group.rg.name
location = "westeurope"
sku = "Basic"
admin_enabled = true
}The full structure and code you can find on our GitHub here
I suggested Make as a required tool for this test because I use it all the time.
deploy-aks:
@terraform -chdir=./terraform init
@terraform -chdir=./terraform apply -auto-approve→ I assume you properly configured access to your Azure subscription if not then take a look at this. ←
#2
Let’s create our infrastructure!
make deploy-aks
Initializing the backend...
Initializing provider plugins...
- Reusing previous version of hashicorp/azurerm from the dependency lock file
- Reusing previous version of hashicorp/local from the dependency lock file
- Using previously-installed hashicorp/azurerm v3.46.0
- Using previously-installed hashicorp/local v2.3.0
Terraform has been successfully initialized!
...
azurerm_kubernetes_cluster.ado-aks: Creation complete after 4m17s [id=/subscriptions/bb5c4b94-9eb2-4816-8988-549529465de9/resourceGroups/rg-poc-ado-dynamic-agents/providers/Microsoft.ContainerService/managedClusters/aks-ado-agents]
local_file.kubeconfig: Creating...
azurerm_role_assignment.acr_pull: Creating...
local_file.kubeconfig: Creation complete after 0s [id=e3b11fc52a9f783567490133d64c26ec9837c725]
azurerm_role_assignment.acr_pull: Still creating... [10s elapsed]
azurerm_role_assignment.acr_pull: Still creating... [20s elapsed]
azurerm_role_assignment.acr_pull: Creation complete after 30s [id=/subscriptions/bb5c4b94-9eb2-4816-8988-549529465de9/resourceGroups/rg-poc-ado-dynamic-agents/providers/Microsoft.ContainerRegistry/registries/acradoagents/providers/Microsoft.Authorization/roleAssignments/a09bbba0-d07d-9777-a38a-cbcd8a219531]
Apply complete! Resources: 5 added, 0 changed, 0 destroyed.
Outputs:
acr_pass =
acr_url = "acradoagents.azurecr.io"
acr_user =
kubernetes_cluster_name = "aks-ado-agents"
resource_group_name = "rg-poc-ado-dynamic-agents"Let's see if Azure Kubernetes Service (AKS) is reachable from my machine:

To visualize all in one place I decided to deploy also kube-prometheus-stack using the Helm tool which is obvious. Makefile part for this one:
deploy-prom-stack:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm --kubeconfig ./terraform/kubeconfig upgrade --install kube-prometheus-stack prometheus-community/kube-prometheus-stack --wait --version 45.7.1 --namespace kube-prometheus-stack --create-namespace --set grafana.defaultDashboardsEnabled=falseThe result:
It is a good point to write something about KEDA’s solution.
One specific use case for KEDA and Azure DevOps is agent deployment. In order to deploy agents to Kubernetes clusters, developers can use KEDA to create custom scaling triggers that can automatically scale up or down based on specific events. This can include events such as changes in workload demand, application failures, or other custom triggers.
Using KEDA and Azure DevOps together for agent deployment provides a number of benefits. Firstly, it allows for the automatic scaling of agent instances based on the workload demand, ensuring that the right number of instances are available at all times. This can help to optimize resource utilization and reduce costs.
Secondly, KEDA and Azure DevOps allow for streamlined management of the agent deployment process. Developers can use Azure DevOps to manage the deployment pipeline and configure Kubernetes clusters, while KEDA provides powerful scaling capabilities to ensure that the right number of agent instances are available at all times.
Based on the Helm chart provided by KEDA we can deploy also this solution on our cluster, short Makefile section:
deploy-keda:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm --kubeconfig ./terraform/kubeconfig upgrade --install keda kedacore/keda --wait --version 2.9.4 --namespace keda --create-namespaceThe result:
To summarize, we have an Azure Kubernetes Service (AKS) cluster, monitoring, and KEDA solution ready to scale something. We need to prepare the Azure DevOps agent Docker image. It will not be such a big case because Microsoft describes it pretty well here. I gathered all here, on our GitHub. This is the least approach because we actually need a couple of official tools to execute our basic Azure DevOps pipeline.
Dockerfile
FROM ubuntu:20.04
RUN DEBIAN_FRONTEND=noninteractive apt-get update
RUN DEBIAN_FRONTEND=noninteractive apt-get upgrade -y
RUN DEBIAN_FRONTEND=noninteractive apt-get install -y -qq --no-install-recommends
apt-transport-https
apt-utils
ca-certificates
curl
git
iputils-ping
jq
lsb-release
software-properties-common
RUN curl -sL https://aka.ms/InstallAzureCLIDeb | bash
# Can be 'linux-x64', 'linux-arm64', 'linux-arm', 'rhel.6-x64'.
ENV TARGETARCH=linux-x64
WORKDIR /azp
COPY ./start.sh .
RUN chmod +x start.sh
ENTRYPOINT [ "./start.sh" ]As you probably guessed, I also have a Make command for this:
ADO_AGENT_IMAGE := poc/adoagent:1.0
create-ado-agent-image:
docker build -t "$(shell terraform -chdir=./terraform output -raw acr_url)/$(ADO_AGENT_IMAGE)" ./agent/docker/base/
@docker login
$(shell terraform -chdir=./terraform output -raw acr_url)
-u $(shell terraform -chdir=./terraform output -raw acr_user)
-p $(shell terraform -chdir=./terraform output -raw acr_pass)
docker push "$(shell terraform -chdir=./terraform output -raw acr_url)/$(ADO_AGENT_IMAGE)"You can see the full process from building to pushing to my fresh Azure Container Registry. Simple, right?
This is the moment when I have all components in the right place to create Deployment and connect Agent to my agent pool on Azure DevOps.
To simplify all as much as I can I created a simple Helm chart for this deployment and you can explore it here. This could be a universal chart for your thousand types of Azure DevOps agents. All Helm charts need the input values and you can find an example here for a specific pool.
azure:
url: https://dev.azure.com/
b64token: agent:
name: "aks-ado-default-aks-scaled"
pool:
name: "aks-ado-default"All the information you should get from the Azure DevOps pipeline.

Based on those values I am able to create a KEDA job for the Azure DevOps agents pool. The Makefile part:
deploy-ado-agent-job:
helm --kubeconfig ./terraform/kubeconfig upgrade --install --wait --namespace ado-agent-default --create-namespace
ado-default-agent ./agent/chart/ado-agent
-f ./agent/pool/values.yaml
--set image.repository="$(shell terraform -chdir=./terraform output -raw acr_url)/$(ADO_AGENT_IMAGE)"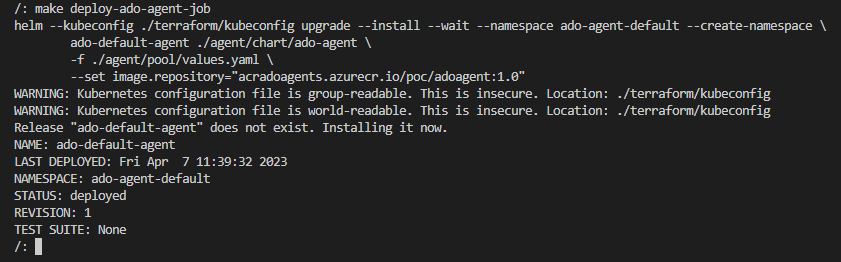
Status of the first Agent:

I also check the connection from Azure DevOps:

I configured kube-prometheus-stack so I want to use it for this test. I made a Grafana dashboard and you can find it here.
Let’s add it to my stack:
add-grafana-dashboard:
kubectl --kubeconfig ./terraform/kubeconfig apply -f dashboard/cluster-scale-overview.yaml
I did not specify how I can get the Grafana endpoint but there is a simple answer for this: I use port forwarding from Kubectl.
expose-grafana:
kubectl --kubeconfig ./terraform/kubeconfig -n kube-prometheus-stack port-forward service/kube-prometheus-stack-grafana 65480:80
Two words about the default deployment of kube-prometheus-stack:
username: admin
password: prom-operator
The dashboard section should display only one dashboard for you.
Now we can see all in one picture:
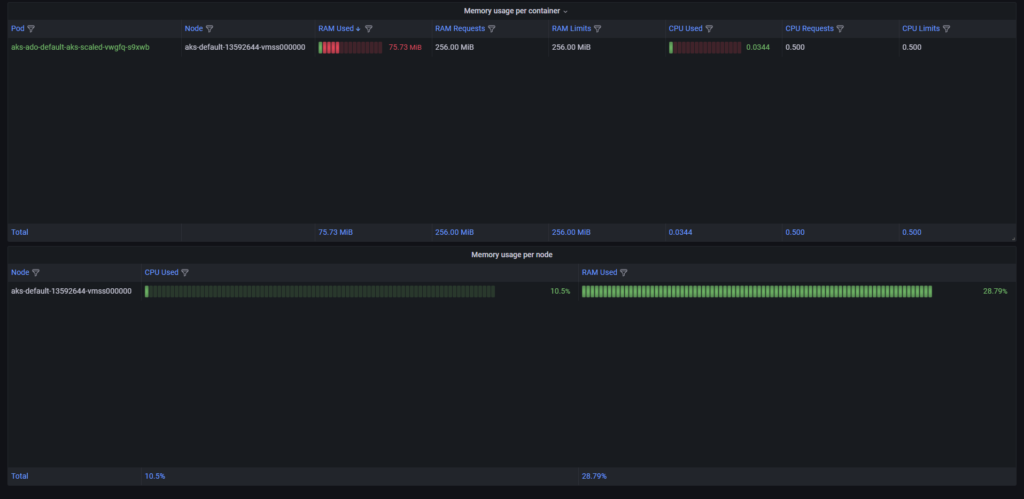
→ The name of the Pods will be changed. KEDA’s solution constantly checks if a specific Pod has something to do if not then kills it but because of the Scale job configuration where we have minReplicaCount set to 1 the new fresh Pod always has to be there. ←
All that I wanted to prepare is up and running so I should create a pipeline for this and start testing!
See the example pipeline here. You can create in Azure DevOps such.
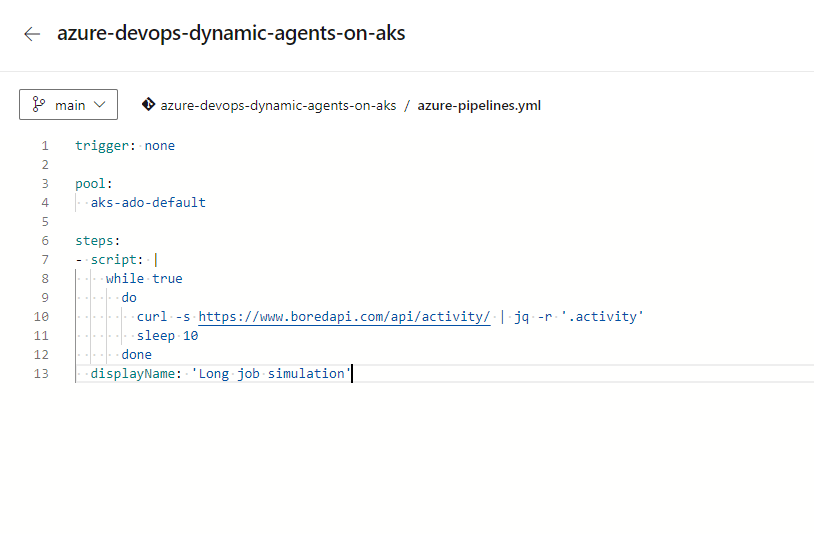
I will run three times the same pipeline and observe using Grafana.
The first one:
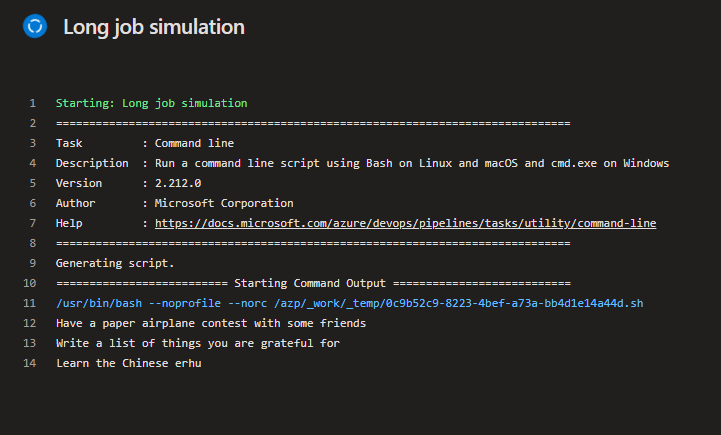
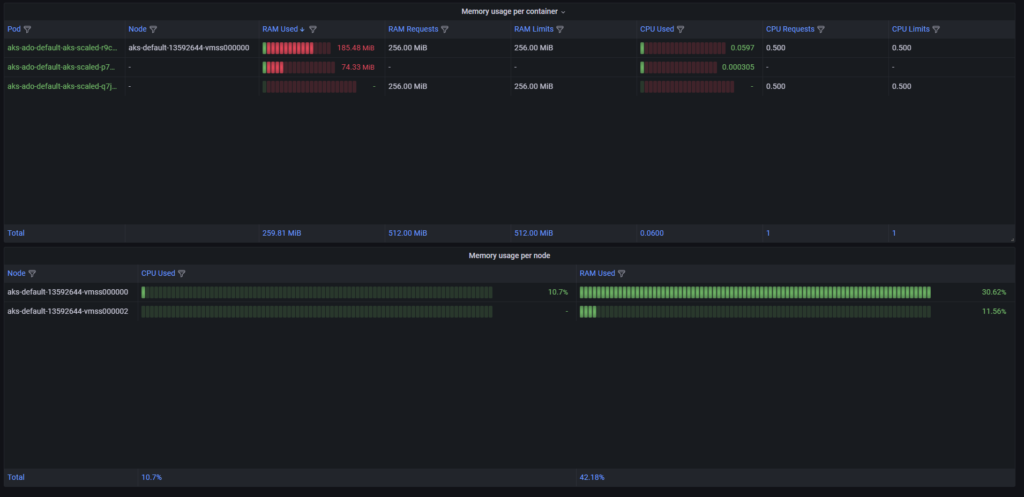
Why do I not have to create high consumption CPU or memory job? Because it is enough to set the limit for Kubernetes deployment and Azure does the rest for me with the autoscaling approach. Explore here.
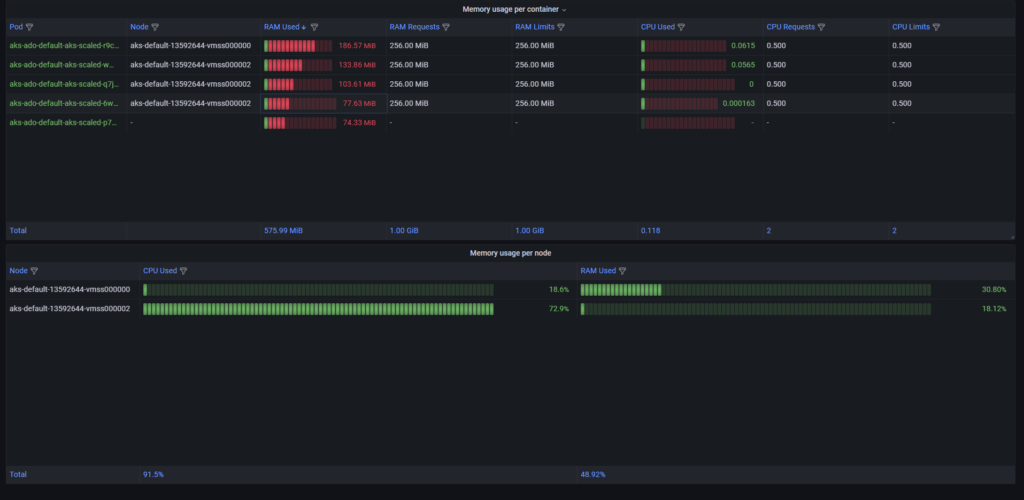
My builds need at least three nodes to do all so as you can see it is achievable.
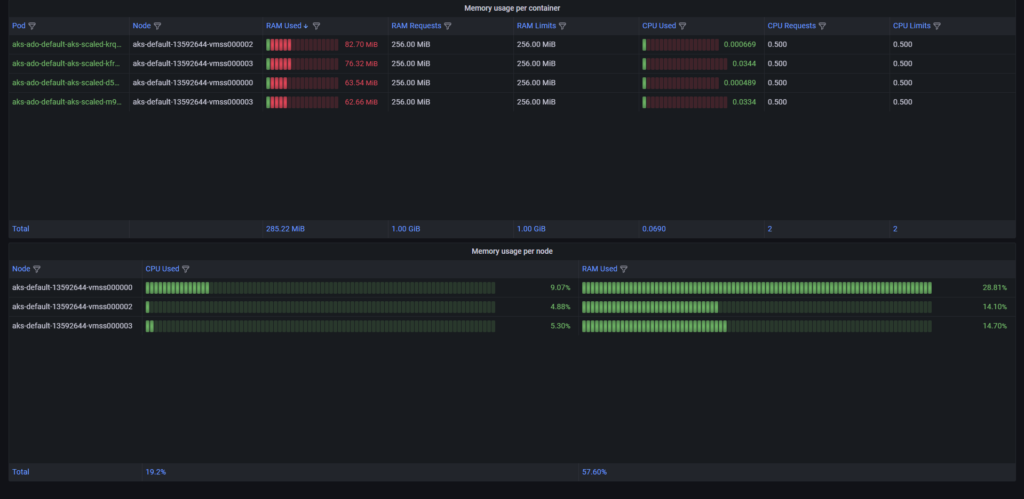
As you can see, I created a fine dynamic DevOps environment. See what will happen when we stop all builds.
Out Scale job has a configuration of how long it should wait until destroy agent which does not do anything activeDeadlineSeconds and in our scenario, it is set to 10 minutes. After this time all started to scale down:
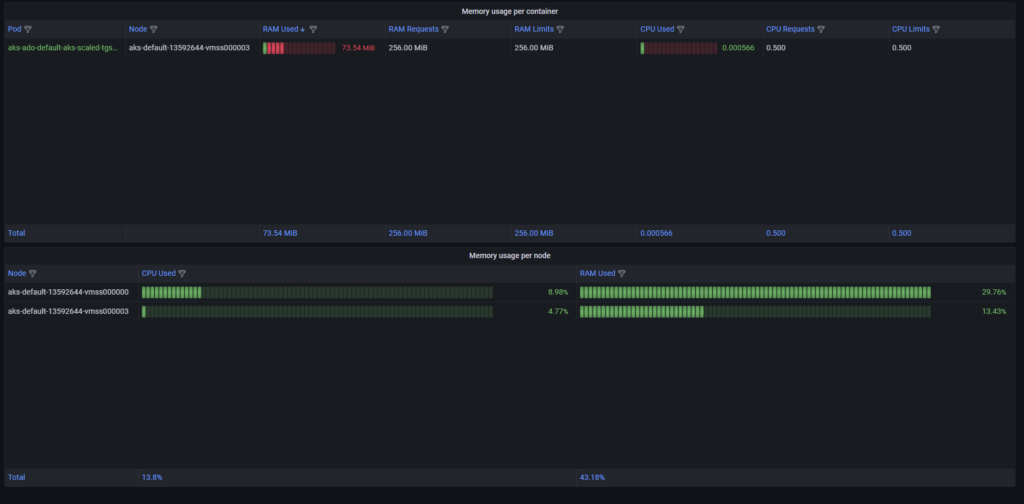
… and we are in the initial state:
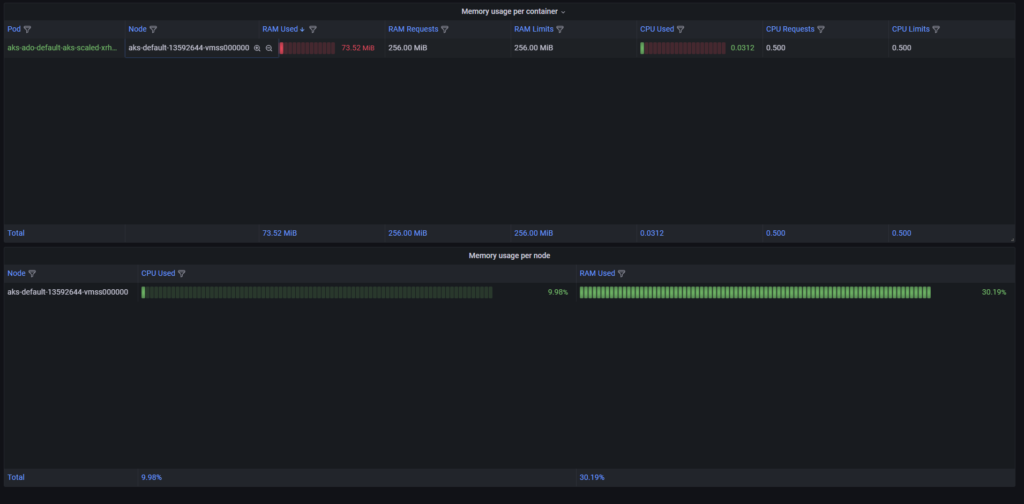
I would like to clean all at the end.
destroy-all:
@terraform -chdir=./terraform destroy -auto-approve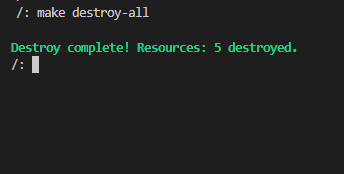
The repository of this solution can be found on our GitHub here.
The article discusses how to use Azure DevOps with AKS KEDA autoscale for Azure DevOps agents to implement an efficient and cost-effective approach to autoscaling Azure Kubernetes Service (AKS).
By using AKS KEDA autoscale, users can automatically scale the number of Azure DevOps agents in their AKS cluster based on workload demand, which helps to save time and money by reducing the need for manual scaling and minimizing idle resources.
The article explains how Azure Kubernetes Service (AKS) auto-scaling approach works, and provides some practical advice on how to implement it effectively. This content provides useful insights for anyone looking to optimize their Azure DevOps deployment and save resources.
One approach for building Docker images per Azure DevOps agent requirements is to use a multi-stage Dockerfile. This involves creating a Dockerfile with multiple stages, where each stage represents a different step in the build process. The first stage of the Dockerfile typically includes the necessary build tools and dependencies required for the application, while the subsequent stages include the application code and any additional dependencies.
To build the Docker image per Azure DevOps agent requirements, the Dockerfile can be customized based on the agent pool that the agent belongs to. For example, if an agent requires a specific version of a programming language or framework, the Dockerfile can be modified to include the necessary dependencies for that version.
To implement this approach in Azure DevOps, users can create a build pipeline that includes a Docker build task with a reference to the Dockerfile. The pipeline can be configured to use different Dockerfiles or Docker build arguments based on the agent pool that the agent belongs to, which enables the creation of agent-specific Docker images.
By building Docker images per Azure DevOps agent requirements, users can ensure that the necessary dependencies and tools are included in the Docker image, improving the application’s performance and stability. Additionally, this approach can help to simplify the deployment process by ensuring that the application runs consistently across different agent pools.
Want to learn more about custom solutions for your organization, cost optimization, and performance? Contact us and subscribe to our newsletter to stay updated with our publications.
About the author:
Kamil began his IT journey in 2011, when from the very start he dealt with automation and testing of on-premises infrastructure solutions. With the emergence of public cloud solutions like Azure and AWS, he continues his adventure in building best practices for high-performance infrastructure. His passion lies in operating solutions based on Kubernetes technology, which he specializes in the most in the context of both public and private clouds. He strongly supports the approach to functional testing of infrastructure and security in the solutions he delivers.
Hicron Software proved to be a trusted partner with unmatched technical expertise, delivering a scalable and user-friendly web application that was pivotal to our successful U.S. market expansion.

Hicron’s contributions have been vital in making our product ready for commercialization. Their commitment to excellence, innovative solutions, and flexible approach were key factors in our successful collaboration.
I wholeheartedly recommend Hicron to any organization seeking a strategic long-term partnership, reliable and skilled partner for their technological needs.

After carefully evaluating suppliers, we decided to try a new approach and start working with a near-shore software house. Cooperation with Hicron Software House was something different, and it turned out to be a great success that brought added value to our company.
With HICRON’s creative ideas and fresh perspective, we reached a new level of our core platform and achieved our business goals.
Many thanks for what you did so far; we are looking forward to more in future!
Hicron is a partner who has provided excellent software development services. Their talented software engineers have a strong focus on collaboration and quality. They have helped us in achieving our goals across our cloud platforms at a good pace, without compromising on the quality of our services. Our partnership is professional and solution-focused!

The IT system supporting the work of retail outlets is the foundation of our business. The ability to optimize and adapt it to the needs of all entities in the PSA Group is of strategic importance and we consider it a step into the future. This project is a huge challenge: not only for us in terms of organization, but also for our partners – including Hicron – in terms of adapting the system to the needs and business models of PSA. Cooperation with Hicron consultants, taking into account their competences in the field of programming and processes specific to the automotive sector, gave us many reasons to be satisfied.
